
Der Linux-Befehl uniq durchsucht Ihre Textdateien und sucht nach eindeutigen oder doppelten Zeilen. In diesem Handbuch behandeln wir seine Vielseitigkeit und Funktionen sowie wie Sie dieses nützliche Dienstprogramm optimal nutzen können.
Inhaltsverzeichnis
Finden übereinstimmender Textzeilen unter Linux
Der uniq-Befehl ist schnell, flexibel und super in dem was es tut. Wie viele Linux-Befehle hat es jedoch ein paar Macken – was in Ordnung ist, solange Sie sie kennen. Wer den Sprung ohne Insider-Know-how wagt, kann sich bei den Ergebnissen durchaus am Kopf kratzen. Wir werden auf diese Macken hinweisen, während wir gehen.
Der uniq-Befehl ist perfekt für diejenigen im zielstrebigen Lager, das darauf ausgelegt ist, eine Sache zu tun und es gut zu machen. Deshalb ist es auch besonders gut geeignet, um mit Pipes zu arbeiten und seine Rolle in Befehlspipelines zu übernehmen. Einer seiner häufigste Mitarbeiter ist sort, weil uniq eine sortierte Eingabe haben muss, mit der gearbeitet werden kann.
Lass es uns anzünden!
Uniq ohne Optionen ausführen
Wir haben eine Textdatei mit den Texten zu Robert Johnsons Lied Ich glaube, ich werde meinen Besen abstauben. Mal sehen, was uniq daraus macht.
Wir geben Folgendes ein, um die Ausgabe in less umzuleiten:
uniq dust-my-broom.txt | less
Wir erhalten den gesamten Song, einschließlich doppelter Zeilen, in weniger:
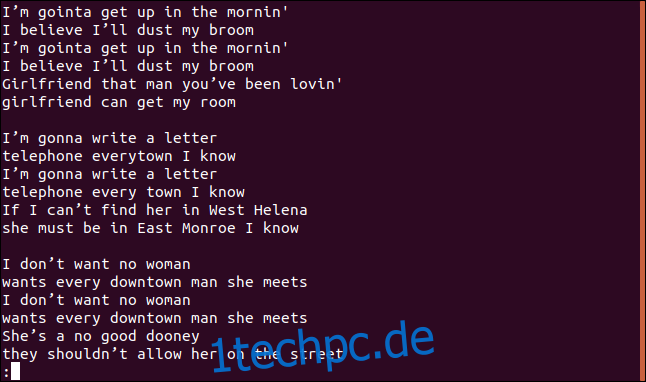
Das scheinen weder die eindeutigen Zeilen noch die doppelten Zeilen zu sein.
Richtig – denn das ist die erste Eigenart. Wenn Sie uniq ohne Optionen ausführen, verhält es sich so, als ob Sie die Option -u (eindeutige Zeilen) verwendet hätten. Dies weist uniq an, nur die eindeutigen Zeilen aus der Datei zu drucken. Der Grund, warum Sie doppelte Zeilen sehen, ist, dass, damit uniq eine Zeile als Duplikat betrachtet, sie neben ihrem Duplikat liegen muss, wo die Sortierung ins Spiel kommt.
Wenn wir die Datei sortieren, gruppiert es die doppelten Zeilen und uniq behandelt sie als Duplikate. Wir verwenden sort für die Datei, leiten die sortierte Ausgabe an uniq und dann die endgültige Ausgabe an less weiter.
Dazu geben wir Folgendes ein:
sort dust-my-broom.txt | uniq | less

Eine sortierte Liste von Zeilen wird in less angezeigt.
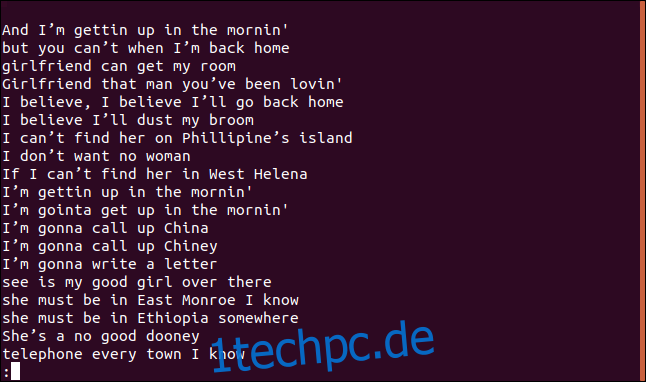
Die Zeile „Ich glaube, ich werde meinen Besen abstauben“ kommt im Song definitiv mehr als einmal vor. Tatsächlich wird es innerhalb der ersten vier Zeilen des Songs zweimal wiederholt.
