
Erfahren Sie alles, was Sie über die explorative Datenanalyse wissen müssen, einen kritischen Prozess, der verwendet wird, um Trends und Muster zu entdecken und Datensätze mit Hilfe von statistischen Zusammenfassungen und grafischen Darstellungen zusammenzufassen.
Wie jedes Projekt ist ein Data-Science-Projekt ein langer Prozess, der Zeit, gute Organisation und gewissenhafte Einhaltung mehrerer Schritte erfordert. Die explorative Datenanalyse (EDA) ist einer der wichtigsten Schritte in diesem Prozess.
Daher gehen wir in diesem Artikel kurz darauf ein, was explorative Datenanalyse ist und wie Sie sie mit R durchführen können!
Inhaltsverzeichnis
Was ist explorative Datenanalyse?
Bei der explorativen Datenanalyse werden die Eigenschaften eines Datensatzes untersucht und untersucht, bevor er einer Anwendung zugeführt wird, sei es ausschließlich für Unternehmen, Statistik oder maschinelles Lernen.

Diese Zusammenfassung der Art der Informationen und ihrer wichtigsten Besonderheiten erfolgt in der Regel durch visuelle Methoden wie grafische Darstellungen und Tabellen. Die Praxis wird im Voraus genau durchgeführt, um das Potenzial dieser Daten abzuschätzen, die in Zukunft eine komplexere Behandlung erfahren werden.
Das EDA erlaubt daher:
- Formulieren Sie Hypothesen für die Nutzung dieser Informationen;
- Untersuchen Sie versteckte Details in der Datenstruktur;
- Identifizieren Sie fehlende Werte, Ausreißer oder abnormales Verhalten;
- Entdecken Sie Trends und relevante Variablen als Ganzes;
- Verwerfen Sie irrelevante Variablen oder Variablen, die mit anderen korrelieren;
- Bestimmen Sie die zu verwendende formale Modellierung.
Was ist der Unterschied zwischen deskriptiver und explorativer Datenanalyse?
Es gibt zwei Arten der Datenanalyse, die deskriptive Analyse und die explorative Datenanalyse, die trotz unterschiedlicher Ziele Hand in Hand gehen.
Während sich die erste auf die Beschreibung des Verhaltens von Variablen konzentriert, z. B. Mittelwert, Median, Modus usw.
Die explorative Analyse zielt darauf ab, Beziehungen zwischen Variablen zu identifizieren, vorläufige Erkenntnisse zu gewinnen und die Modellierung auf die gängigsten Paradigmen des maschinellen Lernens auszurichten: Klassifizierung, Regression und Clustering.
Gemeinsam können sich beide mit grafischer Darstellung befassen; Allerdings versucht nur die explorative Analyse, umsetzbare Erkenntnisse zu gewinnen, d. h. Erkenntnisse, die den Entscheidungsträger zum Handeln veranlassen.
Während die explorative Datenanalyse versucht, Probleme zu lösen und Lösungen zu finden, die die Modellierungsschritte leiten, zielt die deskriptive Analyse, wie der Name schon sagt, nur darauf ab, eine detaillierte Beschreibung des betreffenden Datensatzes zu erstellen.
Deskriptive AnalyseExplorative DatenanalyseAnalysiert VerhaltenAnalysiert Verhalten und BeziehungenBietet eine Zusammenfassung Führt zu Spezifikation und AktionenOrganisiert Daten in Tabellen und DiagrammenOrganisiert Daten in Tabellen und DiagrammenHat keine signifikante ErklärungskraftHat eine signifikante Erklärungskraft
Einige praktische Anwendungsfälle von EDA
#1. Digitales Marketing
Digitales Marketing hat sich von einem kreativen Prozess zu einem datengesteuerten Prozess entwickelt. Marketingorganisationen verwenden explorative Datenanalysen, um die Ergebnisse von Kampagnen oder Bemühungen zu ermitteln und um Verbraucherinvestitionen und Targeting-Entscheidungen zu lenken.
Demografische Studien, Kundensegmentierung und andere Techniken ermöglichen es Marketingfachleuten, große Mengen an Kauf-, Umfrage- und Paneldaten von Verbrauchern zu verwenden, um strategisches Marketing zu verstehen und zu kommunizieren.
