
Die Verarbeitung von Big Data ist einer der komplexesten Prozesse, mit denen Unternehmen konfrontiert sind. Der Prozess wird komplizierter, wenn Sie über eine große Menge an Echtzeitdaten verfügen.
In diesem Beitrag werden wir herausfinden, was Big Data Processing ist, wie es gemacht wird, und Apache Kafka und Spark erkunden – die beiden bekanntesten Datenverarbeitungstools!
Inhaltsverzeichnis
Was ist Datenverarbeitung? Wie wird es gemacht?
Datenverarbeitung ist definiert als jeder Vorgang oder jede solche Vorgangsreihe, unabhängig davon, ob sie mithilfe eines automatisierten Verfahrens ausgeführt wird oder nicht. Es kann als das Sammeln, Ordnen und Organisieren von Informationen gemäß einer logischen und angemessenen Disposition zur Interpretation betrachtet werden.
Wenn ein Benutzer auf eine Datenbank zugreift und Ergebnisse für seine Suche erhält, ist es die Datenverarbeitung, die ihm die gewünschten Ergebnisse liefert. Die als Suchergebnis extrahierten Informationen sind das Ergebnis der Datenverarbeitung. Deshalb konzentriert sich die Informationstechnologie auf die Datenverarbeitung.
Die traditionelle Datenverarbeitung wurde mit einfacher Software durchgeführt. Mit dem Aufkommen von Big Data haben sich die Dinge jedoch geändert. Als Big Data werden Informationen bezeichnet, deren Volumen über hundert Terabyte und Petabyte betragen kann.
Darüber hinaus werden diese Informationen regelmäßig aktualisiert. Beispiele hierfür sind Daten aus Contact Centern, sozialen Medien, Börsenhandelsdaten usw. Solche Daten werden manchmal auch als Datenstrom bezeichnet – ein konstanter, unkontrollierter Datenstrom. Sein Hauptmerkmal ist, dass die Daten keine definierten Grenzen haben, sodass es unmöglich ist, zu sagen, wann der Stream beginnt oder endet.
Die Daten werden verarbeitet, wenn sie am Ziel ankommen. Einige Autoren nennen es Echtzeit- oder Online-Verarbeitung. Ein anderer Ansatz ist die Block-, Batch- oder Offline-Verarbeitung, bei der Datenblöcke in Zeitfenstern von Stunden oder Tagen verarbeitet werden. Häufig handelt es sich bei dem Batch um einen Prozess, der nachts ausgeführt wird und die Daten des Tages konsolidiert. Es gibt Fälle von Zeitfenstern von einer Woche oder sogar einem Monat, die veraltete Berichte erzeugen.
Da die besten Big-Data-Verarbeitungsplattformen per Streaming Open Sources wie Kafka und Spark sind, ermöglichen diese Plattformen die Nutzung anderer, unterschiedlicher und komplementärer Plattformen. Das bedeutet, dass sie sich als Open Source schneller weiterentwickeln und mehr Tools verwenden. Auf diese Weise werden Datenströme von anderen Orten mit variabler Rate und ohne Unterbrechungen empfangen.
Nun werden wir uns zwei der bekanntesten Datenverarbeitungswerkzeuge ansehen und sie vergleichen:
Apache Kafka
Apache Kafka ist ein Messaging-System, das Streaming-Anwendungen mit einem kontinuierlichen Datenfluss erstellt. Ursprünglich von LinkedIn entwickelt, ist Kafka protokollbasiert; Ein Protokoll ist eine grundlegende Form der Speicherung, da jede neue Information am Ende der Datei hinzugefügt wird.
Kafka ist eine der besten Lösungen für Big Data, da sein Hauptmerkmal sein hoher Durchsatz ist. Mit Apache Kafka ist es sogar möglich, die Stapelverarbeitung in Echtzeit umzuwandeln,
Apache Kafka ist ein Publish-Subscribe-Nachrichtensystem, in dem eine Anwendung Nachrichten veröffentlicht und eine abonnierte Anwendung Nachrichten empfängt. Die Zeit zwischen der Veröffentlichung und dem Empfang der Nachricht kann Millisekunden betragen, sodass eine Kafka-Lösung eine geringe Latenz hat.
