
Daten sind das Lebenselixier eines jeden Unternehmens. Sie ist der Schlüssel zum Erfolg und unerlässlich, um Informationen zu sammeln, Entscheidungen zu treffen und Abläufe zu verbessern.
Ein Unternehmen ist für den täglichen Betrieb auf seine Daten und Anwendungen angewiesen. Aber was passiert, wenn eine ihrer Datenbanken oder Systeme ausfällt?
Alle kritischen Geschäftsinformationen und -daten könnten gefährdet sein.
Glücklicherweise gibt es Möglichkeiten, dies zu verhindern. Eine der effektivsten Methoden zum Schutz von Geschäftsdaten ist die Datenbankreplikation. Es ist etwas, an das sich jedes kleine, mittlere und große Unternehmen anpassen muss, um im Wettbewerb bestehen zu können.
In diesem Artikel werde ich erörtern, was Datenreplikation ist, wie sie funktioniert und andere wichtige Aspekte.
Also lasst uns anfangen!
Inhaltsverzeichnis
Was ist Datenbankreplikation?
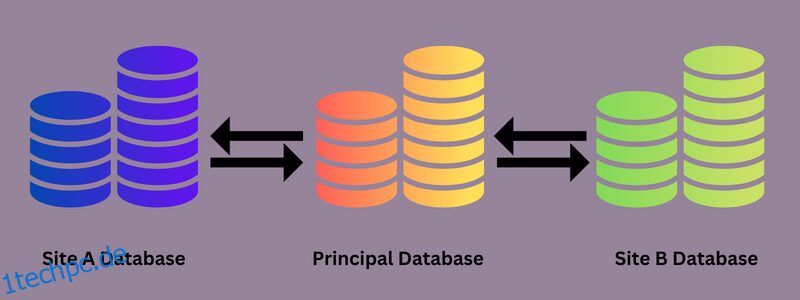
Das Übertragen von Daten aus einer Quelldatenbank in eine oder mehrere Zieldatenbanken wird als Datenbankreplikation bezeichnet. Häufig müssen Daten von einer Datenbank in eine andere kopiert oder gestreamt werden, sodass alle Benutzer auf synchronisierte Daten zugreifen können, unabhängig davon, welches System sie verwenden, um sie anzuzeigen.
Wenn sich Daten ändern, sorgt ein Datenreplikationstool dafür, dass die Änderungen auch in der Zieldatenbank implementiert werden. Dadurch entsteht ein verteiltes Datenspeichernetzwerk mit größerer Verfügbarkeit über mehrere Standorte hinweg, sodass jeder schnell auf wichtige und relevante Daten zugreifen kann.
Wenn Sie eine Datenreplikationslösung verwenden, werden Sie wahrscheinlich eine Verbesserung der Datenkonsistenz auf jedem Knoten, eine verringerte Datenredundanz, eine größere Datenzuverlässigkeit und schließlich eine Leistungssteigerung feststellen.
Die Datenbankreplikation kann in Echtzeit erfolgen, wenn Daten in der Quelldatenbank oder als Teil eines Batch-Vorgangs erstellt, bearbeitet und gelöscht werden.
Wie funktioniert die Datenreplikation?
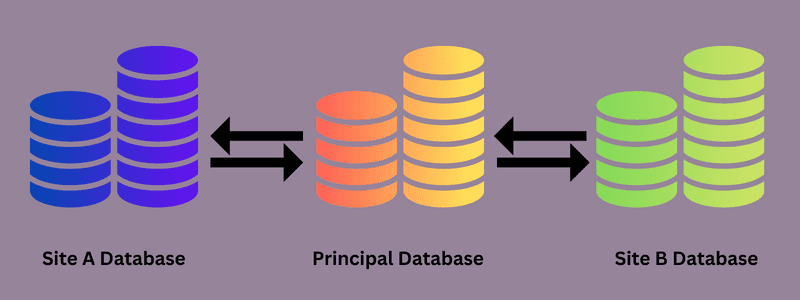
Die Datenbankreplikation kann einmalig oder als kontinuierlicher Prozess durchgeführt werden. Es umfasst alle Datenquellen einer Organisation, und ein verteiltes Datenbankmanagementsystem (DDBMS) wird verwendet, um Daten an alle Quellen zu übertragen oder zu verteilen.
