
Es ist an der Zeit, die beste serverlose Datenbankoption auszuwählen, die am besten zu Ihrer modernen Anwendung passt.
Serverless Database wurde speziell entwickelt, um unvorhersehbare Arbeitslasten zu bewältigen, die sich schnell ändern können. Infolgedessen haben viele Unternehmen die serverlose Architektur eingeführt, um moderne ereignisgesteuerte Architekturen zu erstellen. Dies hat zu einer zunehmenden Popularität innerhalb des Ökosystems serverloser Technologien geführt.
Inhaltsverzeichnis
Einführung in die serverlose Datenbank
Serverless Computing erfordert eine serverlose Datenbank. Diese Datenbanken sind speziell darauf ausgelegt, unvorhersehbare Workloads zu bewältigen, die sich schnell ändern können. Was ist mehr?
Sie zahlen nur für die Datenbankressourcen, die Sie pro Sekunde nutzen. Darüber hinaus können Cloud-Datenbanken wie Amazon Aurora, die mit MySQL und PostgreSQL kompatibel sind, vollständig verwaltet und auf bis zu 64 TB skaliert werden.
Diese Datenbank kann durch Auswahl der Instanzgröße erstellt werden. Dies funktioniert gut, wenn es eine vorhersehbare Arbeitslast, Anforderungsrate und Verarbeitungsanforderungen gibt.
Es kann schwierig sein, die richtige Menge an Kapazität zu organisieren, wenn die Arbeitsbelastung unvorhersehbar ist und ein hohes Volumen an Anfragen für nur wenige Minuten pro Woche oder an einem Tag vorliegt. Es ist jedoch möglicherweise nicht die beste Option, kontinuierlich dafür zu bezahlen.
Hier kommt die serverlose Datenbank ins Spiel.
Funktionen für serverlose Datenbanken
Hier sind die Hauptmerkmale von serverlosen Datenbanken:
- Echtzeitzugriff: Der Zugriff auf Ihre Daten ist auf feiner Ebene möglich. Es indiziert die Daten automatisch und stellt sie sofort zur Verfügung. Auf diese Weise können Sie Ihre serverlose Datenbank ständig abfragen, lesen, aktualisieren und Elemente hinzufügen. Was ist mehr? Sie können sofort über Funktionen darauf zugreifen.
- Unbegrenzte Skalierbarkeit: Sie können serverlose Datenbanken jederzeit hoch- oder herunterskalieren. Sie werden gemäß den Anforderungen der Anwendung gestartet und heruntergefahren. Es skaliert die Recheneinheiten (ACUs im Fall von Aurora Serverless), um Ihre Abfragen zu verarbeiten, zu lesen und in denselben Datencluster zu schreiben. Diese Automatisierung ermöglicht es Ihnen, alle Ihre Funktionen gleichzeitig auszuführen und sicherzustellen, dass Ihre Daten konsistent bleiben.
- Hohe Sicherheit: Moderne Anwendungen können auf globaler Ebene böswilligen und nicht vertrauenswürdigen Zielgruppen ausgesetzt werden. Es stellt sicher, dass jede Anwendung, die mit derselben Datenbank interagiert, dasselbe Zugriffskontrollprotokoll durchläuft. Es reduziert die Angriffsfläche, die ein entscheidendes Risiko für Unternehmen darstellt.
- Verfügbarkeit: Die serverlose Datenbank bietet Ihnen die Möglichkeit, die Latenz zu reduzieren. Dieser Ansatz ermöglicht es, dass Daten aus ereignisgesteuerten Funktionen direkt vom Benutzer gelesen werden.
- Schemalos: Mit Schemalos können Sie alle Datenausgaben Ihrer Funktionen verarbeiten. Mit diesem „Handle Everything“-Ansatz ist es einfach, die serverlose Datenbank in Ihre Funktionen zu integrieren. Dies ist eine einzigartige Funktion in serverlosen Datenbanken.
Sehen wir uns nun einige der besten serverlosen Datenbanken für moderne Anwendungen an.
Fauna
Fauna ist eine verteilte, serverlose Datenbank. Fauna bietet extreme Flexibilität. Sie können mehrere Parameter an die Anforderungen Ihres Projekts anpassen. Fauna kann als Schlüsselwert-, Diagramm-, dokumentenbasierte oder traditionelle relationale Datenbank verwendet werden. Sie können entweder ein Schema erstellen oder die Daten freigeben.
