
Prometheus ist ein auf Metriken basierendes Open-Source-Überwachungssystem. Es sammelt Daten von Diensten und Hosts, indem es HTTP-Anforderungen an Metrik-Endpunkte sendet. Anschließend speichert es die Ergebnisse in einer Zeitreihendatenbank und stellt sie für Analysen und Warnmeldungen zur Verfügung.
Inhaltsverzeichnis
Warum überwachen?
- Aktiviert Warnungen, wenn etwas schief geht, vorzugsweise bevor es schief geht. Damit sich das jemand anschauen kann.
- Es bietet Einblicke, um die Analyse, das Debugging und die Lösung des Problems zu ermöglichen.
- Es ermöglicht Ihnen, Trends/Änderungen im Laufe der Zeit zu sehen. Zum Beispiel, wie viele aktive Sitzungen zu einem bestimmten Zeitpunkt. Dies hilft bei Designentscheidungen und der Kapazitätsplanung.
Die Überwachung bezieht sich in der Regel auf Ereignisse. Ein Ereignis kann das Empfangen einer HTTP-Anforderung, das Senden einer Antwort, das Lesen von der Festplatte oder eine Benutzeranmeldung umfassen. Die Überwachung eines Systems kann Profilerstellung, Protokollierung, Rückverfolgung, Metriken, Alarmierung und Visualisierung umfassen.
Blackbox vs. Whitebox-Überwachung
Die Überwachung fällt in zwei Hauptkategorien:
Blackbox-Überwachung
Bei der Blackbox-Überwachung erfolgt die Überwachung auf Anwendungs- oder Hostebene, da diese von außen beobachtet werden. Das kann ziemlich einschränkend sein.
Whitebox-Überwachung
Whitebox-Überwachung bedeutet, die Interna eines Dienstes zu überwachen. Es würde Daten über den Zustand und die Leistung der internen Komponenten offenlegen.
Die vier goldenen Signale
Laut Googlewenn Sie nur vier Metriken Ihres benutzerorientierten Systems messen können, konzentrieren Sie sich auf die folgenden vier, die als die vier goldenen Signale bezeichnet werden:
#1. Latenz
Die Zeit, die benötigt wird, um eine Anfrage zu bearbeiten – erfolgreich oder fehlgeschlagen. Es ist wichtig, nicht nur erfolgreiche Anfragen zu verfolgen, sondern auch fehlgeschlagene.
#2. Verkehr
Ein Maß dafür, wie viel Bedarf an Ihr System gestellt wird. Bei einem Webdienst sind dies normalerweise HTTP-Anfragen pro Sekunde.
#3. Fehler
Die Rate der fehlgeschlagenen Anfragen.
#4. Sättigung
Wie voll Ihr Service ist. Die Erhöhung der Latenz ist oft ein wichtiger Indikator für die Sättigung. Viele Systeme verlieren an Leistung, lange bevor sie eine 100-prozentige Auslastung erreichen.
Prometheus-Metriktypen
Es gibt vier Haupttypen von Prometheus-Metriken:
#1. Zähler
Der Wert eines Zählers wird immer steigen. Sie kann niemals abnehmen, aber auf Null zurückgesetzt werden. Wenn also ein Scrape fehlschlägt, bedeutet dies nur einen fehlenden Datenpunkt. Die kumulative Erhöhung wäre beim nächsten Lesen verfügbar. Beispiele:
- Gesamtzahl der empfangenen HTTP-Anforderungen
- Die Anzahl der Ausnahmen.
#2. Messgerät
Ein Messgerät ist eine Momentaufnahme zu einem bestimmten Zeitpunkt. Es kann sowohl zunehmen als auch abnehmen. Wenn ein Datenabruf fehlschlägt, verlieren Sie ein Sample; Der nächste Abruf zeigt möglicherweise einen anderen Wert an: Beispiele für Speicherplatz, Speichernutzung.
#3. Histogramm
Ein Histogramm erfasst Beobachtungen und zählt sie in konfigurierbaren Buckets. Sie werden für Dinge wie Anfragedauer oder Antwortgrößen verwendet. Beispielsweise können Sie die Anforderungsdauer für eine bestimmte HTTP-Anforderung messen. Das Histogramm enthält eine Reihe von Buckets, z. B. 1 ms, 10 ms und 25 ms. Anstatt jede Dauer für jede Anfrage zu speichern, speichert Prometheus die Häufigkeit von Anfragen, die in einen bestimmten Bucket fallen.
