
Sie fragen sich, wie Sie zuverlässige und konsistente Daten für die Datenanalyse erhalten? Implementieren Sie diese Datenbereinigungsstrategien jetzt!
Ihre Geschäftsentscheidung basiert auf Erkenntnissen aus der Datenanalyse. In ähnlicher Weise hängen die aus Eingabedatensätzen gewonnenen Erkenntnisse von der Qualität der Quelldaten ab. Datenquellen von geringer Qualität, Ungenauigkeit, Müll und inkonsistente Daten sind die großen Herausforderungen für die Data Science- und Data Analytics-Branche.
Daher haben Experten Workarounds entwickelt. Diese Problemumgehung ist die Datenbereinigung. Es erspart Ihnen datengesteuerte Entscheidungen, die dem Unternehmen schaden, anstatt es zu verbessern.
Lesen Sie weiter, um die besten Datenbereinigungsstrategien zu erfahren, die erfolgreiche Datenwissenschaftler und Analysten anwenden. Erkunden Sie auch Tools, die saubere Daten für sofortige Data-Science-Projekte liefern können.
Inhaltsverzeichnis
Was ist Datenbereinigung?
Datenqualität hat fünf Dimensionen. Das Identifizieren und Korrigieren von Fehlern in Ihren Eingabedaten durch Befolgen der Datenqualitätsrichtlinien wird als Datenbereinigung bezeichnet.
Die Qualitätsparameter dieses fünfdimensionalen Standards sind:
#1. Vollständigkeit
Dieser Qualitätskontrollparameter stellt sicher, dass die Eingabedaten alle erforderlichen Parameter, Kopfzeilen, Zeilen, Spalten, Tabellen usw. für ein Data-Science-Projekt aufweisen.
#2. Genauigkeit
Ein Datenqualitätsindikator, der besagt, dass die Daten nahe am wahren Wert der Eingabedaten liegen. Daten können von echtem Wert sein, wenn Sie alle statistischen Standards für Umfragen befolgen oder für die Datenerfassung aussortieren.
#3. Gültigkeit
Dieser Parameter Data Science stellt sicher, dass die Daten den von Ihnen festgelegten Geschäftsregeln entsprechen.
#4. Gleichmäßigkeit
Einheitlichkeit bestätigt, ob die Daten einen einheitlichen Inhalt haben oder nicht. Beispielsweise sollten Erhebungsdaten zum Energieverbrauch in den USA alle Einheiten als imperiales Maßsystem enthalten. Wenn Sie das metrische System für bestimmte Inhalte in derselben Umfrage verwenden, sind die Daten nicht einheitlich.
#5. Konsistenz
Konsistenz stellt sicher, dass die Datenwerte zwischen Tabellen, Datenmodellen und Datensätzen konsistent sind. Sie müssen diesen Parameter auch genau überwachen, wenn Sie Daten zwischen Systemen verschieben.
Kurz gesagt, wenden Sie die oben genannten Qualitätskontrollprozesse auf Rohdatensätze an und bereinigen Sie die Daten, bevor Sie sie einem Business-Intelligence-Tool zuführen.
Bedeutung der Datenbereinigung
Einfach so können Sie Ihr digitales Geschäft nicht mit einem schlechten Internet-Bandbreitenplan betreiben; Sie können keine großartigen Entscheidungen treffen, wenn die Datenqualität nicht akzeptabel ist. Wenn Sie versuchen, Datenmüll und fehlerhafte Daten zu verwenden, um Geschäftsentscheidungen zu treffen, werden Sie Umsatzeinbußen oder einen schlechten Return on Investment (ROI) feststellen.
Laut einem Gartner-Bericht über schlechte Datenqualität und ihre Folgen hat die Denkfabrik herausgefunden, dass der durchschnittliche Verlust, dem ein Unternehmen ausgesetzt ist, 12,9 Millionen US-Dollar beträgt. Dies dient nur dazu, Entscheidungen zu treffen, die sich auf fehlerhafte, gefälschte und Mülldaten stützen.
Derselbe Bericht deutet darauf hin, dass die Verwendung schlechter Daten in den USA das Land einen unglaublichen jährlichen Verlust von 3 Billionen Dollar kostet.