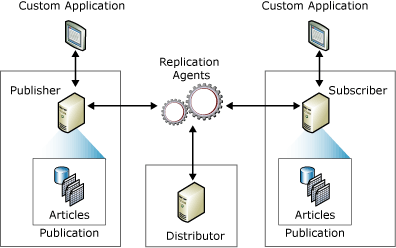
Alle Änderungen, Hinzufügungen und Löschungen, die in der Quelldatenbank vorgenommen werden, werden automatisch mit den anderen Zieldatenbanken synchronisiert, wenn diese Änderungen erforderlich sind. Gemäß dem herkömmlichen Publisher-Subscriber-Softwareparadigma sind ein oder mehrere „Publisher“ und „Subscriber“ am Datenreplikationsprozess beteiligt.
 Bildnachweis: Microsoft
Bildnachweis: Microsoft
Ein „Herausgeber“ ist ein System oder die Quelldatenbank, auf der Änderungen vorgenommen werden, und ein „Abonnent“ ist ein System, auf dem die Änderungen repliziert werden.
Alle Änderungen, die auf einem „Publisher“-System durchgeführt werden, werden dann auf „Subscriber“-Datenbanken repliziert. Benutzer können auch Änderungen in Abonnentendatenbanken vornehmen, die dann in der Herausgeberdatenbank repliziert werden. Dadurch werden die Änderungen an alle anderen Teilnehmer im Netzwerk verteilt, wenn das System bidirektional ist.
Darüber hinaus haben die meisten Abonnenten eine feste Verbindung mit dem Herausgeber, sodass Änderungen oder Upgrades automatisch ohne manuellen Eingriff erfolgen können. Diese Aktualisierungen können in regelmäßigen Abständen stapelweise erfolgen oder in Echtzeit ausgelöst und angewendet werden.
Arten der Datenbankreplikation
Einige der Arten der Datenbankreplikation sind:
#1. Full-Table-Replikation
Die vollständige Tabellenreplikation erstellt eine Kopie der vollständigen Quelldatenbank im Zielspeicher. Es verschiebt Zeilen vom Herausgeber zum Abonnenten, einschließlich neuer, geänderter und vorhandener Zeilen.
Dieser Replikationsansatz ist jedoch mit hohen Wartungskosten verbunden, da Rechenleistung und Netzwerkbandbreite erforderlich sind, um alles zu kopieren. Es belastet das Netzwerk und kann zu Replikationsverzögerungen führen, insbesondere wenn das Datenvolumen größer ist.
#2. Snapshot-Replikation
Bei dieser Datenbankreplikation wird ein Snapshot der Quelldatenbank verwendet, um Daten in der Zieldatenbank zu replizieren. Datenänderungen wie neu, aktualisiert oder gelöscht werden nicht berücksichtigt; Stattdessen erstellt es eine Kopie dessen, was es zu diesem Zeitpunkt sammelt.
Wenn es nur wenige Datenänderungen gibt, ist diese Replikationstechnik vorzuziehen. Sie ist erheblich schneller als die vollständige Tabellenreplikation, verfolgt jedoch keine endgültig gelöschten Daten.

#3. Replikation zusammenführen
Die Mergereplikation ist ein Prozess, der Datenbankobjekte und Daten mit Datenbanksynchronisierung von einer Datenbank in eine andere überträgt und verteilt. Es ist komplex, da dieser Prozess es Abonnenten und Herausgebern ermöglicht, die Datenbank zu ändern, was zu häufigen versionsbezogenen Datenkonflikten führt.
Auf den Servern bereitgestellte Merge-Agenten synchronisieren alle Änderungen und folgen einem vordefinierten Konfliktlösungsprozess, um Datenkonflikte zu lösen.
#4. Schlüsselbasierte inkrementelle Replikation
Die schlüsselbasierte inkrementelle Replikation überprüft Schlüssel oder Indizes in einer Datenbank, um nach Änderungen wie gelöscht, neu und aktualisiert zu suchen. Der Replikationsmechanismus kopiert dann nur die erforderlichen Replikationsschlüssel in die Replikatdatenbank, um die Änderungen seit der letzten Aktualisierung widerzuspiegeln. Diese Schlüssel sind normalerweise ein Zeitstempel, ein Datum oder eine ganze Zahl.
Da nur angezeigte Änderungen in die Replikatdatenbank repliziert werden, ist der Prozess schneller. Leider ermöglicht diese Methode keine endgültigen Löschungen, da der kritische Wert durch Löschen des primären Datenbankeintrags entfernt wird.
