
Im Laufe der Jahre hat die Verwendung von Python für die Datenwissenschaft unglaublich zugenommen und wächst täglich weiter.
Data Science ist ein riesiges Studiengebiet mit vielen Teilbereichen, von denen die Datenanalyse unbestreitbar eines der wichtigsten aller dieser Bereiche ist, und unabhängig vom Kenntnisstand in Data Science wird es immer wichtiger, zu verstehen oder zumindest Grundkenntnisse haben.
Inhaltsverzeichnis
Was ist Datenanalyse?
Datenanalyse ist die Bereinigung und Transformation einer großen Menge unstrukturierter oder unorganisierter Daten mit dem Ziel, wichtige Erkenntnisse und Informationen über diese Daten zu gewinnen, die dabei helfen, fundierte Entscheidungen zu treffen.
Es gibt verschiedene Tools, die für die Datenanalyse verwendet werden, Python, Microsoft Excel, Tableau, SaS usw., aber in diesem Artikel konzentrieren wir uns darauf, wie die Datenanalyse in Python durchgeführt wird. Genauer gesagt, wie es mit einer Python-Bibliothek namens gemacht wird Pandas.
Was sind Pandas?
Pandas ist eine Open-Source-Python-Bibliothek, die für Datenmanipulation und Wrangling verwendet wird. Es ist schnell und hocheffizient und verfügt über Tools zum Laden verschiedener Arten von Daten in den Speicher. Es kann verwendet werden, um mehrere Formen von Daten umzugestalten, zu beschriften, zu indizieren oder sogar zu gruppieren.
Datenstrukturen in Pandas
Es gibt 3 Datenstrukturen in Pandas, nämlich;
Der beste Weg, die drei zu unterscheiden, besteht darin, zu sehen, dass einer mehrere Stapel des anderen enthält. Ein DataFrame ist also ein Stapel von Serien und ein Panel ist ein Stapel von DataFrames.
Eine Reihe ist ein eindimensionales Array
Ein Stapel mehrerer Serien ergibt einen zweidimensionalen DataFrame
Ein Stack aus mehreren DataFrames ergibt ein 3-dimensionales Panel
Die Datenstruktur, mit der wir am häufigsten arbeiten würden, ist der zweidimensionale DataFrame, der auch das Standarddarstellungsmittel für einige Datensätze sein kann, auf die wir stoßen könnten.
Datenanalyse in Pandas
Für diesen Artikel ist keine Installation erforderlich. Wir würden ein Tool namens verwenden kooperativ erstellt von Google. Es ist eine Online-Python-Umgebung für Datenanalyse, maschinelles Lernen und KI. Es ist einfach ein Cloud-basiertes Jupyter-Notebook, das mit fast jedem Python-Paket vorinstalliert ist, das Sie als Datenwissenschaftler benötigen würden.
Gehen Sie jetzt zu https://colab.research.google.com/notebooks/intro.ipynb. Sie sollten das Folgende sehen.
Klicken Sie in der linken oberen Navigationsleiste auf die Dateioption und dann auf die Option „Neues Notizbuch“. In Ihrem Browser wird eine neue Jupyter-Notebook-Seite geladen. Als erstes müssen wir Pandas in unsere Arbeitsumgebung importieren. Wir können das tun, indem wir den folgenden Code ausführen;
import pandas as pd
Für diesen Artikel würden wir einen Immobilienpreis-Datensatz für unsere Datenanalyse verwenden. Der Datensatz, den wir verwenden würden, kann gefunden werden hier. Das erste, was wir tun möchten, ist, diesen Datensatz in unsere Umgebung zu laden.
Wir können das mit dem folgenden Code in einer neuen Zelle tun;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')
Die .read_csv wird verwendet, wenn wir eine CSV-Datei lesen möchten und wir eine sep-Eigenschaft übergeben haben, um zu zeigen, dass die CSV-Datei durch Kommas getrennt ist.
Wir sollten auch beachten, dass unsere geladene CSV-Datei in einer Variablen df gespeichert wird.
Wir müssen die print()-Funktion in Jupyter Notebook nicht verwenden. Wir können einfach einen Variablennamen in unsere Zelle eingeben und Jupyter Notebook druckt ihn für uns aus.
Wir können das ausprobieren, indem wir df in eine neue Zelle eingeben und es ausführen, es wird alle Daten in unserem Datensatz als DataFrame für uns ausdrucken.
