

Sie können Text aus Bildern in der Linux-Befehlszeile mit der Tesseract-OCR-Engine extrahieren. Es ist schnell, genau und funktioniert in etwa 100 Sprachen. So verwenden Sie es.
Inhaltsverzeichnis
Optische Zeichenerkennung
Optische Zeichenerkennung (OCR) ist die Fähigkeit, Wörter in einem Bild zu betrachten und zu finden und sie dann als bearbeitbaren Text zu extrahieren. Diese einfache Aufgabe für den Menschen ist für Computer sehr schwierig. Die ersten Bemühungen waren, gelinde gesagt, klobig. Computer gerieten oft in Verwirrung, wenn Schrift oder Größe nicht dem Geschmack der OCR-Software entsprachen.
Trotzdem wurden die Pioniere auf diesem Gebiet immer noch hoch geschätzt. Wenn Sie die elektronische Kopie eines Dokuments verloren haben, aber noch über eine gedruckte Version verfügen, kann OCR eine elektronische, bearbeitbare Version neu erstellen. Auch wenn die Ergebnisse nicht hundertprozentig genau waren, war dies dennoch eine große Zeitersparnis.
Mit etwas manuellem Aufräumen haben Sie Ihr Dokument wieder. Die Leute verzeihen die Fehler, die sie machten, weil sie die Komplexität der Aufgabe verstanden hatten, mit der ein OCR-Paket konfrontiert war. Außerdem war es besser, als das gesamte Dokument erneut einzugeben.
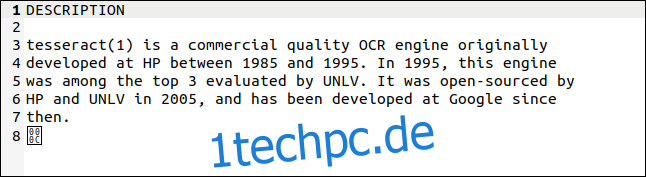
Seitdem haben sich die Dinge deutlich verbessert. Die Tesseract OCR-Anwendung, geschrieben von Hewlett Packard, begann in den 1980er Jahren als kommerzielle Anwendung. Es wurde 2005 als Open Source veröffentlicht und wird jetzt unterstützt von Google. Es verfügt über mehrsprachige Funktionen, gilt als eines der genauesten verfügbaren OCR-Systeme und Sie können es kostenlos verwenden.
Installieren von Tesseract OCR
Um Tesseract OCR unter Ubuntu zu installieren, verwenden Sie diesen Befehl:
sudo apt-get install tesseract-ocr

Auf Fedora lautet der Befehl:
sudo dnf install tesseract

Auf Manjaro müssen Sie Folgendes eingeben:
sudo pacman -Syu tesseract

Verwenden von Tesseract OCR
Wir werden Tesseract OCR vor eine Reihe von Herausforderungen stellen. Unser erstes Bild, das Text enthält, ist ein Auszug aus Erwägungsgrund 63 des Allgemeine Datenschutzbestimmungen. Mal sehen, ob OCR dies lesen kann (und wach bleibt).

Es ist ein kniffliges Bild, weil jeder Satz mit einer schwachen hochgestellten Zahl beginnt, die in Gesetzesdokumenten typisch ist.
Wir müssen dem tesseract-Befehl einige Informationen geben, darunter:
Der Name der Bilddatei, die verarbeitet werden soll.
Der Name der Textdatei, die erstellt wird, um den extrahierten Text aufzunehmen. Wir müssen die Dateierweiterung nicht angeben (sie wird immer .txt sein). Existiert bereits eine Datei mit demselben Namen, wird diese überschrieben.
Wir können die Option –dpi verwenden, um tesseract mitzuteilen, was die Punkte pro Zoll (dpi) Auflösung des Bildes ist. Wenn wir keinen dpi-Wert angeben, versucht tesseract, ihn herauszufinden.
Unsere Bilddatei heißt „recital-63.png“ und hat eine Auflösung von 150 dpi. Wir werden daraus eine Textdatei namens „recital.txt“ erstellen.
Unser Befehl sieht so aus:
tesseract recital-63.png recital --dpi 150

Die Ergebnisse sind sehr gut. Das einzige Problem sind die hochgestellten Zeichen – sie waren zu schwach, um richtig gelesen zu werden. Eine gute Bildqualität ist entscheidend, um gute Ergebnisse zu erzielen.

tesseract hat die hochgestellten Zahlen als Anführungszeichen (“) und Gradzeichen (°) interpretiert, aber der eigentliche Text wurde perfekt extrahiert (die rechte Seite des Bildes musste hier beschnitten werden).
Das letzte Zeichen ist ein Byte mit dem hexadezimalen Wert 0x0C, bei dem es sich um einen Wagenrücklauf handelt.
Unten ist ein weiteres Bild mit Text in verschiedenen Größen und sowohl fett als auch kursiv.