Warum wird es in einer Liste eindeutiger Zeilen angezeigt? Da eine Zeile zum ersten Mal in der Datei erscheint, ist sie eindeutig; nur die nachfolgenden Einträge sind Duplikate. Sie können sich das so vorstellen, als würden Sie das erste Vorkommen jeder eindeutigen Zeile auflisten.
Lassen Sie uns erneut sortieren und die Ausgabe in eine neue Datei umleiten. Auf diese Weise müssen wir nicht in jedem Befehl sort verwenden.
Wir geben folgenden Befehl ein:
sort dust-my-broom.txt > sorted.txt
 sorted.txt“-Befehl in einem Terminalfenster.‘ width=“646″ height=“57″ onload=“pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);“ onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
sorted.txt“-Befehl in einem Terminalfenster.‘ width=“646″ height=“57″ onload=“pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);“ onerror=”this.onerror=null;pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon(this);”>
Jetzt haben wir eine vorsortierte Datei, mit der wir arbeiten können.
Duplikate zählen
Mit der Option -c (Anzahl) können Sie ausgeben, wie oft jede Zeile in einer Datei vorkommt.
Geben Sie den folgenden Befehl ein:
uniq -c sorted.txt | less

Jede Zeile beginnt mit der Häufigkeit, mit der diese Zeile in der Datei vorkommt. Sie werden jedoch feststellen, dass die erste Zeile leer ist. Dies sagt Ihnen, dass die Datei fünf leere Zeilen enthält.
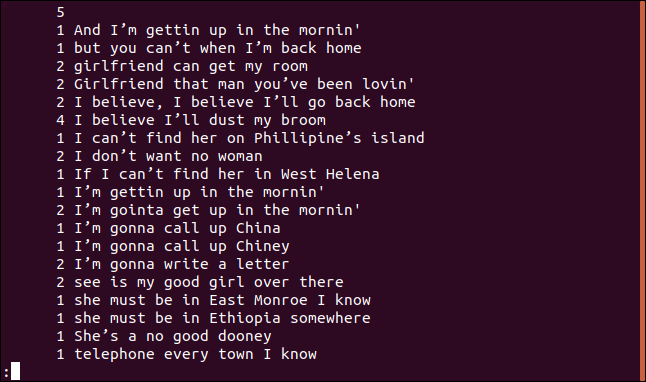
Wenn Sie die Ausgabe in numerischer Reihenfolge sortieren möchten, können Sie die Ausgabe von uniq in sort einspeisen. In unserem Beispiel verwenden wir die Optionen -r (umgekehrt) und -n (numerische Sortierung) und leiten die Ergebnisse in less weiter.
Wir geben folgendes ein:
uniq -c sorted.txt | sort -rn | less

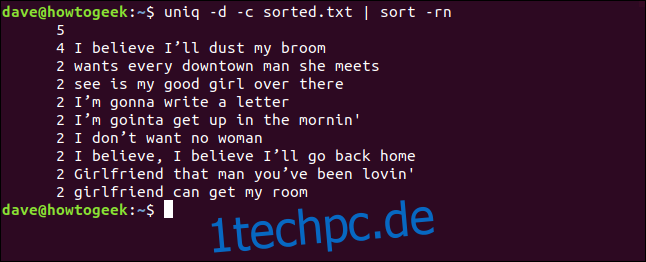
Die Liste wird in absteigender Reihenfolge sortiert, basierend auf der Häufigkeit des Auftretens jeder Zeile.