Aber wir wollen nicht immer alle Daten sehen, manchmal wollen wir nur die ersten paar Daten und ihre Spaltennamen sehen. Wir können die Funktion df.head() verwenden, um die ersten fünf Spalten zu drucken, und df.tail(), um die letzten fünf zu drucken. Die Ausgabe von jedem der beiden würde so aussehen;
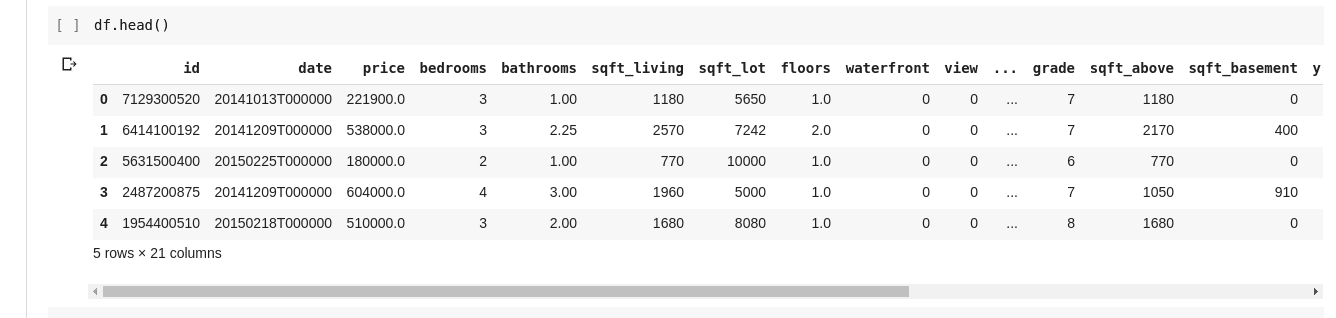
Wir möchten auf Beziehungen zwischen diesen mehreren Datenzeilen und -spalten prüfen. Die Funktion .describe() erledigt genau das für uns.
Das Ausführen von df.describe() ergibt die folgende Ausgabe;
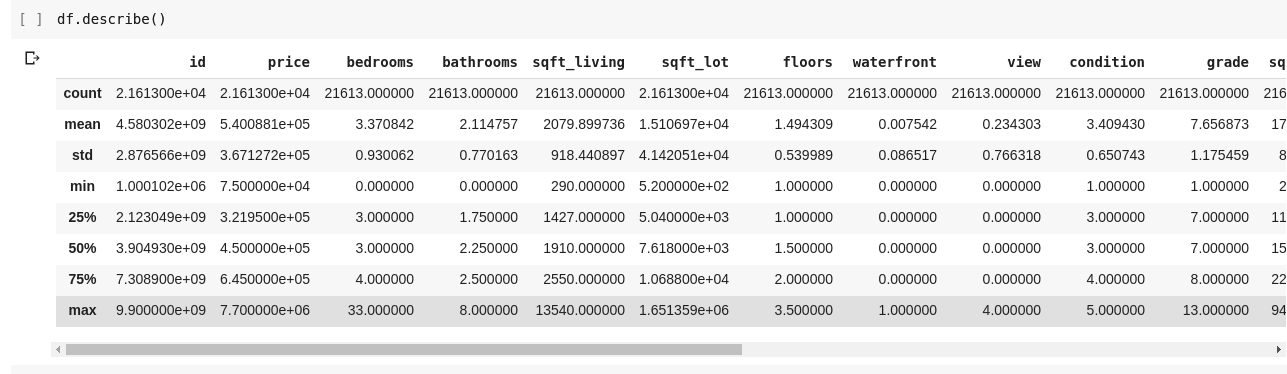
Wir können sofort sehen, dass .describe() den Mittelwert, die Standardabweichung, die minimalen und maximalen Werte und die Perzentile jeder einzelnen Spalte im DataFrame angibt. Dies ist insbesondere sehr nützlich.
Wir können auch die Form unseres 2D-Datenrahmens überprüfen, um herauszufinden, wie viele Zeilen und Spalten er hat. Wir können das mit df.shape tun, das ein Tupel im Format (Zeilen, Spalten) zurückgibt.
Wir können auch die Namen aller Spalten in unserem DataFrame mit df.columns überprüfen.