#4. Zusammenfassung
Ähnlich wie bei Beobachtungen von Histogrammproben werden normalerweise Dauern oder Antwortgrößen angefordert. Es liefert eine Gesamtzahl der Beobachtungen und eine Summe aller beobachteten Werte, sodass Sie den Durchschnitt der beobachteten Werte berechnen können. Zum Beispiel hatten Sie in einer Minute drei Anfragen, die 2,3,4 Sekunden gedauert haben. Die Summe wäre 9 und die Anzahl wäre 3. Die Latenz wäre 3 Sekunden.
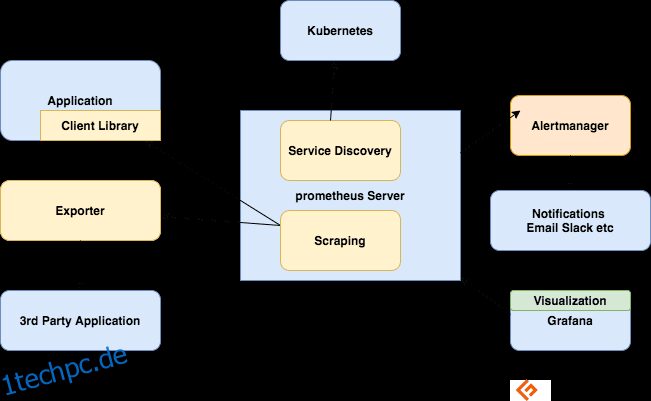
Komponenten des Prometheus-Ökosystems
Der Prometheus-Server
Sammelt Metriken, speichert sie und stellt sie für Abfragen zur Verfügung, sendet Warnungen basierend auf den gesammelten Metriken.
Schaben
Prometheus ist ein Pull-basiertes System. Um Metriken abzurufen, sendet Prometheus eine HTTP-Anfrage, die als Scrape bezeichnet wird. Es sendet basierend auf seiner Konfiguration Scraps an Ziele.
Jedes Ziel (statisch definiert oder dynamisch erkannt) wird in einem regelmäßigen Intervall (Scrape-Intervall) abgekratzt. Jedes Scrape liest den HTTP-Endpunkt /metrics, um den aktuellen Status der Clientmetriken abzurufen, und speichert die Werte in der Prometheus-Zeitreihendatenbank.
Es gibt weitere Zeitreihendatenbanken für Überwachungslösungen, die Sie vielleicht erkunden möchten.
Client-Bibliotheken
Um einen Dienst zu überwachen, müssen Sie Ihrem Code Instrumentierung hinzufügen. Es sind Client-Bibliotheken für alle gängigen Sprachen und Laufzeiten verfügbar. Wenn Sie diese Bibliotheken verwenden, kann Ihr Code nach dem Hinzufügen einiger Codezeilen mit der Ausgabe von Metriken beginnen. Dies wird als direkte Instrumentierung bezeichnet. Diese Bibliotheken ermöglichen es Ihnen, interne Metriken zu definieren und sie auch über einen HTTP-Endpunkt bereitzustellen. Wenn Prometheus den HTTP-Endpunkt der Metriken kratzt, sendet die Clientbibliothek die Metriken an den Server.
Offizielle Clientbibliotheken werden von Prometheus für Go, Java, Python und Ruby angeboten. Prometheus hat ein offenes Ökosystem. Es gibt auch von der Community erstellte Client-Bibliotheken für C, PHP, Node.js, C#/.NET und viele andere.
Exporteure
Viele Anwendungen stellen Metriken im Nicht-Prometheus-Format bereit. Für diese und für Anwendungen, die Sie nicht besitzen oder für die Sie keinen Zugriff auf Code haben, können Sie die Instrumentierung nicht direkt hinzufügen. Beispielsweise MySQL-, Kafka-, JMX-, HAProxy- und NGINX-Server. In diesen Szenarien machen Sie Gebrauch von Exporteure.
Ein Exporter ist ein Tool, das Sie zusammen mit der Anwendung bereitstellen, von der Sie Metriken erhalten möchten. Ein Exporteur agiert wie ein Proxy zwischen der Anwendung und Prometheus. Es empfängt Anfragen vom Prometheus-Server, sammelt Daten aus den Zugriffsprotokollen und Fehlerprotokollen der Anwendung, wandelt sie in das richtige Format um und kehrt schließlich zum Prometheus-Server zurück.
Einige der beliebtesten Exporteure sind:
- Fenster – für Windows-Servermetriken
- Knoten – für Linux-Servermetriken
- Flugschreiber – für DNS- und Website-Leistungsmetriken
- JMX – für Java-basierte Anwendungsmetriken
Sobald die Anwendungen instrumentiert wurden oder die Exporteure vorhanden sind, müssen Sie Prometheus mitteilen, wo sie sich befinden. Dies kann mithilfe einer statischen Konfiguration erfolgen. Bei dynamischen Umgebungen ist dies nicht möglich; daher wird Diensterkennung verwendet.
