
Wenn man die Entwicklung von Unternehmenssoftware seit zwei Jahrzehnten aus der ersten Reihe beobachtet, ist der unbestreitbare Trend der letzten Jahre klar – die Verlagerung von Datenbanken in die Cloud.
Ich war bereits an einigen Migrationsprojekten beteiligt, bei denen das Ziel darin bestand, die vorhandene On-Premise-Datenbank in die Cloud-Datenbank von Amazon Web Services (AWS) zu bringen. Während Sie aus den AWS-Dokumentationsmaterialien erfahren, wie einfach dies sein kann, bin ich hier, um Ihnen zu sagen, dass die Ausführung eines solchen Plans nicht immer einfach ist und es Fälle gibt, in denen er fehlschlagen kann.
In diesem Beitrag werde ich die realen Erfahrungen für den folgenden Fall behandeln:
- Die Quelle: Obwohl es theoretisch keine Rolle spielt, was Ihre Quelle ist (Sie können einen sehr ähnlichen Ansatz für die Mehrheit der beliebtesten DBs verwenden), war Oracle viele Jahre lang das Datenbanksystem der Wahl in großen Unternehmen und darauf wird mein Fokus liegen.
- Das Ziel: Kein Grund, auf dieser Seite spezifisch zu sein. Sie können eine beliebige Zieldatenbank in AWS auswählen, und der Ansatz passt trotzdem.
- Der Modus: Sie können eine vollständige oder inkrementelle Aktualisierung durchführen. Ein Batch-Datenladen (Quell- und Zielstatus werden verzögert) oder (nahezu) Echtzeit-Datenladen. Beides wird hier angesprochen.
- Die Häufigkeit: Möglicherweise möchten Sie eine einmalige Migration, gefolgt von einem vollständigen Wechsel in die Cloud, oder Sie benötigen eine gewisse Übergangszeit und müssen die Daten auf beiden Seiten gleichzeitig auf dem neuesten Stand halten, was die Entwicklung einer täglichen Synchronisierung zwischen On-Premise und AWS impliziert. Ersteres ist einfacher und macht viel mehr Sinn, aber letzteres wird häufiger angefordert und hat viel mehr Haltepunkte. Ich werde beides hier behandeln.
Inhaltsverzeichnis
Problembeschreibung
Die Anforderung ist oft einfach:
Wir möchten mit der Entwicklung von Diensten innerhalb von AWS beginnen, also kopieren Sie bitte alle unsere Daten in die „ABC“-Datenbank. Schnell und einfach. Wir müssen die Daten jetzt in AWS verwenden. Später werden wir herausfinden, welche Teile des DB-Designs geändert werden müssen, um zu unseren Aktivitäten zu passen.
Bevor Sie fortfahren, gibt es etwas zu beachten:
- Springen Sie nicht zu schnell auf die Idee, „einfach das zu kopieren, was wir haben, und uns später darum zu kümmern“. Ich meine, ja, das ist das Einfachste, was Sie tun können, und es wird schnell erledigt sein, aber dies hat das Potenzial, ein so grundlegendes Architekturproblem zu schaffen, das später ohne ernsthaftes Refactoring des Großteils der neuen Cloud-Plattform nicht mehr behoben werden kann . Stellen Sie sich vor, das Cloud-Ökosystem ist völlig anders als das On-Premise-Ökosystem. Im Laufe der Zeit werden mehrere neue Dienste eingeführt. Natürlich werden die Menschen anfangen, dasselbe sehr unterschiedlich zu verwenden. Es ist fast nie eine gute Idee, den On-Premise-Zustand 1:1 in der Cloud zu replizieren. Dies könnte in Ihrem speziellen Fall der Fall sein, aber überprüfen Sie dies unbedingt noch einmal.
- Hinterfragen Sie die Anforderung mit einigen sinnvollen Zweifeln wie:
- Wer wird der typische Benutzer sein, der die neue Plattform nutzt? Während es vor Ort ist, kann es ein transaktionaler Geschäftsbenutzer sein; in der Cloud kann es sich um einen Datenwissenschaftler oder Data-Warehouse-Analysten handeln, oder der Hauptnutzer der Daten kann ein Dienst sein (z. B. Databricks, Glue, Modelle für maschinelles Lernen usw.).
- Wird erwartet, dass die regulären täglichen Jobs auch nach dem Wechsel in die Cloud bestehen bleiben? Wenn nicht, wie werden sie sich voraussichtlich ändern?
- Planen Sie im Laufe der Zeit ein erhebliches Datenwachstum? Höchstwahrscheinlich lautet die Antwort ja, da dies oft der wichtigste Grund für eine Migration in die Cloud ist. Dafür soll ein neues Datenmodell bereitstehen.