Es ist extrem vielseitig. Fauna kann in der Cloud, vor Ort oder eingebettet in unsere Anwendung ausgeführt werden. Es bietet auch die beliebtesten Bereitstellungsoptionen wie Maschinen-Images oder Docker-Images. Diese Anwendung kann mit sehr hohen Geschwindigkeiten ausgeführt werden und funktioniert gut mit ACID-Transaktionen.
Amazonas-Aurora
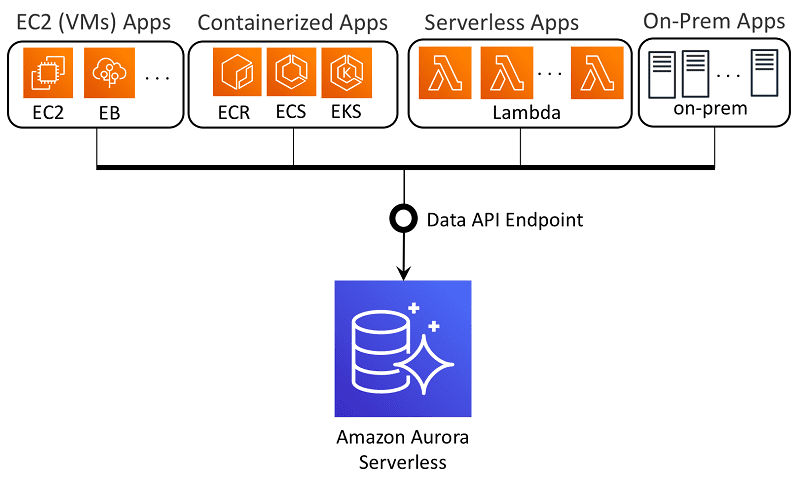
Amazon Aurora ist ein relationaler Datenspeicherdienst, auf den über die Amazon-Cloud zugegriffen werden kann. Dieser Dienst wird häufig zur Datenspeicherung verwendet. Es ermöglicht eine wertbasierte Datenspeicherung mit geringer Latenz.
 Bildnachweis: AWS
Bildnachweis: AWS
Amazon Aurora ist eine PostgreSQL- und MySQL-kompatible relationale Datenbank, die die Zugänglichkeit und Leistung herkömmlicher Datenbanken mit der Zuverlässigkeit und Einfachheit kommerzieller Datenbanken zu einem Zehntel der Kosten konsolidiert. Es verwendet einen geclusterten Ansatz zur Datenreplikation in der Zugriffszone von AWS für eine effiziente Datenverfügbarkeit.
Amazon Aurora verfügt über viele leistungsstarke Subsysteme. Der schnellste verteilte Speicher wird von MySQL- und PostgreSQL-Engines verwendet. Aurora beschleunigt den Durchsatz und die MySQL-Leistung im Vergleich zum aktuellen System um das Fünffache bzw. Dreifache.
Die Datenbank kann auf bis zu 64 Terabyte skaliert werden und bietet Unterstützung für die Unternehmensimplementierung. Amazon Aurora wird vollständig vom Amazon Relational Database Service (RDS) verwaltet, der Verwaltungsaufgaben wie Hardwarebereitstellung, Datenanordnung, Fehlerbehebung, Verstärkung und mehr automatisiert.
Bit.io
Mit bit.io können Sie schnell und einfach eine PostgreSQL-Datenbank einrichten. Ziehen Sie Dateien per Drag-and-Drop, um Daten in eine PostgreSQL-Datenbank zu laden. Sie können auch eine URL für eine Datei eingeben, Daten von R oder Python senden oder einen anderen Postgres/HTTP-Client verwenden.
Der SQL-Editor im Browser ermöglicht es Ihnen, mit den Daten mit einem Ihrer bevorzugten Datenanalysetools zu arbeiten, einschließlich SQL-Clients, R- und Python-Notebooks, Befehlszeile und vielem mehr.
bit.io bietet eine voll funktionsfähige PostgreSQL-Datenbank. Es kann schnell und praktisch ohne Konfiguration verwendet werden. Es lässt sich auch in eine wachsende Zahl von Datentools integrieren. bit.io funktioniert mit jedem Tool, das PostgreSQL unterstützt.