Web Exploratory Analytics ermöglicht es Marketern, Informationen auf Sitzungsebene über Interaktionen auf einer Website zu sammeln. Google Analytics ist ein Beispiel für ein kostenloses und beliebtes Analysetool, das Vermarkter zu diesem Zweck verwenden.
Zu den im Marketing häufig verwendeten explorativen Techniken gehören Marketing-Mix-Modellierung, Preis- und Werbeanalysen, Verkaufsoptimierung und explorative Kundenanalysen, z. B. Segmentierung.
#2. Explorative Portfolioanalyse
Eine gängige Anwendung der explorativen Datenanalyse ist die explorative Portfolioanalyse. Eine Bank oder Kreditagentur hat eine Sammlung von Konten mit unterschiedlichem Wert und Risiko.
Konten können je nach sozialem Status des Inhabers (reich, Mittelklasse, arm usw.), geografischer Lage, Nettovermögen und vielen anderen Faktoren unterschiedlich sein. Der Kreditgeber muss die Rendite des Kredits mit dem Ausfallrisiko für jeden Kredit abwägen. Dann stellt sich die Frage, wie man das Portfolio als Ganzes bewertet.
Der Kredit mit dem geringsten Risiko kann für sehr wohlhabende Menschen bestimmt sein, aber es gibt eine sehr begrenzte Anzahl von wohlhabenden Menschen. Auf der anderen Seite können viele arme Menschen Kredite vergeben, aber mit einem höheren Risiko.
Die explorative Datenanalyselösung kann die Zeitreihenanalyse mit vielen anderen Problemen kombinieren, um zu entscheiden, wann Geld an diese verschiedenen Segmente von Kreditnehmern oder den Kreditzins verliehen werden soll. Zinsen werden Mitgliedern eines Portfoliosegments berechnet, um Verluste zwischen Mitgliedern dieses Segments zu decken.
#3. Explorative Risikoanalyse
Vorhersagemodelle im Bankwesen werden entwickelt, um Gewissheit über Risikobewertungen für einzelne Kunden zu geben. Kredit-Scores sollen das säumige Verhalten einer Person vorhersagen und werden häufig verwendet, um die Kreditwürdigkeit jedes Antragstellers zu beurteilen.
Darüber hinaus werden Risikoanalysen in der Wissenschaft und der Versicherungswirtschaft durchgeführt. Es wird auch häufig in Finanzinstituten wie Online-Payment-Gateway-Unternehmen verwendet, um zu analysieren, ob eine Transaktion echt oder betrügerisch ist.
Zu diesem Zweck verwenden sie die Transaktionshistorie des Kunden. Es wird häufiger bei Kreditkartenkäufen verwendet; Wenn das Transaktionsvolumen des Kunden plötzlich ansteigt, erhält der Kunde einen Bestätigungsanruf, wenn er die Transaktion initiiert hat. Es hilft auch, Verluste aufgrund solcher Umstände zu reduzieren.
Explorative Datenanalyse mit R