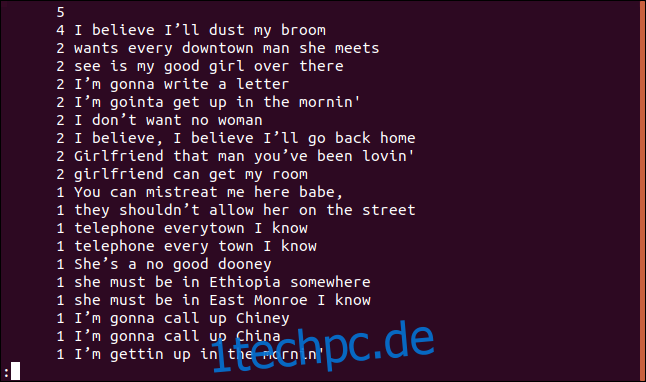
Nur doppelte Zeilen auflisten
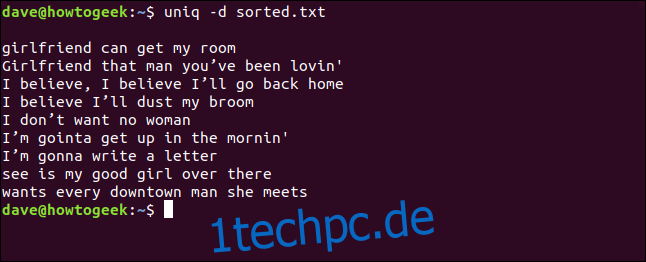
Wenn Sie nur die Zeilen sehen möchten, die in einer Datei wiederholt werden, können Sie die Option -d (wiederholt) verwenden. Egal wie oft eine Zeile in einer Datei dupliziert wird, sie wird nur einmal aufgeführt.
Um diese Option zu verwenden, geben wir Folgendes ein:
uniq -d sorted.txt

Die duplizierten Zeilen werden für uns aufgelistet. Sie werden die Leerzeile oben bemerken, was bedeutet, dass die Datei doppelte Leerzeilen enthält – es ist kein Platz, der von uniq gelassen wird, um die Auflistung kosmetisch zu versetzen.
Wir können auch die Optionen -d (wiederholt) und -c (zählen) kombinieren und die Ausgabe durch Sortieren leiten. Dadurch erhalten wir eine sortierte Liste der Zeilen, die mindestens zweimal vorkommen.
Geben Sie Folgendes ein, um diese Option zu verwenden:
uniq -d -c sorted.txt | sort -rn
Auflisten aller duplizierten Zeilen
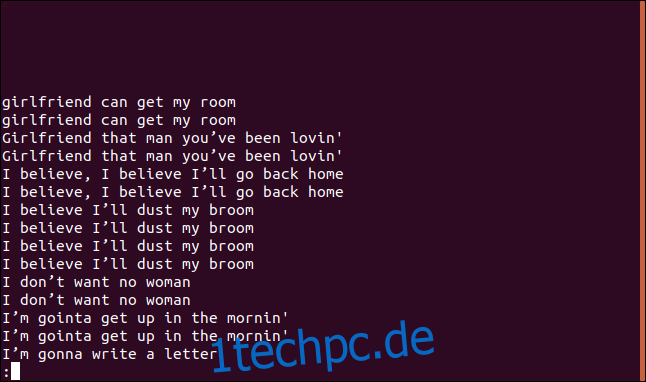
Wenn Sie eine Liste aller duplizierten Zeilen sowie einen Eintrag für jedes Auftreten einer Zeile in der Datei anzeigen möchten, können Sie die Option -D (alle doppelten Zeilen) verwenden.
Um diese Option zu verwenden, geben Sie Folgendes ein:
uniq -D sorted.txt | less

Die Auflistung enthält einen Eintrag für jede duplizierte Zeile.
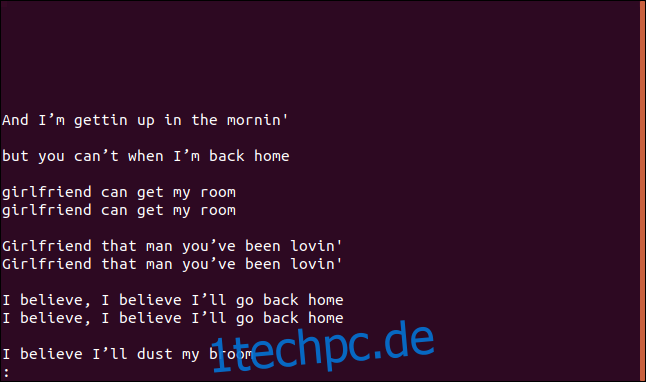
Wenn Sie die Option –group verwenden, wird jede duplizierte Zeile mit einer Leerzeile entweder vor (prepend) oder nach jeder Gruppe (append) oder sowohl vor als auch nach (beide) jeder Gruppe gedruckt.