Der Name dieser Datei ist „bold-italic.png“. Wir möchten eine Textdatei namens „bold.txt“ erstellen, daher lautet unser Befehl:
tesseract bold-italic.png bold --dpi 150

Dieser stellte keine Probleme dar und der Text wurde perfekt extrahiert.
Verwendung verschiedener Sprachen
Tesseract OCR unterstützt rund 100 Sprachen. Um eine Sprache zu verwenden, müssen Sie sie zuerst installieren. Wenn Sie die gewünschte Sprache in der Liste finden, notieren Sie sich deren Abkürzung. Wir werden Support für Walisisch installieren. Die Abkürzung ist „cym“, die Abkürzung für „Cymru“, was Walisisch bedeutet.
Das Installationspaket heißt „tesseract-ocr-“ mit der Sprachabkürzung am Ende. Um die walisische Sprachdatei in Ubuntu zu installieren, verwenden wir:
sudo apt-get install tesseract-ocr-cym

Das Bild mit dem Text ist unten. Es ist die erste Strophe der walisischen Nationalhymne.

Mal sehen, ob Tesseract OCR der Herausforderung gewachsen ist. Wir verwenden die Option -l (Sprache), um tesseract die Sprache mitzuteilen, in der wir arbeiten möchten:
tesseract hen-wlad-fy-nhadau.png anthem -l cym --dpi 150

tesseract kommt perfekt zurecht, wie im extrahierten Text unten gezeigt. Da iawn, Tesseract OCR.

Wenn Ihr Dokument zwei oder mehr Sprachen enthält (z. B. ein Wörterbuch von Walisisch-Englisch), können Sie tesseract mit einem Pluszeichen (+) anweisen, eine weitere Sprache hinzuzufügen:
tesseract image.png textfile -l eng+cym+fra
Verwenden von Tesseract OCR mit PDFs
Der Befehl tesseract wurde für die Arbeit mit Bilddateien entwickelt, kann jedoch keine PDFs lesen. Wenn Sie jedoch Text aus einer PDF-Datei extrahieren müssen, können Sie zuerst ein anderes Dienstprogramm verwenden, um eine Reihe von Bildern zu generieren. Ein einzelnes Bild repräsentiert eine einzelne Seite des PDFs.
Das pdftppm-Dienstprogramm, das Sie brauchen sollte schon installiert sein auf Ihrem Linux-Computer. Das PDF, das wir für unser Beispiel verwenden werden, ist eine Kopie von Alan Turings wegweisendem Papier über künstliche Intelligenz, „Computing Machinery and Intelligence“.

Wir verwenden die Option -png, um anzugeben, dass wir PNG-Dateien erstellen möchten. Der Dateiname unseres PDFs ist „turing.pdf“. Wir nennen unsere Bilddateien „turing-01.png“, „turing-02.png“ und so weiter:
pdftoppm -png turing.pdf turing

Um tesseract für jede Bilddatei mit einem einzigen Befehl auszuführen, müssen wir a für Schleife. Für jede unserer „turing-nn.png“-Dateien führen wir tesseract aus und erstellen eine Textdatei namens „text-“ plus „turing-nn“ als Teil des Bilddateinamens:
for i in turing-??.png; do tesseract "$i" "text-$i" -l eng; done;

Um alle Textdateien zu einer zu kombinieren, können wir cat verwenden:
cat text-turing* > complete.txt

Also, wie hat es geklappt? Sehr gut, wie Sie unten sehen können. Die erste Seite sieht jedoch ziemlich anspruchsvoll aus. Es hat verschiedene Textstile und -größen sowie Dekorationen. Am rechten Rand der Seite befindet sich außerdem ein vertikales „Wasserzeichen“.
Die Ausgabe ist jedoch nah am Original. Offensichtlich ging die Formatierung verloren, aber der Text ist korrekt.
Das vertikale Wasserzeichen wurde als Kauderwelsch am unteren Rand der Seite transkribiert. Der Text war zu klein, um von tesseract richtig gelesen zu werden, aber er wäre leicht genug, ihn zu finden und zu löschen. Das schlimmste Ergebnis wären verirrte Zeichen am Ende jeder Zeile gewesen.
Seltsamerweise wurden die einzelnen Buchstaben am Anfang der Liste der Fragen und Antworten auf Seite zwei ignoriert. Der Abschnitt aus dem PDF ist unten gezeigt.

Wie Sie unten sehen können, bleiben die Fragen bestehen, aber das „Q“ und „A“ am Anfang jeder Zeile gingen verloren.

Diagramme werden auch nicht korrekt transkribiert. Schauen wir uns an, was passiert, wenn wir versuchen, das unten gezeigte aus dem Turing-PDF zu extrahieren.

Wie Sie in unserem Ergebnis unten sehen können, wurden die Zeichen gelesen, aber das Format des Diagramms ging verloren.

Auch hier hatte Tesseract mit der geringen Größe der Indizes zu kämpfen und sie wurden falsch gerendert.
Fairerweise war es dennoch ein gutes Ergebnis. Wir konnten keinen einfachen Text extrahieren, aber dieses Beispiel wurde bewusst gewählt, weil es eine Herausforderung darstellte.
Eine gute Lösung, wenn Sie sie brauchen
OCR ist nicht etwas, das Sie täglich verwenden müssen. Im Bedarfsfall ist es jedoch gut zu wissen, dass Ihnen eine der besten OCR-Engines zur Verfügung steht.