#5. Protokollbasierte inkrementelle Replikation
Diese Art der Datenbankreplikation dupliziert Daten gemäß der binären Protokolldatei der Datenbank. Beim Überprüfen der binären Protokolldatei erhalten Sie Informationen zu Änderungen, die an der primären Datenbank vorgenommen wurden, z. B. Aktualisierungen, Einfügungen oder Löschungen. Als Nächstes werden dieselben Änderungen oder Aktualisierungen in Ihrer Zieldatenbank durchgeführt.
Dies ist eine der am weitesten verbreiteten Methoden der Datenreplikation, da sie effizient ist, insbesondere für statische Datenbanken. Darüber hinaus wird es von den meisten Datenbankanbietern unterstützt, darunter Oracle, MongoDB, MySQL und PostgreSQL.
#6. Transaktionsreplikation
Wenn es eine neue Entwicklung in den Quelldaten gibt, verschiebt die Transaktionsreplikation alle vorhandenen Daten von der Quelldatenbank an den Zielspeicherort. Dann führt es dieselbe Transaktion in den Replikaten aus.
Obwohl es sich um eine effiziente Replikationsmethode handelt, werden die Modelle hauptsächlich in Leseaktivitäten verwendet und erlauben möglicherweise keine Erstellungs-, Lösch- oder Aktualisierungsvorgänge.
Warum ist die DB-Replikation wichtig?

Die Datenbankreplikation ist aus folgenden Gründen wichtig:
Datenzuverlässigkeit und -verfügbarkeit
Die Datenreplikation fördert die Datenverfügbarkeit. Es spielt eine wichtige Rolle, wenn ein Server unter ungewöhnlichen Umständen ausfällt, indem es Datenbanksicherungen bereitstellt. Auf diese Weise kann es Ihnen den Tag retten, da Daten an anderen Orten verfügbar sind. Außerdem wird die Datenzuverlässigkeit verbessert, indem relevante, aktuelle Daten sicher auf mehreren Servern gespeichert werden.
Notfallwiederherstellung
Die Datenbankreplikation ist während eines Serverausfallszenarios hilfreich. Es ist eine wunderbare Technik für das Disaster Management und die Wiederherstellung, da es Daten und aktuelle Änderungen an anderen Serverstandorten repliziert und speichert, anstatt sich auf einen einzelnen Server zu verlassen.
Serverleistung
Der Datenzugriff ist viel schneller, wenn Daten auf mehreren Servern verarbeitet und betrieben werden. Darüber hinaus können Administratoren Verarbeitungszyklen auf dem ursprünglichen Server für ressourcenintensivere Schreibvorgänge freigeben, indem sie alle Datenlesevorgänge an eine Replik leiten.
Bessere Netzwerkleistung
Das Aufbewahren mehrerer Kopien derselben Daten an verschiedenen Orten kann die Datenzugriffslatenz verringern, da Sie die relevanten Daten möglicherweise von dem Ort abrufen, an dem die Transaktion ausgeführt wird.
Beispielsweise können Benutzer in europäischen Ländern beim Zugriff auf Daten aus australischen Rechenzentren Latenzprobleme verspüren. Daher kann die Platzierung einer Kopie dieser Daten in der Nähe des Benutzers die Zugriffszeiten verbessern und gleichzeitig die Netzwerkbelastung ausgleichen.
Verbesserte Leistung des Testsystems

Die Datenbankreplikation rationalisiert die Datenverteilung und -synchronisierung für Testsysteme, die einen schnellen Zugriff für eine schnellere Entscheidungsfindung erfordern.
Datenbanksicherung vs. Datenbankreplikation
Sowohl die Datenbanksicherung als auch die Datenbankreplikation unterscheiden sich in mehrfacher Hinsicht. Einige von ihnen sind wie folgt:
- Datenbanksicherungen müssen rekonstruiert und wiederhergestellt werden, bevor sie verwendet werden können. Im Gegensatz zu Datenbanksicherungen erfordert die Datenreplikation keine Rekonstruktion und kann sofort verwendet werden.