Upstash
Upstash, eine serverlose Speicher-Cloud-Datenbank, die von Upstash Inc (einem in Kalifornien ansässigen Unternehmen) erstellt wurde. Es kann als Caching-Layer oder als Datenbank verwendet werden. Sie müssen keine Cluster oder Datenbankserver verwalten. Es ist komplett serverlos.
Aus diesem Grund sind serverlose Technologien wie Upstash so nützlich. Upstash berechnet nichts, wenn Sie es nicht verwenden. Upstash kann für Redis-beliebte Anwendungsfälle verwendet werden wie:
- Allgemeines Caching
- Sitzungs-Caching
- Bestenlisten
- Warteschlangen
- Nutzungsmessung (Zählung)
- Inhalte filtern
Merkmale
- Entwickelt für Serverlos
- Zahlen Sie wenn sie hinausgehen
- Geringe Wartezeit
- Speicher, der langlebig und schnell ist
Xata
Xata, eine serverlose Datenbank, verfügt über leistungsstarke integrierte Such- und Analysefunktionen. Xata verwendet ein relationales Datenbankmodell mit einem strikten Schema (Schema) und unterstützt JSON-ähnliche Objekte. Die Aufzeichnungen werden in Tabellen organisiert, die dann in Datenbanken gruppiert werden.
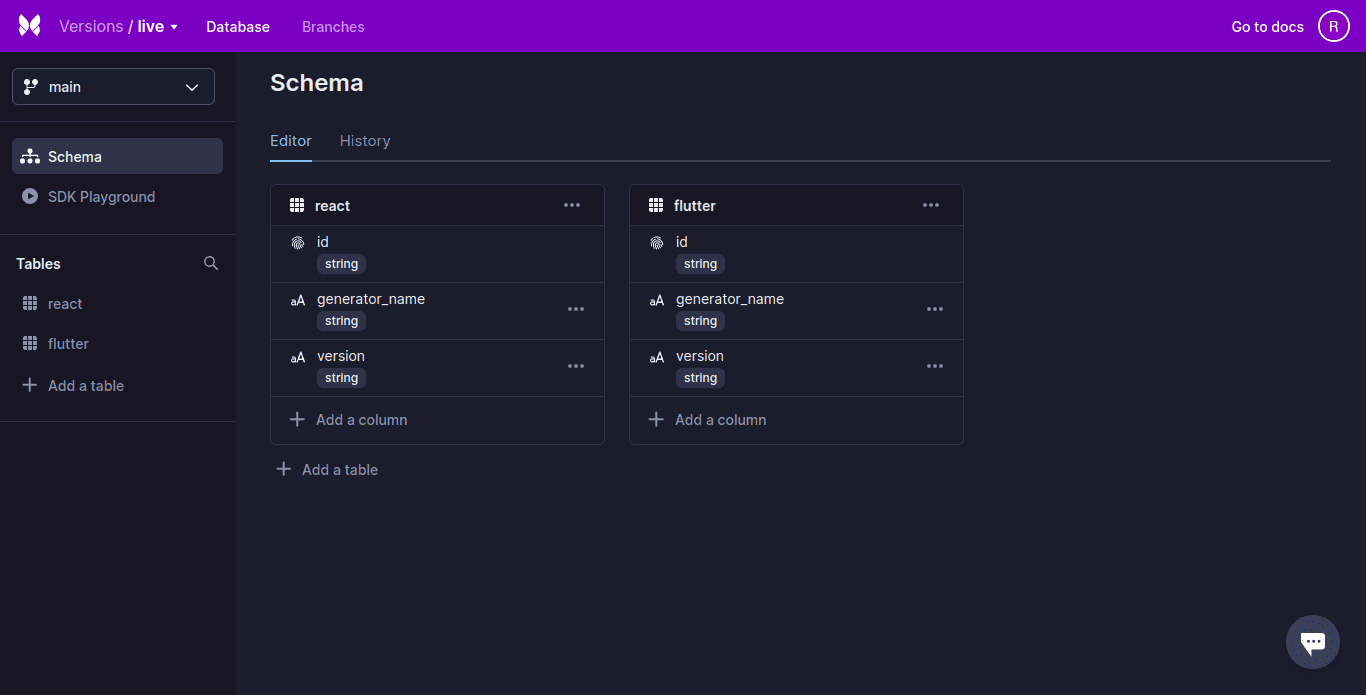
Xata unterstützt Rich-Spalten, und Beziehungen zwischen Tabellen können mithilfe von Link-Spalten dargestellt werden. Diese ähneln dem Fremdschlüssel.