Wir verwenden append als unseren Modifikator, also geben wir Folgendes ein:
uniq --group=append sorted.txt | less

Die Gruppen sind zur besseren Lesbarkeit durch Leerzeilen getrennt.
Überprüfen einer bestimmten Anzahl von Zeichen
Standardmäßig überprüft uniq die gesamte Länge jeder Zeile. Wenn Sie die Prüfungen jedoch auf eine bestimmte Anzahl von Zeichen beschränken möchten, können Sie die Option -w (Prüfzeichen) verwenden.
In diesem Beispiel wiederholen wir den letzten Befehl, beschränken die Vergleiche jedoch auf die ersten drei Zeichen. Dazu geben wir folgenden Befehl ein:
uniq -w 3 --group=append sorted.txt | less
Die Ergebnisse und Gruppierungen, die wir erhalten, sind sehr unterschiedlich.
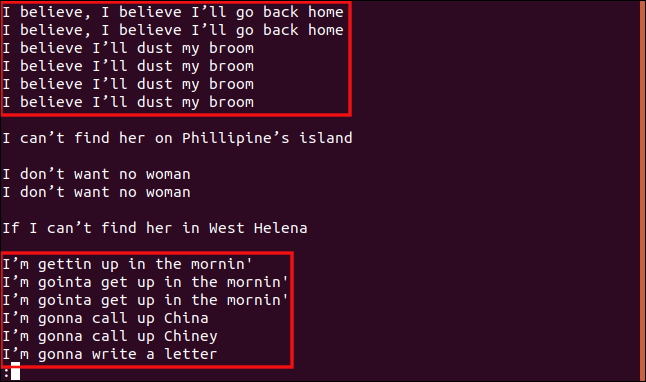
Alle Zeilen, die mit „I b“ beginnen, werden gruppiert, da diese Teile der Zeilen identisch sind und daher als Duplikate betrachtet werden.
Ebenso werden alle Zeilen, die mit „I’m“ beginnen, als Duplikate behandelt, auch wenn der Rest des Textes anders ist.
Ignorieren einer bestimmten Anzahl von Zeichen
Es gibt einige Fälle, in denen es von Vorteil sein kann, eine bestimmte Anzahl von Zeichen am Anfang jeder Zeile zu überspringen, z. B. wenn Zeilen in einer Datei nummeriert sind. Oder sagen Sie, Sie brauchen uniq, um einen Zeitstempel zu überspringen und die Zeilen ab Zeichen sechs statt ab dem ersten Zeichen zu überprüfen.
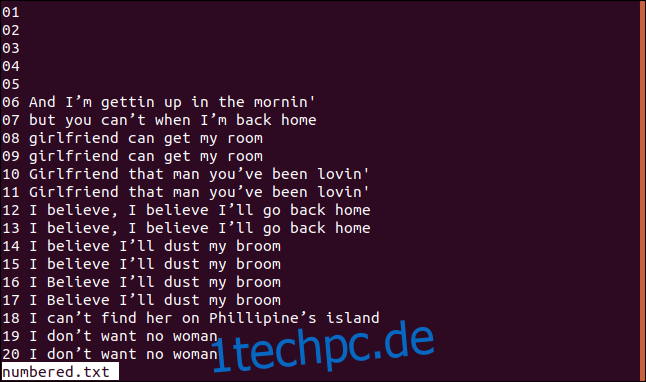
Unten ist eine Version unserer sortierten Datei mit nummerierten Zeilen.
Wenn uniq seine Vergleichsprüfungen bei Zeichen 3 starten soll, können wir die Option -s (Zeichen überspringen) verwenden, indem Sie Folgendes eingeben:
uniq -s 3 -d -c numbered.txt
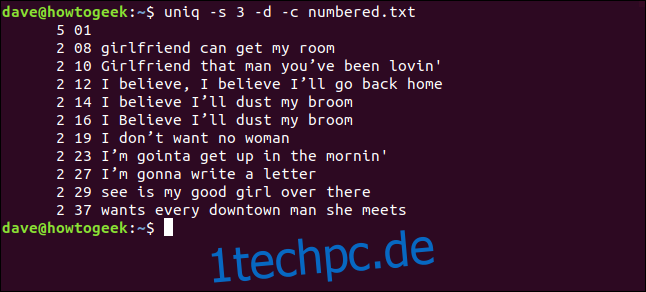
Die Zeilen werden als Duplikate erkannt und korrekt gezählt. Beachten Sie, dass die angezeigten Zeilennummern die des ersten Vorkommens jedes Duplikats sind.