Das erste, was Sie zum Ausführen von EDA mit R benötigen, ist das Herunterladen von R Base und R Studio (IDE), gefolgt von der Installation und dem Laden der folgenden Pakete:
#Installing Packages
install.packages("dplyr")
install.packages("ggplot2")
install.packages("magrittr")
install.packages("tsibble")
install.packages("forecast")
install.packages("skimr")
#Loading Packages
library(dplyr)
library(ggplot2)
library(magrittr)
library(tsibble)
library(forecast)
library(skimr)
Für dieses Tutorial verwenden wir einen in R integrierten Wirtschaftsdatensatz, der jährliche Wirtschaftsindikatordaten der US-Wirtschaft bereitstellt, und ändern seinen Namen der Einfachheit halber in econ:
econ <- ggplot2::economics
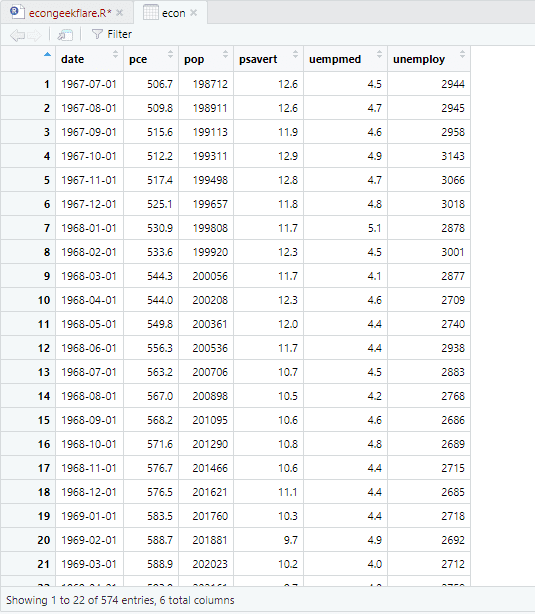
Um die deskriptive Analyse durchzuführen, verwenden wir das Paket skimr, das diese Statistiken auf einfache und übersichtliche Weise berechnet:
#Descriptive Analysis skimr::skim(econ)

Sie können auch die Zusammenfassungsfunktion für die deskriptive Analyse verwenden:
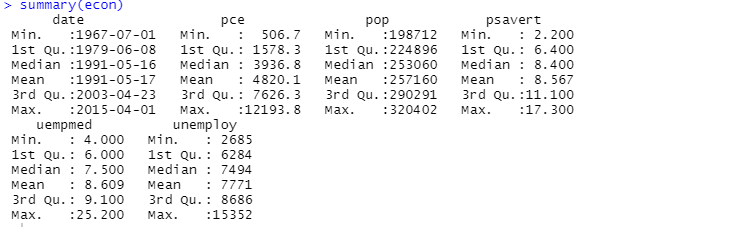
Hier zeigt die deskriptive Analyse 547 Zeilen und 6 Spalten im Datensatz. Der Mindestwert gilt für den 1. Juli 1967 und der Höchstwert für den 1. April 2015. Ebenso zeigt es auch den Mittelwert und die Standardabweichung an.
Jetzt haben Sie eine grundlegende Vorstellung davon, was sich im econ-Datensatz befindet. Lassen Sie uns ein Histogramm der Variablen uempmed zeichnen, um die Daten besser zu betrachten:
#Histogram of Unemployment econ %>% ggplot2::ggplot() + ggplot2::aes(x = uempmed) + ggplot2::geom_histogram() + labs(x = "Unemployment", title = "Monthly Unemployment Rate in US between 1967 to 2015")
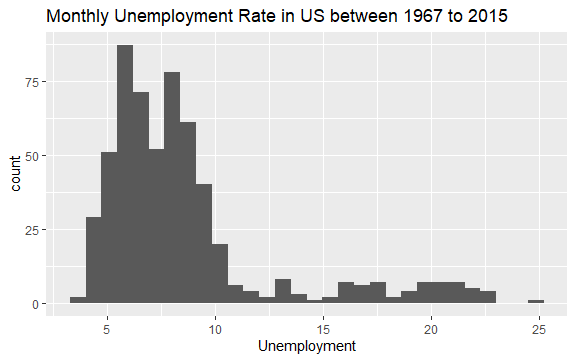
Die Verteilung des Histogramms zeigt, dass es rechts einen länglichen Schwanz hat; Das heißt, es gibt möglicherweise einige Beobachtungen dieser Variablen mit „extremeren“ Werten. Es stellt sich die Frage: In welchem Zeitraum fanden diese Werte statt und wie ist der Trend der Variablen?
Der direkteste Weg, den Trend einer Variablen zu erkennen, ist ein Liniendiagramm. Unten erzeugen wir ein Liniendiagramm und fügen eine Glättungslinie hinzu:
#Line Graph of Unemployment econ %>% ggplot2::autoplot(uempmed) + ggplot2::geom_smooth()
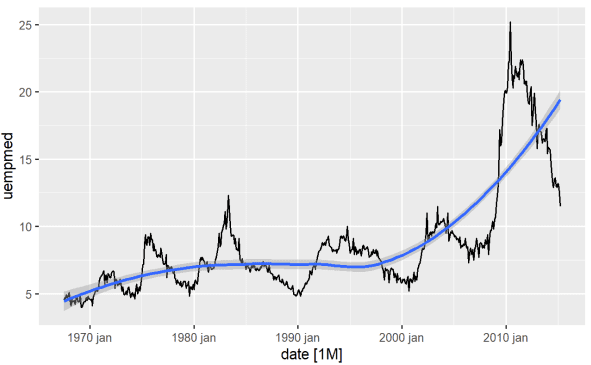
Anhand dieser Grafik können wir feststellen, dass es in den letzten Beobachtungen aus dem Jahr 2010 in jüngster Zeit eine Tendenz zu einem Anstieg der Arbeitslosigkeit gibt, der die in den vergangenen Jahrzehnten beobachtete Geschichte übertrifft.