Die endgültige Erkenntnis wird sicherlich Müll sein, wenn Sie das BI-System mit Datenmüll füttern.
Daher müssen Sie die Rohdaten bereinigen, um finanzielle Verluste zu vermeiden und effektive Geschäftsentscheidungen aus Datenanalyseprojekten zu treffen.
Vorteile der Datenbereinigung
#1. Vermeiden Sie monetäre Verluste
Durch die Bereinigung der Eingabedaten können Sie Ihrem Unternehmen finanzielle Verluste ersparen, die als Strafe für die Nichteinhaltung oder den Verlust von Kunden entstehen könnten.
#2. Treffen Sie großartige Entscheidungen

Hochwertige und umsetzbare Daten liefern großartige Einblicke. Solche Einblicke helfen Ihnen, hervorragende Geschäftsentscheidungen in Bezug auf Produktmarketing, Verkauf, Bestandsverwaltung, Preisgestaltung usw. zu treffen.
#3. Verschaffen Sie sich einen Vorteil gegenüber dem Konkurrenten
Wenn Sie sich früher als Ihre Wettbewerber für eine Datenbereinigung entscheiden, profitieren Sie von den Vorteilen, zum Fast Mover Ihrer Branche zu werden.
#4. Machen Sie das Projekt effizient
Ein optimierter Datenbereinigungsprozess erhöht das Vertrauen der Teammitglieder. Da sie wissen, dass die Daten zuverlässig sind, können sie sich mehr auf die Datenanalyse konzentrieren.
#5. Ressourcen sparen
Das Bereinigen und Trimmen von Daten reduziert die Größe der gesamten Datenbank. Daher leeren Sie den Speicherplatz der Datenbank, indem Sie Datenmüll beseitigen.
Strategien zur Datenbereinigung
Standardisieren Sie die visuellen Daten
Ein Datensatz enthält zahlreiche Arten von Zeichen wie Texte, Ziffern, Symbole usw. Sie müssen auf alle Texte ein einheitliches Format für die Groß- und Kleinschreibung anwenden. Stellen Sie sicher, dass die Symbole die richtige Codierung haben, wie Unicode, ASCII usw.
Beispielsweise bedeutet der großgeschriebene Begriff Bill den Namen einer Person. Im Gegensatz dazu bedeutet eine Rechnung oder die Rechnung eine Quittung einer Transaktion; Daher ist eine angemessene Formatierung der Groß- und Kleinschreibung von entscheidender Bedeutung.
Replizierte Daten entfernen
Doppelte Daten bringen das BI-System durcheinander. Folglich wird das Muster schief. Daher müssen Sie doppelte Einträge aus der Eingabedatenbank aussortieren.
Duplikate stammen normalerweise aus menschlichen Dateneingabeprozessen. Wenn Sie den Rohdateneingabeprozess automatisieren können, können Sie Datenreplikationen vom Stamm aus beseitigen.