- Erwarten Sie, dass der Endbenutzer über einige allgemeine, erwartete Abfragen nachdenkt, die die neue Datenbank von den Benutzern erhalten wird. Dadurch wird definiert, wie stark sich das bestehende Datenmodell ändern soll, um leistungsrelevant zu bleiben.
Einrichten der Migration
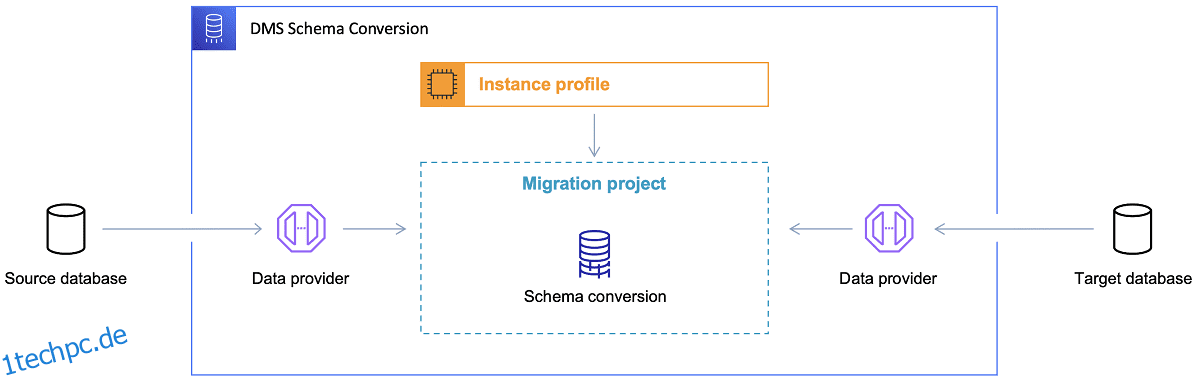
Sobald die Zieldatenbank ausgewählt und das Datenmodell zufriedenstellend besprochen wurde, besteht der nächste Schritt darin, sich mit dem AWS Schema Conversion Tool vertraut zu machen. Es gibt mehrere Bereiche, in denen dieses Tool dienen kann:
 Referenz: AWS-Dokumentation
Referenz: AWS-Dokumentation
Jetzt gibt es ein paar Tipps zur Verwendung des Schemakonvertierungstools.
Erstens sollte es fast nie der Fall sein, die Ausgabe direkt zu verwenden. Ich würde es eher als Referenzergebnisse betrachten, von denen aus Sie Ihre Anpassungen basierend auf Ihrem Verständnis und Zweck der Daten und der Art und Weise, wie die Daten in der Cloud verwendet werden, vornehmen sollten.
Zweitens wurden die Tabellen früher wahrscheinlich von Benutzern ausgewählt, die schnelle kurze Ergebnisse zu einer konkreten Datendomänenentität erwarteten. Aber jetzt könnten die Daten für Analysezwecke ausgewählt werden. Beispielsweise sind Datenbankindizes, die zuvor in der On-Premise-Datenbank arbeiteten, jetzt nutzlos und verbessern definitiv nicht die Leistung des DB-Systems im Zusammenhang mit dieser neuen Nutzung. Ebenso möchten Sie möglicherweise die Daten auf dem Zielsystem anders partitionieren als zuvor auf dem Quellsystem.
Außerdem kann es sinnvoll sein, während des Migrationsprozesses einige Datentransformationen durchzuführen, was im Grunde bedeutet, dass das Zieldatenmodell für einige Tabellen geändert wird (so dass es sich nicht mehr um 1:1-Kopien handelt). Später müssen die Transformationsregeln in das Migrationstool implementiert werden.
Wenn die Quell- und Zieldatenbanken vom gleichen Typ sind (z. B. Oracle On-Premise vs. Oracle in AWS, PostgreSQL vs. Aurora Postgresql usw.), dann ist es am besten, ein dediziertes Migrationstool zu verwenden, das die konkrete Datenbank nativ unterstützt ( B. Exporte und Importe von Datenpumpen, Oracle Goldengate usw.).
In den meisten Fällen sind Quell- und Zieldatenbank jedoch nicht kompatibel, und dann ist AWS Database Migration Service das offensichtliche Tool der Wahl.