Arbeiten von Kafka
Die Architektur von Apache Kafka umfasst Producer, Consumer und den Cluster selbst. Der Producer ist eine beliebige Anwendung, die Nachrichten an den Cluster veröffentlicht. Der Verbraucher ist jede Anwendung, die Nachrichten von Kafka empfängt. Der Kafka-Cluster ist eine Gruppe von Knoten, die als einzelne Instanz des Messaging-Dienstes fungieren.
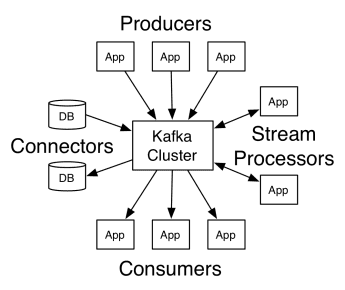 Arbeiten von Kafka
Arbeiten von Kafka
Ein Kafka-Cluster besteht aus mehreren Brokern. Ein Broker ist ein Kafka-Server, der Nachrichten von Produzenten empfängt und sie auf die Festplatte schreibt. Jeder Broker verwaltet eine Themenliste, und jedes Thema ist in mehrere Partitionen unterteilt.
Nach Erhalt der Nachrichten sendet der Broker diese an die registrierten Verbraucher für jedes Thema.
Apache Kafka-Einstellungen werden von Apache Zookeeper verwaltet, der Cluster-Metadaten wie Partitionsspeicherort, Namensliste, Themenliste und verfügbare Knoten speichert. Somit hält Zookeeper die Synchronisation zwischen den verschiedenen Elementen des Clusters aufrecht.
Zookeeper ist wichtig, weil Kafka ein verteiltes System ist; Das heißt, das Schreiben und Lesen wird von mehreren Clients gleichzeitig durchgeführt. Wenn ein Fehler auftritt, wählt der Tierpfleger einen Ersatz und stellt den Betrieb wieder her.
Anwendungsfälle
Kafka wurde vor allem für seine Verwendung als Messaging-Tool populär, aber seine Vielseitigkeit geht darüber hinaus und kann in einer Vielzahl von Szenarien verwendet werden, wie in den folgenden Beispielen.
Nachrichten
Asynchrone Form der Kommunikation, die die Kommunikationspartner entkoppelt. Bei diesem Modell sendet eine Partei die Daten als Nachricht an Kafka, sodass sie später von einer anderen Anwendung verarbeitet werden.
Aktivitätsverfolgung
Ermöglicht es Ihnen, Daten zu speichern und zu verarbeiten, die die Interaktion eines Benutzers mit einer Website verfolgen, z. B. Seitenaufrufe, Klicks, Dateneingabe usw.; Diese Art von Aktivität erzeugt normalerweise eine große Datenmenge.
Metriken
Umfasst die Aggregation von Daten und Statistiken aus mehreren Quellen, um einen zentralisierten Bericht zu erstellen.
Protokollaggregation
Sammelt und speichert zentral Protokolldateien, die von anderen Systemen stammen.
Stream-Verarbeitung
Die Verarbeitung von Datenpipelines besteht aus mehreren Phasen, in denen Rohdaten aus Themen verbraucht und aggregiert, angereichert oder in andere Themen umgewandelt werden.
Zur Unterstützung dieser Funktionen stellt die Plattform im Wesentlichen drei APIs bereit:
- Streams-API: Sie fungiert als Stream-Prozessor, der Daten von einem Thema verarbeitet, transformiert und in ein anderes schreibt.
- Konnektoren-API: Ermöglicht das Verbinden von Themen mit bestehenden Systemen, wie z. B. relationalen Datenbanken.