- Datenbanksicherungen bestehen aus Dateien oder Ordnern, Datenbankdatendateien und Anwendungsdateien, abhängig von den Sicherungs-/Wiederherstellungsprotokollen der Organisation. Im Gegensatz dazu wird die Datenbankreplikation häufig verwendet, um komplette Volumes oder Dateisysteme, Datenbanken und Anwendungen zu duplizieren.
- Backup und Replikation sind beides Datenschutzmaßnahmen. Ersteres betrifft das Senken von Recovery Point Objectives (RPOs) und das Verhindern von Datenverlust. Während letzteres darauf ausgelegt ist, Recovery Time Objectives (RTOs) zu reduzieren, die Geschäftskontinuität zu gewährleisten und Ausfallzeiten zu minimieren.
- Die Datenbanksicherung ist eine kostengünstige Methode, um einen vollständigen Datenverlust zu vermeiden. Sie ist für die Compliance unerlässlich und garantiert nicht den Fortbestand des Betriebs. Im Gegenteil, die Replikation stellt sicher, dass Geschäftsanwendungen und -prozesse auch nach einem Stromausfall immer verfügbar sind.
- Bei der Datenbanksicherung geht es um Compliance und granulare Wiederherstellung, wie z. B. die langfristige Speicherung von Unternehmensunterlagen. Andererseits konzentrieren sich Datenbankreplikation und -wiederherstellung auf die Notfallwiederherstellung, die schnelle und einfache Wiederaufnahme des Betriebs nach einem Ausfall oder einer Beschädigung.
- Datenbanksicherungen werden häufig am Arbeitsplatz für alles verwendet, von Produktionsservern bis hin zu Desktops. Im Gegenteil, die Datenbankreplikation wird häufig für unternehmenskritische Anwendungen verwendet, die immer verfügbar sein müssen.
Techniken der Datenbankreplikation

Organisationen können Daten replizieren, indem sie eine präzise Technik zum Verschieben der Daten befolgen. Diese Strategien unterscheiden sich von den oben beschriebenen Replikationstypen.
#1. Vollständige Datenbankreplikation
Die vollständige Datenbankreplikation repliziert eine vollständige Datenbank zur Verwendung auf verschiedenen Hosts. Dies gewährleistet die größtmögliche Datenredundanz und -verfügbarkeit. Für globale Unternehmen ermöglicht dies Benutzern in Asien den Zugriff auf die gleichen Daten wie ihre Kollegen in Nordamerika mit der gleichen Geschwindigkeit. Wenn der asiatische Server ausfällt, können Benutzer ihre europäischen oder nordamerikanischen Server als Backup verwenden.
Der Nachteil dieser Technik ist jedoch die langsame Aktualisierungsprozedur. Es ist auch schwierig, jeden Dateispeicherort konsistent zu halten, was wichtig ist, wenn sich die Daten ständig ändern.
#2. Partielle Datenbankreplikation
Partielle Datenbankreplikation ist der Prozess, bei dem Daten in einer Datenbank in Teile getrennt und an verschiedenen Orten gespeichert werden, abhängig von der Relevanz der einzelnen Sites.
Versicherungssachverständige, Finanzberater und Vertriebsprofis profitieren von der teilweisen Replikation. Diese Mitarbeiter können die Teildatenbanken auf anderen Geräten oder Laptops mitführen und routinemäßig mit einem zentralen Server synchronisieren.
Für Analysten kann es wirtschaftlicher sein, europäische Daten in Europa, australische Daten in Australien usw. aufzubewahren. Das bedeutet, die Daten in der Nähe der Verbraucher zu halten und gleichzeitig einen umfassenden Datensatz in der Zentrale für hochrangige Analysen vorzuhalten.
Nachteile der Datenbankreplikation

Obwohl die Datenreplikation einen erheblichen Mehrwert für Ihre Arbeit und Ihr Unternehmen bringen kann, bringt sie auch die folgenden Nachteile mit sich:
Höhere Kosten
Wenn Daten repliziert und an mehreren Orten gespeichert werden, werden mehr Speicherplatz und Rechenressourcen benötigt. Dieser erhöhte Bedarf an Hardware- und Rechenressourcen kann zu höheren Kosten führen, einschließlich der Anschaffung und Wartung zusätzlicher Speichergeräte, Server und Netzwerkinfrastruktur.
Zeitbeschränkungen
Die Datenreplikation ist ein komplexer Prozess, der das Kopieren von Daten von einem Speicherort an mehrere andere Speicherorte und das Aufrechterhalten der Konsistenz über alle Kopien hinweg umfasst. Dieser Prozess kann viel Zeit in Anspruch nehmen, insbesondere für Organisationen, die große Datenmengen replizieren müssen.