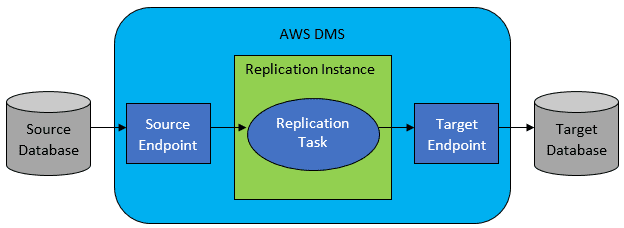 Referenz: AWS-Dokumentation
Referenz: AWS-Dokumentation
AWS DMS ermöglicht grundsätzlich die Konfiguration einer Aufgabenliste auf Tabellenebene, die Folgendes definiert:
- Was ist die genaue Quelldatenbank und -tabelle, mit der eine Verbindung hergestellt werden soll?
- Anweisungsspezifikationen, die zum Abrufen der Daten für die Zieltabelle verwendet werden.
- Transformationswerkzeuge (falls vorhanden), die definieren, wie die Quelldaten in die Zieltabellendaten abgebildet werden sollen (falls nicht 1:1).
- Was ist die genaue Zieldatenbank und -tabelle, in die die Daten geladen werden sollen?
Die Konfiguration der DMS-Aufgaben erfolgt in einem benutzerfreundlichen Format wie JSON.
Im einfachsten Szenario müssen Sie nun nur noch die Bereitstellungsskripts auf der Zieldatenbank ausführen und die DMS-Aufgabe starten. Aber dazu gehört noch viel mehr.
Einmalige vollständige Datenmigration

Der einfachste auszuführende Fall ist, wenn die Anforderung darin besteht, die gesamte Datenbank einmal in die Ziel-Cloud-Datenbank zu verschieben. Dann sieht alles, was zu tun ist, im Grunde wie folgt aus:
Wenn die Konfiguration von DMS gut gemacht ist, wird in diesem Szenario nichts Schlimmes passieren. Jede einzelne Quelltabelle wird aufgenommen und in die AWS-Zieldatenbank kopiert. Die einzigen Bedenken werden die Leistung der Aktivität sein und sicherstellen, dass die Dimensionierung in jedem Schritt richtig ist, damit sie nicht aufgrund von unzureichendem Speicherplatz fehlschlägt.
Inkrementelle tägliche Synchronisierung

Hier beginnen die Dinge kompliziert zu werden. Ich meine, wenn die Welt ideal wäre, dann würde sie wahrscheinlich immer gut funktionieren. Aber die Welt ist nie ideal.
DMS kann für den Betrieb in zwei Modi konfiguriert werden:
- Volllast – Standardmodus, der oben beschrieben und verwendet wird. Die DMS-Tasks werden gestartet, wenn Sie sie starten oder wenn ihr Start geplant ist. Nach Abschluss sind die DMS-Aufgaben erledigt.
- Change Data Capture (CDC) – in diesem Modus wird die DMS-Aufgabe kontinuierlich ausgeführt. DMS durchsucht die Quelldatenbank nach einer Änderung auf Tabellenebene. Wenn die Änderung eintritt, wird sofort versucht, die Änderung in der Zieldatenbank zu replizieren, basierend auf der Konfiguration innerhalb der DMS-Aufgabe, die sich auf die geänderte Tabelle bezieht.
Wenn Sie sich für CDC entscheiden, müssen Sie noch eine weitere Entscheidung treffen – nämlich, wie die CDC die Delta-Änderungen aus der Quelldatenbank extrahiert.
#1. Oracle Redo Logs Reader
Eine Option besteht darin, einen nativen Datenbank-Redo-Logs-Reader von Oracle zu wählen, den CDC verwenden kann, um die geänderten Daten abzurufen, und basierend auf den neuesten Änderungen dieselben Änderungen in der Zieldatenbank zu replizieren.
Während dies wie eine naheliegende Wahl erscheinen mag, wenn es um Oracle als Quelle geht, gibt es einen Haken: Der Oracle-Leser für Redo-Protokolle verwendet den Quell-Oracle-Cluster und wirkt sich somit direkt auf alle anderen Aktivitäten aus, die in der Datenbank ausgeführt werden (es erstellt tatsächlich direkt aktive Sitzungen in die Datenbank).
Je mehr DMS-Tasks Sie konfiguriert haben (oder je mehr DMS-Cluster parallel), desto mehr müssen Sie wahrscheinlich den Oracle-Cluster vergrößern – im Grunde müssen Sie die vertikale Skalierung Ihres primären Oracle-Datenbank-Clusters anpassen. Dies wird sicherlich die Gesamtkosten der Lösung beeinflussen, umso mehr, wenn die tägliche Synchronisation über einen längeren Zeitraum im Projekt bleiben wird.
