

Am 1. September 2020 stellte NVIDIA seine neue Reihe von Gaming-GPUs vor: die RTX 3000-Serie, basierend auf ihrer Ampere-Architektur. Wir besprechen, was neu ist, die KI-gestützte Software, die damit geliefert wird, und alle Details, die diese Generation wirklich großartig machen.
Inhaltsverzeichnis
Lernen Sie die GPUs der RTX 3000-Serie kennen

Die wichtigste Ankündigung von NVIDIA waren seine glänzenden neuen GPUs, die alle auf einem benutzerdefinierten 8-nm-Fertigungsprozess basieren und alle erhebliche Beschleunigungen sowohl bei der Rasterung als auch bei der Raytracing-Leistung bringen.
Am unteren Ende der Aufstellung gibt es die RTX3070, die 499 $ kostet. Es ist ein bisschen teuer für die billigste Karte, die NVIDIA bei der ersten Ankündigung vorgestellt hat, aber es ist ein absolutes Schnäppchen, wenn man erfährt, dass es die bestehende RTX 2080 Ti, eine Top-of-the-Line-Karte, die regelmäßig für über 1400 US-Dollar im Einzelhandel erhältlich ist, schlägt. Nach der Ankündigung von NVIDIA sanken jedoch die Verkaufspreise von Drittanbietern, und eine große Anzahl von ihnen wurde bei eBay in Panik für unter 600 US-Dollar verkauft.
Zum Zeitpunkt der Ankündigung gibt es keine soliden Benchmarks, daher ist unklar, ob die Karte wirklich objektiv „besser“ als eine 2080 Ti ist oder ob NVIDIA das Marketing ein wenig verdreht. Die ausgeführten Benchmarks lagen bei 4K und wahrscheinlich war RTX eingeschaltet, was die Lücke möglicherweise größer erscheinen lässt als bei rein gerasterten Spielen, da die Ampere-basierte 3000-Serie beim Raytracing mehr als doppelt so gut abschneidet wie Turing. Aber da Raytracing jetzt etwas ist, das die Leistung nicht mehr stark beeinträchtigt und in der neuesten Konsolengeneration unterstützt wird, ist es ein wichtiges Verkaufsargument, dass es für fast ein Drittel des Preises so schnell läuft wie das Flaggschiff der letzten Generation.
Auch ist unklar, ob der Preis so bleibt. Designs von Drittanbietern erhöhen den Preis regelmäßig um mindestens 50 US-Dollar, und bei der wahrscheinlich hohen Nachfrage wird es nicht überraschen, dass es im Oktober 2020 für 600 US-Dollar verkauft wird.
Gleich darüber befindet sich die RTX3080 bei 699 $, was doppelt so schnell sein sollte wie der RTX 2080 und etwa 25-30 % schneller als der 3080 sein sollte.
Am oberen Ende steht dann das neue Flaggschiff RTX3090, die komischerweise riesig ist. NVIDIA ist sich dessen bewusst und bezeichnet es als „BFGPU“, was nach Angaben des Unternehmens für „Big Ferocious GPU“ steht.

NVIDIA hat keine direkten Leistungskennzahlen angegeben, aber das Unternehmen hat gezeigt, dass es 8K-Spiele mit 60 FPS ausführt, was wirklich beeindruckend ist. Zugegeben, NVIDIA verwendet mit ziemlicher Sicherheit DLSS, um diese Marke zu erreichen, aber 8K-Gaming ist 8K-Gaming.
Natürlich wird es irgendwann eine 3060 und andere Variationen von eher budgetorientierten Karten geben, aber diese kommen normalerweise später hinzu.
Um die Dinger tatsächlich zu kühlen, brauchte NVIDIA ein überarbeitetes Kühlerdesign. Der 3080 ist für 320 Watt ausgelegt, was ziemlich hoch ist, also hat sich NVIDIA für ein Dual-Lüfter-Design entschieden, aber anstatt beide Lüfter vwinf unten zu platzieren, hat NVIDIA einen Lüfter am oberen Ende platziert, wo normalerweise die Rückplatte hingeht. Der Lüfter leitet die Luft nach oben zum CPU-Kühler und zur Oberseite des Gehäuses.

Gemessen daran, wie stark die Leistung durch schlechten Luftstrom in einem Gehäuse beeinträchtigt werden kann, ist dies absolut sinnvoll. Allerdings ist die Platine dadurch sehr beengt, was sich wahrscheinlich auf die Verkaufspreise von Drittanbietern auswirken wird.
DLSS: Ein Software-Vorteil
Raytracing ist nicht der einzige Vorteil dieser neuen Karten. Wirklich, es ist alles ein bisschen wie ein Hack – die RTX 2000-Serie und 3000-Serie ist im Vergleich zu älteren Kartengenerationen nicht viel besser darin, echtes Raytracing durchzuführen. Das Raytracing einer vollständigen Szene in 3D-Software wie Blender dauert in der Regel einige Sekunden oder sogar Minuten pro Frame, sodass ein Brute-Force in weniger als 10 Millisekunden nicht in Frage kommt.
Natürlich gibt es dedizierte Hardware für die Ausführung von Strahlenberechnungen, die als RT-Kerne bezeichnet werden, aber NVIDIA hat sich größtenteils für einen anderen Ansatz entschieden. NVIDIA hat die Entrauschungsalgorithmen verbessert, die es den GPUs ermöglichen, einen sehr billigen Single-Pass zu rendern, der schrecklich aussieht, und irgendwie – durch KI-Magie – das in etwas zu verwandeln, das ein Spieler sehen möchte. In Kombination mit traditionellen auf Rasterung basierenden Techniken sorgt es für ein angenehmes Erlebnis, das durch Raytracing-Effekte verstärkt wird.