Bandbreite
Mit zunehmendem Datenvolumen, das repliziert wird, steigen auch die Bandbreitenanforderungen, was die Netzwerkressourcen belasten kann.
Inkonsistente Daten
Beim Replizieren von Daten in einer verteilten Umgebung besteht die Gefahr, dass die Daten nicht mehr synchron sind, wenn Aktualisierungen nicht konsistent über alle Replikate hinweg durchgeführt werden. Dies kann zu inkonsistenten Daten führen und zusätzliche Anstrengungen zur Lösung erfordern.
Anwendungsfälle der Datenbankreplikation

Es gibt viele Fälle, in denen die Datenreplikation verwendet werden kann, wie zum Beispiel:
Lastverteilung
Durch die Replikation von Daten auf mehrere Server wird die Last auf diese Server verteilt, um die Leistung zu verbessern. So stellt Load Balancing sicher, dass ein einzelner Server nicht durch zu viele Anfragen überlastet wird und das System auch in Zeiten mit hohem Traffic verfügbar und reaktionsfähig bleibt.
Datenspeicherung
Ein Data Warehouse ist ein zentrales Repository zum Speichern großer Datenmengen aus mehreren Quellen. Durch die Replikation von Daten aus diesen Quellen in das Data Warehouse können Unternehmen ihre Daten zentral und organisiert analysieren und Berichte darüber erstellen.
Überregionaler Einsatz
Durch die Replikation von Daten in mehrere Regionen können Unternehmen den Datenzugriff und die Redundanz verbessern. Kommt es in einer Region zu einem Ausfall, kann von einer anderen Region weiterhin auf die Daten zugegriffen werden. Darüber hinaus kann das Vorhandensein von Daten in mehreren Regionen dazu beitragen, die Zugriffsgeschwindigkeit für Benutzer in verschiedenen Teilen der Welt zu verbessern.
Sicherung und Archivierung
Die Replikation von Daten auf Sekundärspeicher hilft Unternehmen, eine langfristige Kopie ihrer Daten zu behalten. Dies ermöglicht ihnen einen einfachen Zugriff auf die Daten und stellt sicher, dass diese auch bei einem Ausfall des Primärspeichers nicht verloren gehen.
Datensynchronisation
Die Replikation von Daten zwischen mehreren Systemen trägt dazu bei, dass die Daten überall synchronisiert, konsistent und aktuell bleiben. Dies ist wichtig für Anwendungen wie E-Commerce, wo dieselben Daten von mehreren Systemen aus zugänglich sein müssen.
Standortübergreifende Zusammenarbeit
Durch die Replikation von Daten zwischen mehreren Standorten können Unternehmen Daten in Echtzeit gemeinsam nutzen, was die Zusammenarbeit und gesteigerte Produktivität ermöglicht. Dies ist besonders nützlich für Organisationen mit Teams an mehreren Standorten oder Unternehmen, die Daten mit Partnern oder Kunden teilen müssen.
Lernmittel
Hier sind einige Lernressourcen, die Ihnen helfen, das Thema besser zu verstehen:
#1. Datenbankreplikation von Bettina Kemme
Dieses Buch hilft Ihnen dabei, verschiedene Kontrollmechanismen für Nebenläufigkeit und Replikate sowie damit verbundene Probleme zu verstehen.
#2. Datenbankreplikation: Ein vollständiger Leitfaden:
Dieses Buch bereitet Sie auf die Herausforderungen bei der Datenbankreplikation vor, indem es Ihre Fragen erklärt und beantwortet.
Abschluss
Die Datenreplikation ist eine unterschätzte Strategie in der schnell wachsenden, datengesteuerten Welt von heute. Wenn Sie also ein Geschäftsinhaber sind, werden Sie von den Vorteilen überrascht sein.
Da die Zahl der Quellen und Ziele jedoch wächst, müssen Unternehmen bereit sein, sich den damit verbundenen Herausforderungen zu stellen. Aus diesem Grund kann eine zuverlässige, skalierbare Datenreplikationsstrategie für Sie nützlich sein.
Sie können auch einige nützliche Datenbanküberwachungssoftware erkunden, um die Leistung zu analysieren.