Was ist, wenn wir nur eine Spalte auswählen und alle Daten darin zurückgeben möchten? Dies geschieht auf ähnliche Weise wie das Durchsuchen eines Wörterbuchs. Geben Sie den folgenden Code in eine neue Zelle ein und führen Sie ihn aus
df['price ']
Der obige Code gibt die Preisspalte zurück, wir können weiter gehen, indem wir sie als solche in einer neuen Variablen speichern
price = df['price']
Jetzt können wir jede andere Aktion ausführen, die an einem DataFrame für unsere Preisvariable ausgeführt werden kann, da es sich nur um eine Teilmenge eines tatsächlichen DataFrame handelt. Wir können Dinge wie df.head(), df.shape usw. machen.
Wir könnten auch mehrere Spalten auswählen, indem wir eine Liste von Spaltennamen als solche an df übergeben
data = df[['price ', 'bedrooms']]
Oben werden Spalten mit den Namen „Preis“ und „Schlafzimmer“ ausgewählt. Wenn wir data.head() in eine neue Zelle eingeben, hätten wir Folgendes
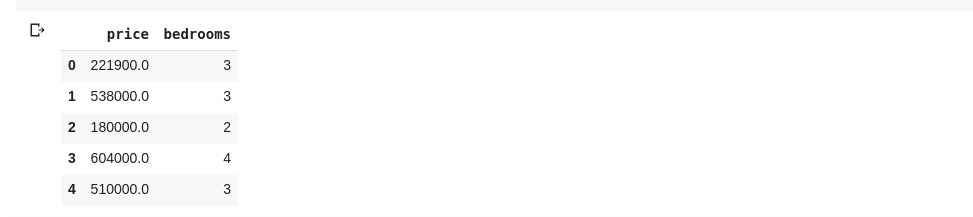
Die obige Methode zum Aufteilen von Spalten gibt alle Zeilenelemente in dieser Spalte zurück. Was ist, wenn wir eine Teilmenge von Zeilen und eine Teilmenge von Spalten aus unserem Datensatz zurückgeben möchten? Dies kann mit .iloc erfolgen und wird ähnlich wie Python-Listen indiziert. Also können wir sowas machen
df.iloc[50: , 3]
Was die 3. Spalte von der 50. Zeile bis zum Ende zurückgibt. Es ist ziemlich ordentlich und genauso wie das Schneiden von Listen in Python.
Lassen Sie uns jetzt ein paar wirklich interessante Dinge tun. Unser Wohnungspreisdatensatz enthält eine Spalte, die uns den Preis eines Hauses angibt, und eine andere Spalte gibt uns die Anzahl der Schlafzimmer an, die dieses bestimmte Haus hat. Der Hauspreis ist ein kontinuierlicher Wert, daher ist es möglich, dass wir nicht zwei Häuser haben, die den gleichen Preis haben. Aber die Anzahl der Schlafzimmer ist etwas diskret, so dass wir mehrere Häuser mit zwei, drei, vier Schlafzimmern usw. haben können.
Was ist, wenn wir alle Häuser mit der gleichen Anzahl von Schlafzimmern erhalten und den Durchschnittspreis für jedes einzelne Schlafzimmer ermitteln möchten? Bei Pandas ist das relativ einfach, es kann so gemacht werden;
df.groupby('bedrooms ')['price '].mean()
Das obige gruppiert den DataFrame zuerst nach den Datensätzen mit identischer Schlafzimmernummer mit der Funktion df.groupby(), dann sagen wir ihm, dass er uns nur die Schlafzimmerspalte geben soll und verwenden die Funktion .mean(), um den Mittelwert jedes Hauses im Datensatz zu finden .