Unerwünschte Ausreißer beheben
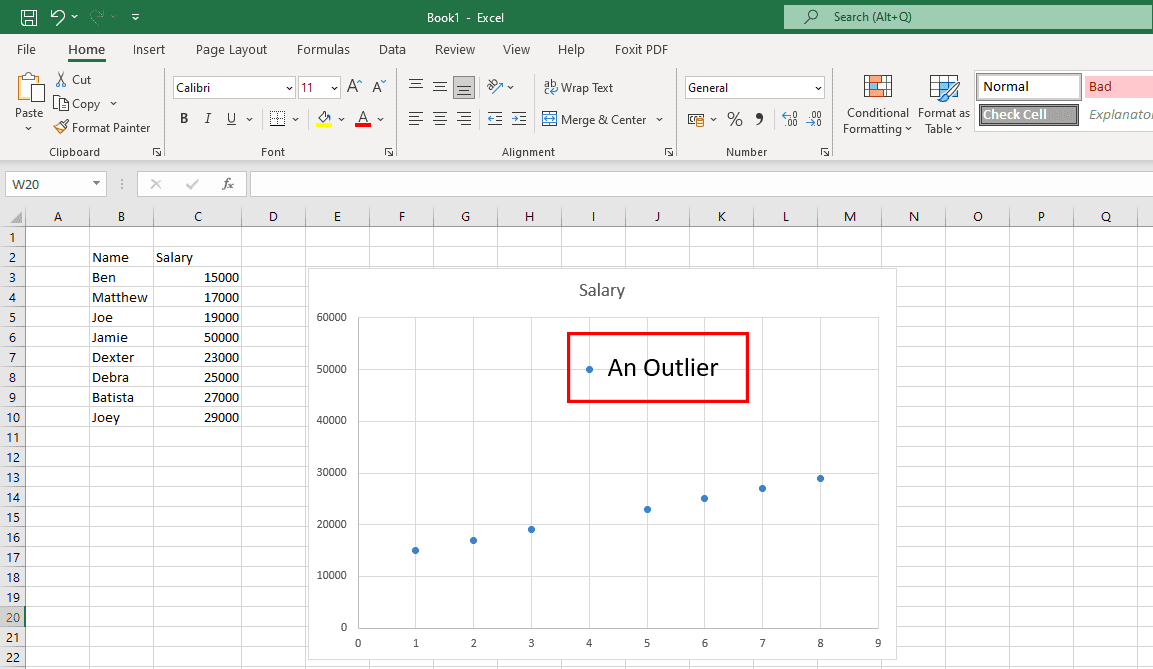
Ausreißer sind ungewöhnliche Datenpunkte, die nicht innerhalb des Datenmusters liegen, wie in der obigen Grafik dargestellt. Echte Ausreißer sind in Ordnung, da sie den Datenwissenschaftlern helfen, Umfragefehler zu entdecken. Wenn Ausreißer jedoch auf menschliche Fehler zurückzuführen sind, ist dies ein Problem.
Sie müssen die Datensätze in Diagramme oder Grafiken einfügen, um nach Ausreißern zu suchen. Wenn Sie welche finden, untersuchen Sie die Quelle. Wenn die Quelle ein menschlicher Fehler ist, entfernen Sie die Ausreißerdaten.
Fokus auf Strukturdaten
Es geht hauptsächlich darum, Fehler in den Datensätzen zu finden und zu beheben.
Beispielsweise enthält ein Datensatz eine Spalte mit USD und viele Spalten mit anderen Währungen. Wenn Ihre Daten für das US-Publikum bestimmt sind, rechnen Sie andere Währungen in den entsprechenden US-Dollar um. Ersetzen Sie dann alle anderen Währungen in USD.
Scannen Sie Ihre Daten
Eine riesige Datenbank, die aus einem Data Warehouse heruntergeladen wurde, kann Tausende von Tabellen enthalten. Möglicherweise benötigen Sie nicht alle Tabellen für Ihr Data-Science-Projekt.
Nachdem Sie die Datenbank erhalten haben, müssen Sie daher ein Skript schreiben, um die benötigten Datentabellen zu lokalisieren. Sobald Sie dies wissen, können Sie irrelevante Tabellen löschen und die Größe des Datensatzes minimieren.
Dies wird letztendlich zu einer schnelleren Erkennung von Datenmustern führen.
Daten in der Cloud bereinigen
Wenn Ihre Datenbank den Schema-on-Write-Ansatz verwendet, müssen Sie sie in Schema-on-Read konvertieren. Dies ermöglicht die Datenbereinigung direkt im Cloud-Speicher und die Extraktion formatierter, organisierter und analysebereiter Daten.
Fremdsprachen übersetzen
Wenn Sie weltweit eine Umfrage durchführen, müssen Sie mit Fremdsprachen in den Rohdaten rechnen. Sie müssen Zeilen und Spalten, die Fremdsprachen enthalten, ins Englische oder eine andere bevorzugte Sprache übersetzen. Zu diesem Zweck können Sie computerunterstützte Übersetzungswerkzeuge (CAT) verwenden.
Datenbereinigung Schritt für Schritt
#1. Suchen Sie kritische Datenfelder
Ein Data Warehouse enthält Terabytes an Datenbanken. Jede Datenbank kann einige bis Tausende von Datenspalten enthalten. Jetzt müssen Sie sich das Projektziel ansehen und Daten aus solchen Datenbanken entsprechend extrahieren.