Xata, ein neuer Cloud-Diensttyp, bietet eine Abstraktionsschicht über mehreren Datenspeichern, um die Entwicklung und den Betrieb von Anwendungen zu vereinfachen. Diese Art von Dienst wird als serverlose Datenplattform bezeichnet. Dieses Dokument kann verwendet werden, um Ihnen beim Replizieren der Architektur zu helfen, wodurch Sie einige der Vorteile der Verwendung von Xata erhalten.
SurrealDB
SurrealDB, eine innovative NewSQL-Cloud-Datenbank, kann für serverlose, Jamstack-, Single-Page-, herkömmliche und serverlose Anwendungen verwendet werden. Es bietet unvergleichliche Flexibilität und finanziellen Wert. Es kann in On-Premise-, Embedded- oder Edge-Computing-Umgebungen sowie in der Cloud bereitgestellt werden.
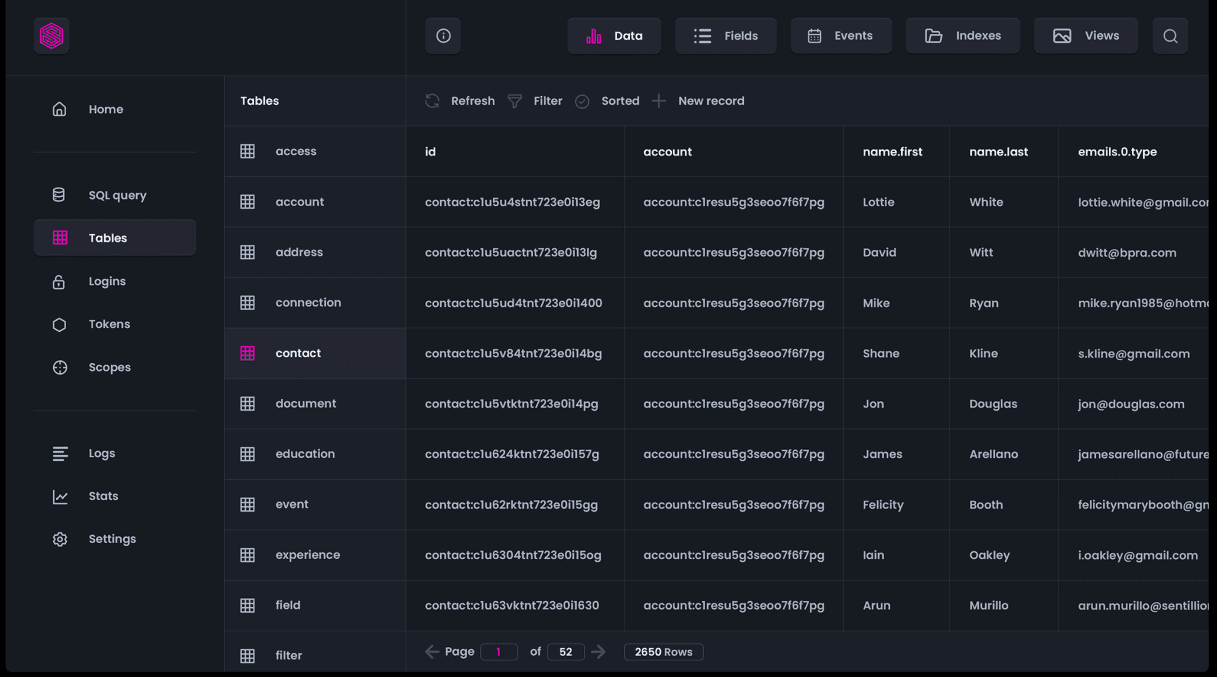
Ihr Team muss komplexe Datenbanksprachen nicht fließend beherrschen. Erweiterte Funktionen sind ebenfalls einfach und unkompliziert, aber dennoch schnell und leistungsfähig. Vergessen Sie das Skalieren von Servern, Datenbanken, Load Balancern und API-Endpunkten.
SurrealDB beseitigt die Komplexität aus Ihrem Stack und ermöglicht Ihnen die Skalierung mit einer verteilten, hochverfügbaren Plattform. Mit SurrealDB Cloud können Sie überall bereitstellen.