Um dies jedoch schnell zu tun, hat NVIDIA KI-spezifische Verarbeitungskerne namens Tensor-Kerne hinzugefügt. Diese verarbeiten die gesamte Mathematik, die zum Ausführen von Modellen für maschinelles Lernen erforderlich ist, und zwar sehr schnell. Sie sind insgesamt Game-Changer für KI im Cloud-Server-Bereich, da KI von vielen Unternehmen ausgiebig genutzt wird.
Neben dem Entrauschen wird die Hauptverwendung der Tensor-Kerne für Gamer als DLSS oder Deep Learning Super Sampling bezeichnet. Es nimmt einen Frame mit niedriger Qualität auf und skaliert ihn auf eine vollständig native Qualität hoch. Dies bedeutet im Wesentlichen, dass Sie mit Bildraten auf 1080p-Ebene spielen können, während Sie ein 4K-Bild betrachten.
Dies hilft auch ziemlich viel bei der Raytracing-Leistung –Benchmarks von PCMag zeigen eine RTX 2080 Super Running Control in Ultra-Qualität, mit allen Raytracing-Einstellungen auf Maximum. Bei 4K kämpft es mit nur 19 FPS, aber mit eingeschaltetem DLSS erreicht es viel bessere 54 FPS. DLSS ist kostenlose Leistung für NVIDIA, die durch die Tensor-Kerne auf Turing und Ampere ermöglicht wird. Jedes Spiel, das dies unterstützt und GPU-beschränkt ist, kann allein durch Software ernsthafte Beschleunigungen erfahren.
DLSS ist nicht neu und wurde als Feature angekündigt, als die RTX 2000-Serie vor zwei Jahren auf den Markt kam. Damals wurde es von sehr wenigen Spielen unterstützt, da NVIDIA für jedes einzelne Spiel ein maschinelles Lernmodell trainieren und optimieren musste.
In dieser Zeit hat NVIDIA es jedoch komplett neu geschrieben und die neue Version DLSS 2.0 genannt. Es ist eine Allzweck-API, was bedeutet, dass jeder Entwickler sie implementieren kann, und sie wird bereits von den meisten Hauptversionen übernommen. Anstatt an einem Frame zu arbeiten, werden Bewegungsvektordaten aus dem vorherigen Frame übernommen, ähnlich wie bei TAA. Das Ergebnis ist viel schärfer als DLSS 1.0 und sieht in einigen Fällen sogar besser und schärfer aus als die native Auflösung, sodass es nicht viele Gründe gibt, es nicht einzuschalten.
Es gibt einen Haken: Wenn Szenen vollständig gewechselt werden, wie in Zwischensequenzen, muss DLSS 2.0 das allererste Bild mit 50 % Qualität rendern, während es auf die Bewegungsvektordaten wartet. Dies kann für einige Millisekunden zu einem winzigen Qualitätsabfall führen. Aber 99 % von allem, was Sie sich ansehen, werden richtig gerendert, und die meisten Leute bemerken es in der Praxis nicht.
Ampere-Architektur: Für KI gebaut
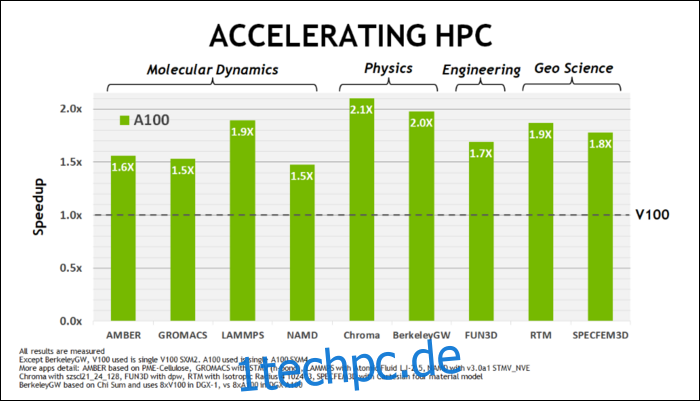
Ampere ist schnell. Wirklich schnell, besonders bei KI-Berechnungen. Der RT-Kern ist 1,7-mal schneller als Turing und der neue Tensor-Kern ist 2,7-mal schneller als Turing. Die Kombination der beiden ist ein echter Generationssprung in der Raytracing-Leistung.