Wenn Ihr Projekt E-Commerce-Einkaufstrends von US-Bürgern untersucht, ist das Sammeln von Daten zu Offline-Einzelhandelsgeschäften in derselben Arbeitsmappe nicht sinnvoll.
#2. Daten organisieren

Wenn Sie die wichtigen Datenfelder, Spaltenüberschriften, Tabellen usw. aus einer Datenbank gefunden haben, sammeln Sie sie auf organisierte Weise.
#3. Löschen Sie Duplikate
Aus Data Warehouses gesammelte Rohdaten enthalten immer doppelte Einträge. Sie müssen diese Replikate suchen und löschen.
#4. Beseitigen Sie leere Werte und Leerzeichen
Einige Spaltenüberschriften und die entsprechenden Datenfelder enthalten möglicherweise keine Werte. Sie müssen diese Spaltenüberschriften/Felder entfernen oder leere Werte durch die richtigen alphanumerischen Werte ersetzen.
#5. Feinformatierung durchführen
Datensätze können unnötige Leerzeichen, Symbole, Zeichen usw. enthalten. Sie müssen diese mithilfe von Formeln formatieren, damit der gesamte Datensatz hinsichtlich Zellengröße und -spanne einheitlich aussieht.
#6. Standardisieren Sie den Prozess
Sie müssen eine SOP erstellen, der die Mitglieder des Data-Science-Teams folgen und ihre Pflicht während des Datenbereinigungsprozesses erfüllen können. Es muss Folgendes enthalten:
- Häufigkeit der Rohdatenerhebung
- Rohdatenspeicherung und Wartungsleiter
- Reinigungshäufigkeit
- Saubere Datenspeicherung und Wartungsaufsicht
Hier sind einige beliebte Datenbereinigungstools, die Ihnen bei Ihren Data-Science-Projekten helfen können:
WinPure

Wenn Sie nach einer Anwendung suchen, mit der Sie die Daten genau und schnell bereinigen und löschen können, ist WinPure eine zuverlässige Lösung. Dieses branchenführende Tool bietet eine Datenbereinigungsfunktion auf Unternehmensebene mit unübertroffener Geschwindigkeit und Präzision.
Da es für einzelne Benutzer und Unternehmen entwickelt wurde, kann es jeder problemlos verwenden. Die Software verwendet die erweiterte Datenprofilierungsfunktion, um Typen, Formate, Integrität und Wert von Daten für die Qualitätsprüfung zu analysieren. Seine leistungsstarke und intelligente Datenabgleichs-Engine wählt perfekte Übereinstimmungen mit minimalen falschen Übereinstimmungen.
Abgesehen von den oben genannten Funktionen bietet WinPure auch beeindruckende Grafiken für alle Daten, Gruppenspiele und Nicht-Spiele.
Es fungiert auch als Zusammenführungstool, das doppelte Datensätze zusammenfügt, um einen Hauptdatensatz zu generieren, der alle aktuellen Werte beibehalten kann. Darüber hinaus können Sie mit diesem Tool Regeln für die Stammdatenauswahl definieren und alle Datensätze sofort entfernen.
ÖffnenVerfeinern
OpenRefine ist ein kostenloses Open-Source-Tool, mit dem Sie Ihre chaotischen Daten in ein sauberes Format umwandeln können, das für Webdienste verwendet werden kann. Es verwendet Facetten, um große Datensätze zu bereinigen, und arbeitet mit gefilterten Datensatzansichten.
Mit Hilfe leistungsstarker Heuristiken kann das Tool ähnliche Werte zusammenführen, um alle Inkonsistenzen zu beseitigen. Es bietet Abgleichsdienste, damit Benutzer ihre Datensätze mit externen Datenbanken abgleichen können. Darüber hinaus können Sie mit diesem Tool bei Bedarf zur älteren Datensatzversion zurückkehren.