CosmosDB
Azure Cosmos DB, eine JSON-basierte global verteilte Datenbank, ist als „Platform as a Service“ (PaaS) in Microsoft Azure verfügbar. Es ermöglicht Benutzern das automatische Erstellen und Verteilen von Anwendungen in Azure-Rechenzentren ohne Konfiguration.
Es ist Teil von Azure und in allen Regionen verfügbar. Es repliziert auch Daten über mehrere Rechenzentren im Netzwerk.
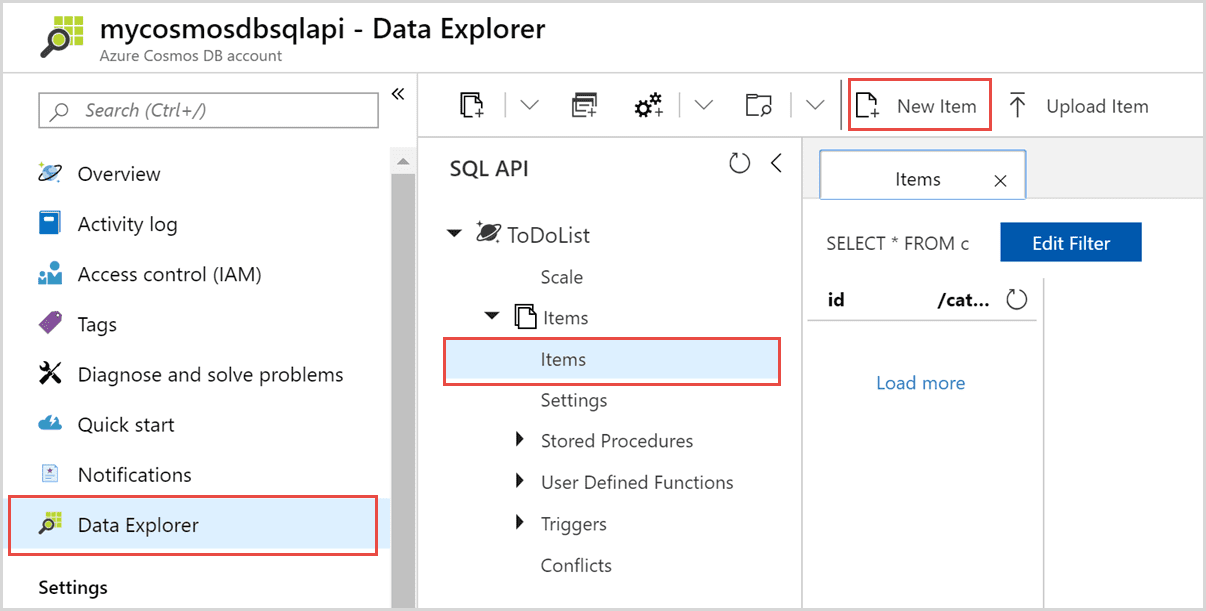
Es stehen viele Schnittstellen zur Verfügung, von denen die interessantesten SQL-basiert sind. CosmosDB ist der ideale Service für Organisationen, die viele kurzlebige, wichtige Informationen verarbeiten, abfragen und verwalten.
KakerlakeDB
CockroachDB, eine verteilte SQL-Datenbank, die auf einem konsistenten Schlüsselwert- und Transaktionsspeicher aufbaut, heißt CockroachDB.