#2. AWS DMS Log Miner
Im Gegensatz zur obigen Option ist dies eine native AWS-Lösung für dasselbe Problem. In diesem Fall wirkt sich DMS nicht auf die Oracle-Quelldatenbank aus. Stattdessen kopiert es die Redo-Protokolle von Oracle in den DMS-Cluster und führt dort die gesamte Verarbeitung durch. Es spart zwar Oracle-Ressourcen, ist aber die langsamere Lösung, da mehr Vorgänge erforderlich sind. Und wie man leicht annehmen kann, ist der benutzerdefinierte Reader für Oracle-Redo-Logs wahrscheinlich langsamer in seiner Arbeit als der native Reader von Oracle.
Abhängig von der Größe der Quelldatenbank und der Anzahl der dortigen täglichen Änderungen erhalten Sie im besten Fall eine inkrementelle Synchronisation der Daten aus der On-Premise-Oracle-Datenbank in die AWS-Cloud-Datenbank nahezu in Echtzeit.
In allen anderen Szenarien ist die Synchronisierung immer noch nicht annähernd in Echtzeit, aber Sie können versuchen, der akzeptierten Verzögerung (zwischen Quelle und Ziel) so nahe wie möglich zu kommen, indem Sie die Leistungskonfiguration und Parallelität der Quell- und Zielcluster optimieren oder damit experimentieren die Menge der DMS-Aufgaben und deren Verteilung auf die CDC-Instanzen.
Außerdem möchten Sie vielleicht erfahren, welche Änderungen an Quelltabellen von CDC unterstützt werden (z. B. das Hinzufügen einer Spalte), da nicht alle möglichen Änderungen unterstützt werden. In einigen Fällen besteht die einzige Möglichkeit darin, die Zieltabelle manuell zu ändern und die CDC-Aufgabe von Grund auf neu zu starten (wobei dabei alle vorhandenen Daten in der Zieldatenbank verloren gehen).
Wenn die Dinge schief gehen, egal was passiert

Ich habe das auf die harte Tour gelernt, aber es gibt ein spezifisches Szenario im Zusammenhang mit DMS, bei dem das Versprechen einer täglichen Replikation schwer zu erreichen ist.
Das DMS kann die Redo-Logs nur mit einer definierten Geschwindigkeit verarbeiten. Es spielt keine Rolle, ob mehrere DMS-Instanzen Ihre Aufgaben ausführen. Dennoch liest jede DMS-Instanz die Redo-Logs nur mit einer einzigen definierten Geschwindigkeit, und jede von ihnen muss sie vollständig lesen. Es spielt sogar keine Rolle, ob Sie Oracle Redo Logs oder AWS Log Miner verwenden. Beide haben diese Grenze.
Wenn die Quelldatenbank innerhalb eines Tages eine große Anzahl von Änderungen enthält, bei denen die Oracle-Redo-Protokolle jeden Tag wirklich verrückt werden (wie 500 GB+ groß), wird CDC einfach nicht funktionieren. Die Replikation wird nicht vor Ende des Tages abgeschlossen sein. Es wird einige unverarbeitete Arbeit zum nächsten Tag bringen, wo bereits ein neuer Satz von Änderungen zum Replizieren wartet. Die Menge an unverarbeiteten Daten wächst von Tag zu Tag.
In diesem speziellen Fall war CDC keine Option (nach vielen Leistungstests und Versuchen, die wir durchgeführt haben). Die einzige Möglichkeit, sicherzustellen, dass zumindest alle Delta-Änderungen des aktuellen Tages am selben Tag repliziert werden, bestand darin, wie folgt vorzugehen:
- Trennen Sie wirklich große Tabellen, die nicht so oft verwendet werden, und replizieren Sie sie nur einmal pro Woche (z. B. am Wochenende).
- Konfigurieren Sie die Replikation von nicht so großen, aber immer noch großen Tabellen, um sie auf mehrere DMS-Aufgaben aufzuteilen; Eine Tabelle wurde schließlich von 10 oder mehr getrennten DMS-Aufgaben parallel migriert, um sicherzustellen, dass die Datenaufteilung zwischen den DMS-Aufgaben eindeutig ist (hier ist benutzerdefinierte Codierung erforderlich) und sie täglich auszuführen.
- Fügen Sie weitere (in diesem Fall bis zu 4) DMS-Instanzen hinzu und teilen Sie die DMS-Aufgaben gleichmäßig auf, dh nicht nur nach der Anzahl der Tische, sondern auch nach der Größe.
Grundsätzlich haben wir den Volllastmodus von DMS verwendet, um tägliche Daten zu replizieren, da dies die einzige Möglichkeit war, eine Datenreplikation mindestens am selben Tag abzuschließen.
Keine perfekte Lösung, aber es ist immer noch da und funktioniert auch nach vielen Jahren immer noch auf die gleiche Weise. Also vielleicht gar keine so schlechte Lösung. 😃