Anfang Mai dieses Jahres NVIDIA hat die Ampere A100-GPU veröffentlicht, eine Rechenzentrums-GPU, die für die Ausführung von KI entwickelt wurde. Damit haben sie viel von dem detailliert beschrieben, was Ampere so viel schneller macht. Für Rechenzentrums- und Hochleistungs-Computing-Workloads ist Ampere im Allgemeinen etwa 1,7-mal schneller als Turing. Beim KI-Training ist es bis zu 6-mal schneller.
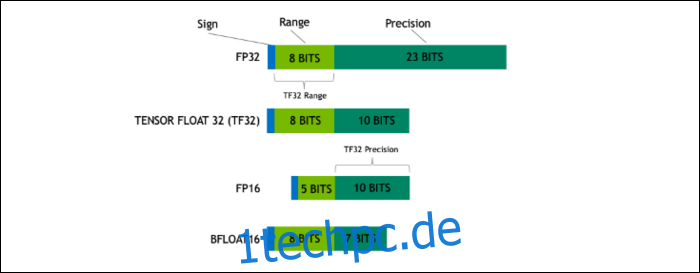
Mit Ampere verwendet NVIDIA ein neues Zahlenformat, das den Industriestandard „Floating-Point 32“ oder FP32 in einigen Workloads ersetzen soll. Unter der Haube nimmt jede Zahl, die Ihr Computer verarbeitet, eine vordefinierte Anzahl von Bits im Speicher ein, egal ob das 8 Bit, 16 Bit, 32, 64 oder noch mehr sind. Größere Zahlen sind schwieriger zu verarbeiten. Wenn Sie also eine kleinere Größe verwenden können, müssen Sie weniger verarbeiten.
FP32 speichert eine 32-Bit-Dezimalzahl und verwendet 8 Bit für den Bereich der Zahl (wie groß oder klein sie sein kann) und 23 Bit für die Genauigkeit. NVIDIAs Behauptung ist, dass diese 23 Präzisionsbits für viele KI-Arbeitslasten nicht unbedingt erforderlich sind und Sie mit nur 10 von ihnen ähnliche Ergebnisse und eine viel bessere Leistung erzielen können. Die Reduzierung der Größe auf nur 19 Bit statt 32 Bit macht bei vielen Berechnungen einen großen Unterschied.
Dieses neue Format heißt Tensor Float 32, und die Tensor Cores im A100 sind optimiert, um das seltsam große Format zu handhaben. Auf diese Weise erhalten sie zusätzlich zu den Chip-Shrinks und der Erhöhung der Kernanzahl die massive 6-fache Beschleunigung im KI-Training.
Zusätzlich zum neuen Zahlenformat sieht Ampere erhebliche Leistungsbeschleunigungen bei bestimmten Berechnungen wie FP32 und FP64. Diese führen nicht direkt zu mehr FPS für den Laien, aber sie sind Teil dessen, was es bei Tensor-Operationen insgesamt fast dreimal schneller macht.

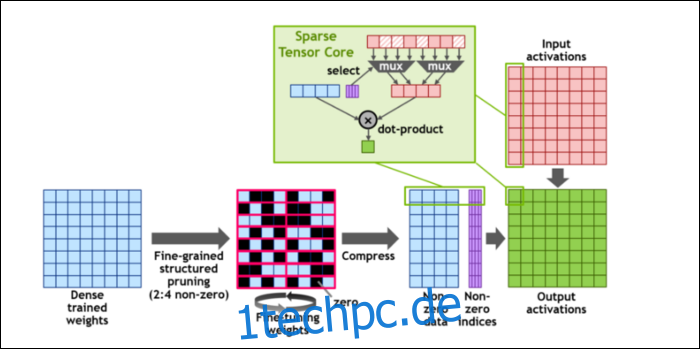
Um die Berechnungen noch weiter zu beschleunigen, haben sie das Konzept von eingeführt feinkörnige Struktur Sparsity, was ein sehr ausgefallenes Wort für ein ziemlich einfaches Konzept ist. Neuronale Netze arbeiten mit großen Listen von Zahlen, Gewichtungen genannt, die sich auf die endgültige Ausgabe auswirken. Je mehr Zahlen zu knacken sind, desto langsamer wird es.
Allerdings sind nicht alle diese Zahlen wirklich nützlich. Einige von ihnen sind buchstäblich nur Null und können im Grunde weggeworfen werden, was zu massiven Beschleunigungen führt, wenn Sie mehr Zahlen gleichzeitig knacken können. Sparsity komprimiert im Wesentlichen die Zahlen, was weniger Aufwand für Berechnungen erfordert. Der neue „Sparse Tensor Core“ wurde entwickelt, um mit komprimierten Daten zu arbeiten.
Trotz der Änderungen sagt NVIDIA, dass dies die Genauigkeit trainierter Modelle überhaupt nicht merklich beeinträchtigen sollte.
Bei Sparse-INT8-Berechnungen, einem der kleinsten Zahlenformate, liegt die Spitzenleistung einer einzelnen A100-GPU bei über 1,25 PetaFLOPs, eine erstaunlich hohe Zahl. Das gilt natürlich nur, wenn eine bestimmte Art von Zahl geknackt wird, aber es ist trotzdem beeindruckend.