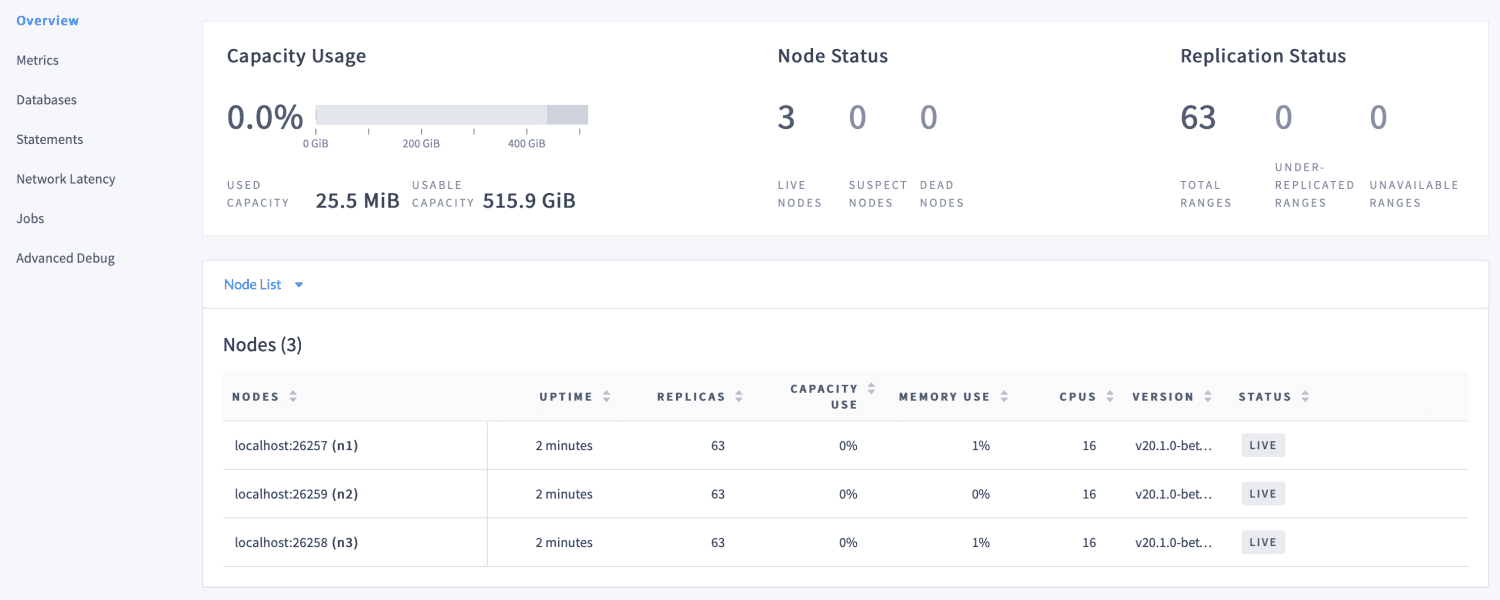
Es ist in Go geschrieben und vollständig Open Source. Zu den Hauptzielen gehören die Unterstützung von ACID-Transaktionen, horizontale Skalierung und Überlebensfähigkeit. Es zielt darauf ab, alles zu tolerieren, vom Ausfall einer einzelnen Festplatte bis hin zu einem kompletten Disaster-Recovery-Vorgang, ohne manuelles Eingreifen und mit minimaler Latenzunterbrechung.
CockroachDB ist eine gute Wahl für Anwendungen, die zuverlässige, genaue und verfügbare Daten in allen Größenordnungen benötigen. Sie können auf die Admin-Benutzeroberfläche zugreifen, die in einem Bundle mit CockroachDB unter https://localhost:8080 enthalten ist, sobald der Cluster betriebsbereit ist.
Es stellt Informationen zur Cluster- und Datenbankkonfiguration bereit und unterstützt uns bei der Optimierung der Clusterleistung durch Überwachung von Metriken wie Integrität, Laufzeitmetriken, Replikation und Knotendetails.
PlanetScale
Mit PlanetScale, einer neuen DBaaS-Plattform, können Sie schnell eine Datenbank ohne Verbindungsverwaltung einrichten. PlanetScale-Datenbanken wurden für Entwickler und ihre Arbeitsabläufe entwickelt. Sie können eine vollständig verwaltete Datenbank bereitstellen, die die Zuverlässigkeit und Flexibilität von MySQL bietet. Ihre Datenbanken basieren auf MySQL 8.0.
PlanetScale bietet zwei Arten von Datenbankzweigen an: Produktion und Entwicklung. Mit seiner Verzweigungsfunktion können Sie Ihre Datenbanken als Code behandeln. Sie können eine Verzweigung aus Ihrem Produktionsdatenbankschema erstellen, die für isolierte Entwicklungsumgebungen verwendet wird.
Fazit
Das war also alles über die besten serverlosen Datenbanken für moderne Anwendungen. Serverlose Datenbanken und insbesondere Amazon Aurora Serverless sind eine vielversprechende Zukunft. Denn jetzt können wir uns mit dieser neuen Technologie auf das Wesentliche wie Echtzeitzugriff auf Daten, Skalierbarkeit und Sicherheit konzentrieren.
Sie könnten auch an 7 Gründen interessiert sein, warum Serverless Computing eine aufstrebende Technologie ist.