Ein weiterer wichtiger Punkt, insbesondere in ökonometrischen Modellierungskontexten, ist die Stationarität der Reihe; das heißt, sind Mittelwert und Varianz über die Zeit konstant?
Wenn diese Annahmen auf eine Variable nicht zutreffen, sagen wir, dass die Reihe eine Einheitswurzel (nicht stationär) hat, sodass die Schocks, denen die Variable ausgesetzt ist, einen dauerhaften Effekt erzeugen.
Dies scheint für die betreffende Variable, die Dauer der Arbeitslosigkeit, der Fall gewesen zu sein. Wir haben gesehen, dass sich die Schwankungen der Variablen erheblich verändert haben, was starke Auswirkungen auf Wirtschaftstheorien hat, die sich mit Zyklen befassen. Aber wie können wir, abgesehen von der Theorie, praktisch überprüfen, ob die Variable stationär ist?
Das Prognosepaket hat eine hervorragende Funktion, die es ermöglicht, Tests wie ADF, KPSS und andere anzuwenden, die bereits die Anzahl der Unterschiede zurückgeben, die erforderlich sind, damit die Serie stationär ist:
#Using ADF test for checking stationarity forecast::ndiffs( x = econ$uempmed, test = "adf")

Hier zeigt der p-Wert größer als 0,05, dass die Daten nicht stationär sind.
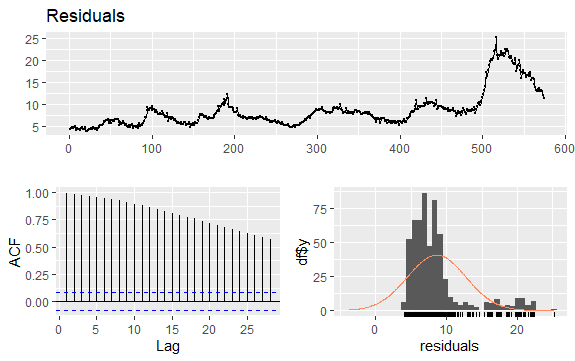
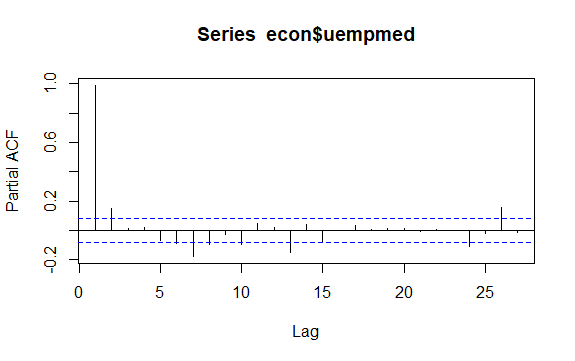
Ein weiteres wichtiges Thema bei Zeitreihen ist die Identifizierung möglicher Korrelationen (der linearen Beziehung) zwischen den verzögerten Werten der Reihe. Die ACF- und PACF-Korrelogramme helfen bei der Identifizierung.
Da die Reihe keine Saisonabhängigkeit aufweist, aber einen bestimmten Trend aufweist, sind die anfänglichen Autokorrelationen tendenziell groß und positiv, da die zeitlich nahen Beobachtungen auch einen nahen Wert haben.
Daher neigt die Autokorrelationsfunktion (ACF) einer Trendzeitreihe dazu, positive Werte zu haben, die langsam abnehmen, wenn die Verzögerungen zunehmen.
#Residuals of Unemployment checkresiduals(econ$uempmed) pacf(econ$uempmed)
Fazit
Wenn wir mehr oder weniger saubere, also bereits bereinigte Daten in die Hände bekommen, sind wir sofort versucht, in die Modellbauphase einzutauchen, um erste Ergebnisse zu zeichnen. Sie müssen dieser Versuchung widerstehen und mit der explorativen Datenanalyse beginnen, die einfach ist und uns dabei hilft, aussagekräftige Erkenntnisse aus den Daten zu gewinnen.
Sie können auch einige der besten Ressourcen erkunden, um Statistiken für Data Science zu lernen.