Alarmierung
Die Alarmierung mit Prometheus besteht aus zwei Teilen –
Alerting-Regeln senden Alerts an den Alertmanager.
Der Alertmanager verwaltet dann diese Alerts. Es sendet Benachrichtigungen mit vielen sofort einsatzbereiten Integrationen wie E-Mail, Slack, Hipchat und PagerDuty. Der Alertmanager kann auch Silencing oder Aggregation durchführen, um die Anzahl der Benachrichtigungen zu reduzieren.
Hier ist die Anleitung zur Überwachung des Linux-Servers mit Prometheus und Dashboard.
Visualisierung mit Dashboards
Prometheus verfügt über eine Reihe von APIs, mit denen PromQL-Abfragen Rohdaten für Visualisierungen erzeugen können.
Obwohl Prometheus einen Ausdrucksbrowser enthält, der für Ad-hoc-Abfragen verwendet werden kann, ist das beste verfügbare Tool Grafana. Grafana lässt sich vollständig in Prometheus integrieren und kann eine Vielzahl von Dashboards erstellen.
Sie müssen Prometheus als Datenquelle für Grafana konfigurieren.
Sie können Dashboards hinzufügen, indem Sie:
- Importieren von von der Community erstellten Dashboards
- Eigenbau
- Verwenden eines vordefinierten Dashboards.
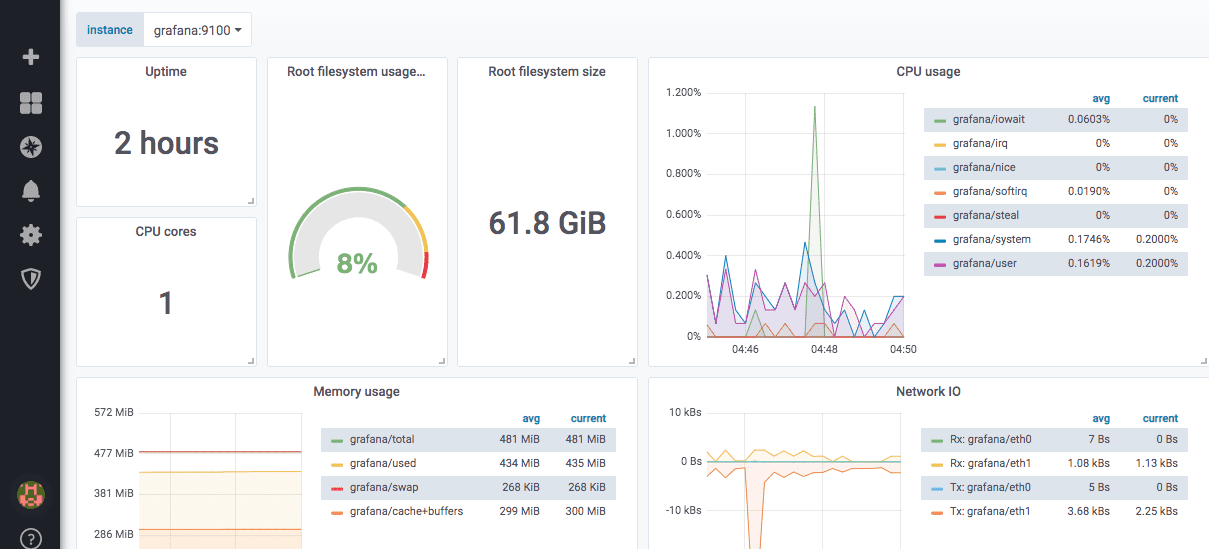
So sieht ein vordefiniertes Node-Exporter-Dashboard aus:
Grafana verfügt über ein WorldPing-Modul, mit dem Sie Site- und DNS-Leistungsmetriken weltweit überwachen können.
Zusammenfassung
Prometheus hat sehr wenige Anforderungen. Es kann recht einfach ausgeführt werden, da es sich um eine einzelne Binärdatei mit einer Konfigurationsdatei handelt. Es kann Tausende von Zielen verarbeiten und Millionen von Samples pro Sekunde aufnehmen. Prometheus wurde entwickelt, um das Gesamtsystem, den Zustand und das Verhalten des Systems zu verfolgen.
Grafana ist das beste verfügbare Tool zur Visualisierung von Metriken und lässt sich nahtlos integrieren Prometheus.