- Producer- und Consumer-APIs: Ermöglicht Anwendungen das Veröffentlichen und Konsumieren von Kafka-Daten.
Vorteile
Repliziert, partitioniert und geordnet
Nachrichten in Kafka werden partitionsübergreifend über Cluster-Knoten in der Reihenfolge ihres Eintreffens repliziert, um die Sicherheit und Geschwindigkeit der Zustellung zu gewährleisten.
Datentransformation
Mit Apache Kafka ist es sogar möglich, die Batch-Verarbeitung mithilfe der Batch-ETL-Streams-API in Echtzeit umzuwandeln.
Sequentielle Festplattenzugriffe
Apache Kafka speichert die Nachricht auf der Festplatte und nicht im Speicher, da es schneller sein soll. Tatsächlich ist der Speicherzugriff in den meisten Situationen schneller, insbesondere wenn es um den Zugriff auf Daten geht, die sich an zufälligen Stellen im Speicher befinden. Kafka greift jedoch sequenziell zu, und in diesem Fall ist die Festplatte effizienter.
Apache Spark
Apache Spark ist eine Big-Data-Computing-Engine und eine Reihe von Bibliotheken für die clusterübergreifende Verarbeitung paralleler Daten. Spark ist eine Weiterentwicklung von Hadoop und dem Map-Reduce-Programmierparadigma. Es kann 100-mal schneller sein, dank seiner effizienten Speichernutzung, die Daten während der Verarbeitung nicht auf Festplatten speichert.
Spark ist auf drei Ebenen organisiert:
- Low-Level-APIs: Diese Ebene enthält die grundlegende Funktionalität zum Ausführen von Jobs und andere Funktionen, die von den anderen Komponenten benötigt werden. Weitere wichtige Funktionen dieser Schicht sind die Verwaltung von Sicherheit, Netzwerk, Zeitplanung und logischem Zugriff auf die Dateisysteme HDFS, GlusterFS, Amazon S3 und andere.
- Strukturierte APIs: Die strukturierte API-Ebene befasst sich mit der Datenmanipulation durch DataSets oder DataFrames, die in Formaten wie Hive, Parquet, JSON und anderen gelesen werden können. Mit SparkSQL (API, mit dem wir Abfragen in SQL schreiben können) können wir die Daten nach Belieben manipulieren.
- Hohe Ebene: Auf der höchsten Ebene haben wir das Spark-Ökosystem mit verschiedenen Bibliotheken, darunter Spark Streaming, Spark MLlib und Spark GraphX. Sie kümmern sich um die Streaming-Aufnahme und die umgebenden Prozesse, wie z. B. die Wiederherstellung nach einem Absturz, die Erstellung und Validierung klassischer Machine-Learning-Modelle und den Umgang mit Graphen und Algorithmen.
Funktionsweise von Spark
Die Architektur einer Spark-Anwendung besteht aus drei Hauptteilen:
Treiberprogramm: Es ist für die Orchestrierung der Ausführung der Datenverarbeitung verantwortlich.
Cluster-Manager: Es ist die Komponente, die für die Verwaltung der verschiedenen Maschinen in einem Cluster verantwortlich ist. Wird nur benötigt, wenn Spark verteilt ausgeführt wird.
Worker-Knoten: Dies sind die Maschinen, die die Aufgaben eines Programms ausführen. Wenn Spark lokal auf Ihrem Computer ausgeführt wird, spielt es eine Treiberprogramm- und eine Workes-Rolle. Diese Art, Spark auszuführen, wird Standalone genannt.
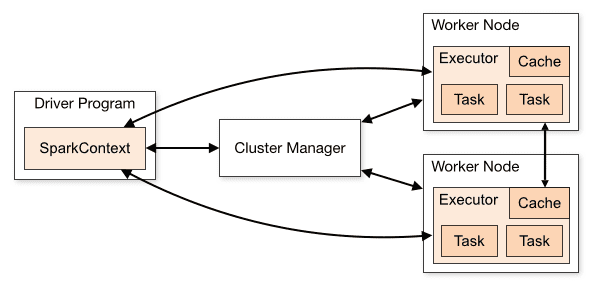 Cluster-Übersicht
Cluster-Übersicht
Spark-Code kann in einer Reihe verschiedener Sprachen geschrieben werden. Die Spark-Konsole mit dem Namen Spark Shell ist interaktiv zum Lernen und Untersuchen von Daten.