Sie können auch Felder (eine Reihe von Zeichen und einige Leerzeichen) anstelle von Zeichen überspringen. Wir verwenden die Option -f (Felder), um uniq mitzuteilen, welche Felder ignoriert werden sollen.
Wir geben Folgendes ein, um uniq anzuweisen, das erste Feld zu ignorieren:
uniq -f 1 -d -c numbered.txt
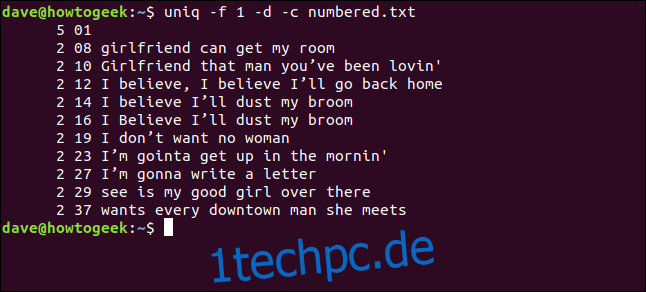
Wir erhalten die gleichen Ergebnisse wie bei uniq, drei Zeichen am Anfang jeder Zeile zu überspringen.
Fall ignorieren
Standardmäßig berücksichtigt uniq die Groß-/Kleinschreibung. Wenn derselbe Buchstabe mit einer Kappe bedeckt und in Kleinbuchstaben angezeigt wird, betrachtet uniq die Zeilen als unterschiedlich.
Sehen Sie sich beispielsweise die Ausgabe des folgenden Befehls an:
uniq -d -c sorted.txt | sort -rn
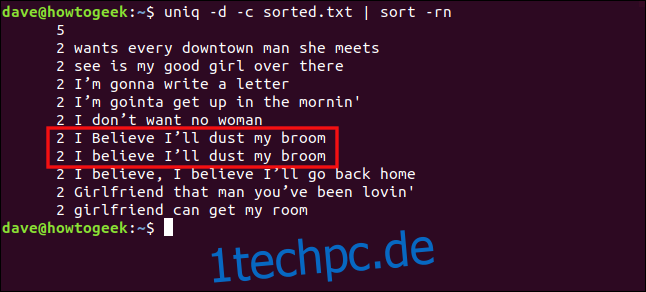
Die Zeilen „Ich glaube, ich werde meinen Besen abstauben“ und „Ich glaube, ich werde meinen Besen abstauben“ werden aufgrund des Unterschieds zwischen Groß- und Kleinschreibung beim „B“ in „glauben“ nicht als Duplikate behandelt.
Wenn wir jedoch die Option -i (Groß-/Kleinschreibung ignorieren) angeben, werden diese Zeilen als Duplikate behandelt. Wir geben folgendes ein:
uniq -d -c -i sorted.txt | sort -rn
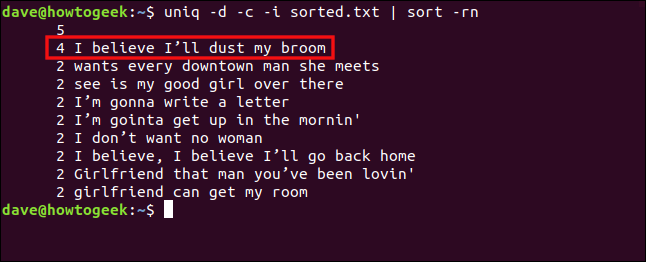
Die Zeilen werden jetzt als Duplikate behandelt und gruppiert.
Linux stellt Ihnen eine Vielzahl spezieller Dienstprogramme zur Verfügung. Wie viele von ihnen ist uniq kein Werkzeug, das Sie jeden Tag verwenden werden.
Aus diesem Grund besteht ein großer Teil der Linux-Kenntnisse darin, sich daran zu erinnern, welches Tool Ihr aktuelles Problem löst und wo Sie es wieder finden können. Wenn Sie jedoch üben, sind Sie auf dem besten Weg.
Oder Sie können jederzeit nach 1techpc.de suchen – wahrscheinlich haben wir einen Artikel dazu.