Was ist, wenn wir das Obige visualisieren wollen? Wir möchten in der Lage sein, zu überprüfen, wie der Durchschnittspreis jeder einzelnen Schlafzimmernummer variiert? Wir müssen nur den vorherigen Code an eine .plot()-Funktion als solche verketten;
df.groupby('bedrooms ')['price '].mean().plot()
Wir werden eine Ausgabe haben, die so aussieht;
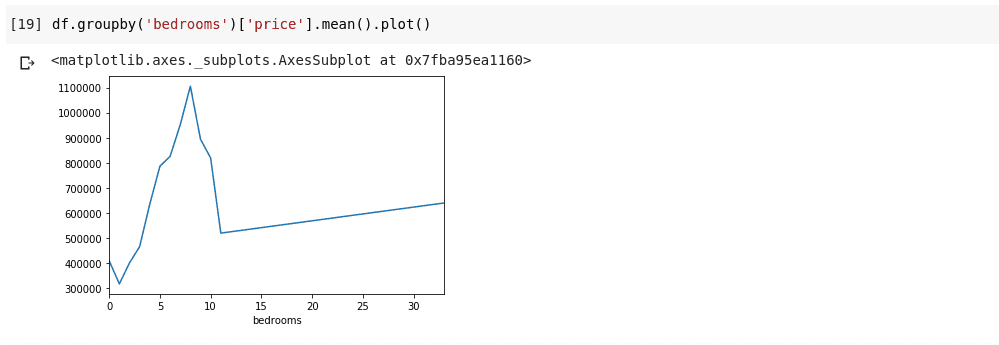
Das Obige zeigt uns einige Trends in den Daten. Auf der horizontalen Achse haben wir eine eindeutige Anzahl von Schlafzimmern (Beachten Sie, dass mehr als ein Haus X Schlafzimmer haben kann). Auf der vertikalen Achse haben wir den Mittelwert der Preise in Bezug auf die entsprechende Anzahl von Schlafzimmern auf der horizontalen Achse. Wir können jetzt sofort feststellen, dass Häuser mit 5 bis 10 Schlafzimmern viel mehr kosten als Häuser mit 3 Schlafzimmern. Es wird auch deutlich, dass Häuser mit etwa 7 oder 8 Schlafzimmern viel mehr kosten als solche mit 15, 20 oder sogar 30 Zimmern.
Informationen wie die oben genannten sind der Grund, warum die Datenanalyse sehr wichtig ist. Wir sind in der Lage, nützliche Erkenntnisse aus den Daten zu extrahieren, die ohne Analyse nicht sofort oder gar nicht erkennbar sind.
Fehlende Daten
Nehmen wir an, ich nehme an einer Umfrage teil, die aus einer Reihe von Fragen besteht. Ich teile einen Link zur Umfrage mit Tausenden von Menschen, damit sie ihr Feedback geben können. Mein ultimatives Ziel ist es, eine Datenanalyse für diese Daten durchzuführen, damit ich einige wichtige Erkenntnisse aus den Daten gewinnen kann.
Jetzt könnte viel schief gehen, einige Vermesser könnten sich unwohl fühlen, einige meiner Fragen zu beantworten, und es leer lassen. Viele Leute könnten dasselbe für einige Teile meiner Umfragefragen tun. Dies ist möglicherweise kein Problem, aber stellen Sie sich vor, ich würde in meiner Umfrage numerische Daten sammeln und ein Teil der Analyse erforderte, dass ich entweder die Summe, den Mittelwert oder eine andere arithmetische Operation erhalte. Mehrere fehlende Werte würden zu vielen Ungenauigkeiten in meiner Analyse führen. Ich muss einen Weg finden, diese fehlenden Werte zu finden und durch einige Werte zu ersetzen, die ein enger Ersatz für sie sein könnten.
Pandas stellen uns eine Funktion zur Verfügung, um fehlende Werte in einem DataFrame namens isnull() zu finden.
Die Funktion isnull() kann als solche verwendet werden;
df.isnull()
Dies gibt einen DataFrame aus booleschen Werten zurück, der uns mitteilt, ob die ursprünglich dort vorhandenen Daten wirklich fehlten oder fälschlicherweise fehlten. Die Ausgabe würde so aussehen;
Wir brauchen einen Weg, um all diese fehlenden Werte ersetzen zu können, meistens kann die Auswahl fehlender Werte als Null angenommen werden. Manchmal könnte es als Mittelwert aller anderen Daten oder vielleicht als Mittelwert der Daten um ihn herum genommen werden, abhängig vom Data Scientist und dem Anwendungsfall der analysierten Daten.
Um alle fehlenden Werte in einem DataFrame zu füllen, verwenden wir die als solche verwendete Funktion .fillna();
df.fillna(0)
Oben füllen wir alle leeren Daten mit dem Wert Null. Es könnte auch jede andere Zahl sein, die wir angeben.
Die Bedeutung von Daten kann nicht genug betont werden, sie helfen uns, Antworten direkt aus unseren Daten selbst zu bekommen!. Sie sagen, Datenanalyse sei das neue Öl für digitale Ökonomien.
Alle Beispiele in diesem Artikel können gefunden werden hier.
Um mehr zu erfahren, schauen Sie vorbei Online-Kurs Datenanalyse mit Python und Pandas.