Außerdem können Benutzer den Betriebsverlauf auf einer aktualisierten Version wiedergeben. Wenn Sie sich Sorgen um die Datensicherheit machen, ist OpenRefine die richtige Option für Sie. Es bereinigt Ihre Daten auf Ihrem Computer, sodass für diesen Zweck keine Datenmigration in die Cloud erforderlich ist.
Trifacta Designer-Cloud

Während die Datenbereinigung komplex sein kann, macht Trifacta Designer Cloud es Ihnen einfacher. Es verwendet einen neuartigen Datenvorbereitungsansatz für die Datenbereinigung, damit Unternehmen den größtmöglichen Nutzen daraus ziehen können.
Seine benutzerfreundliche Oberfläche ermöglicht es technisch nicht versierten Benutzern, Daten für anspruchsvolle Analysen zu bereinigen und zu bereinigen. Jetzt können Unternehmen mehr aus ihren Daten machen, indem sie die ML-gestützten intelligenten Vorschläge der Trifacta Designer Cloud nutzen.
Darüber hinaus müssen sie weniger Zeit in diesen Prozess investieren und gleichzeitig mit weniger Fehlern umgehen. Es erfordert, dass Sie weniger Ressourcen verwenden, um mehr aus der Analyse herauszuholen.
Cloudingo
Machen Sie sich als Salesforce-Benutzer Sorgen um die Qualität der gesammelten Daten? Verwenden Sie Cloudingo, um Kundendaten zu bereinigen und nur die notwendigen Daten zu haben. Diese Anwendung vereinfacht die Verwaltung von Kundendaten mit Funktionen wie Deduplizierung, Import und Migration.
Hier können Sie die Zusammenführung von Datensätzen mit anpassbaren Filtern und Regeln steuern und Daten standardisieren. Löschen Sie nutzlose und inaktive Daten, aktualisieren Sie fehlende Datenpunkte und stellen Sie die Genauigkeit von US-Postanschriften sicher.
Außerdem können Unternehmen Cloudingo so planen, dass Daten automatisch dedupliziert werden, sodass Sie immer Zugriff auf saubere Daten haben. Die Synchronisierung der Daten mit Salesforce ist ein weiteres wichtiges Merkmal dieses Tools. Damit können Sie sogar Salesforce-Daten mit Informationen vergleichen, die in einer Tabelle gespeichert sind.
ZoomInfo

ZoomInfo ist ein Anbieter von Datenbereinigungslösungen, der zur Produktivität und Effektivität Ihres Teams beiträgt. Unternehmen können eine höhere Rentabilität erzielen, da diese Software duplizierungsfreie Daten an das CRM und die MATs des Unternehmens liefert.
Es vereinfacht das Datenqualitätsmanagement, indem es alle kostspieligen doppelten Daten entfernt. Benutzer können auch ihren CRM- und MAT-Perimeter mit ZoomInfo sichern. Es kann Daten innerhalb von Minuten mit automatischer Deduplizierung, Abgleich und Normalisierung bereinigen.
Benutzer dieser Anwendung genießen Flexibilität und Kontrolle über Übereinstimmungskriterien und zusammengeführte Ergebnisse. Es hilft Ihnen, ein kostengünstiges Datenspeichersystem aufzubauen, indem es alle Arten von Daten standardisiert.
Letzte Worte
Sie sollten sich Gedanken über die Qualität der Eingabedaten in Ihren Data-Science-Projekten machen. Es ist der grundlegende Feed für große Projekte wie maschinelles Lernen (ML), neuronale Netze für KI-basierte Automatisierung usw. Wenn der Feed fehlerhaft ist, überlegen Sie, was das Ergebnis solcher Projekte wäre.
Daher muss Ihr Unternehmen eine bewährte Datenbereinigungsstrategie anwenden und diese als Standardarbeitsanweisung (SOP) implementieren. Folglich wird sich auch die Qualität der Eingabedaten verbessern.
Wenn Sie genug mit Projekten, Marketing und Vertrieb beschäftigt sind, überlassen Sie die Datenbereinigung besser den Experten. Der Experte könnte eines der oben genannten Datenbereinigungstools sein.
Möglicherweise interessieren Sie sich auch für ein Service-Blueprint-Diagramm zur mühelosen Implementierung von Datenbereinigungsstrategien.