Die sogenannte Spark-Anwendung besteht aus einem oder mehreren Jobs und ermöglicht die Unterstützung einer umfangreichen Datenverarbeitung.
Wenn wir über die Ausführung sprechen, hat Spark zwei Modi:
- Client: Der Treiber läuft direkt auf dem Client, der nicht über den Ressourcenmanager geht.
- Cluster: Treiber, der über den Ressourcenmanager auf dem Anwendungsmaster ausgeführt wird (im Clustermodus wird die Anwendung weiter ausgeführt, wenn der Client die Verbindung trennt).
Es ist notwendig, Spark korrekt zu verwenden, damit die verknüpften Dienste, wie z. B. der Ressourcen-Manager, den Bedarf für jede Ausführung erkennen und die beste Leistung bieten können. Es liegt also am Entwickler, den besten Weg zu kennen, um seine Spark-Jobs auszuführen und den getätigten Aufruf zu strukturieren, und dafür können Sie den Executor-Spark so strukturieren und konfigurieren, wie Sie es möchten.
Spark-Jobs verwenden hauptsächlich Arbeitsspeicher, daher ist es üblich, Spark-Konfigurationswerte für Arbeitsknoten-Executoren anzupassen. Abhängig von der Spark-Workload kann festgestellt werden, dass eine bestimmte nicht standardmäßige Spark-Konfiguration optimalere Ausführungen bietet. Dazu können Vergleichstests zwischen den verschiedenen verfügbaren Konfigurationsmöglichkeiten und der Default-Spark-Konfiguration selbst durchgeführt werden.
Anwendungsfälle
Apache Spark hilft bei der Verarbeitung riesiger Datenmengen, ob in Echtzeit oder archiviert, strukturiert oder unstrukturiert. Im Folgenden sind einige der beliebtesten Anwendungsfälle aufgeführt.
Datenanreicherung
Häufig verwenden Unternehmen eine Kombination aus historischen Kundendaten mit Echtzeit-Verhaltensdaten. Spark kann beim Aufbau einer kontinuierlichen ETL-Pipeline helfen, um unstrukturierte Ereignisdaten in strukturierte Daten umzuwandeln.
Ereigniserkennung auslösen
Spark Streaming ermöglicht eine schnelle Erkennung und Reaktion auf einige seltene oder verdächtige Verhaltensweisen, die auf ein potenzielles Problem oder Betrug hinweisen könnten.
Komplexe Sitzungsdatenanalyse
Mithilfe von Spark Streaming können Ereignisse im Zusammenhang mit der Sitzung des Benutzers, z. B. seine Aktivitäten nach dem Anmelden bei der Anwendung, gruppiert und analysiert werden. Diese Informationen können auch kontinuierlich verwendet werden, um Machine-Learning-Modelle zu aktualisieren.
Vorteile
Iterative Verarbeitung
Wenn die Aufgabe darin besteht, Daten wiederholt zu verarbeiten, ermöglichen die robusten Distributed Datasets (RDDs) von Spark mehrere In-Memory-Map-Operationen, ohne dass Zwischenergebnisse auf die Festplatte geschrieben werden müssen.
Grafische Bearbeitung
Das Berechnungsmodell von Spark mit der GraphX-API eignet sich hervorragend für iterative Berechnungen, die typisch für die Grafikverarbeitung sind.
Maschinelles Lernen
Spark verfügt über MLlib – eine integrierte Bibliothek für maschinelles Lernen mit vorgefertigten Algorithmen, die auch im Arbeitsspeicher ausgeführt werden.
Kafka gegen Spark
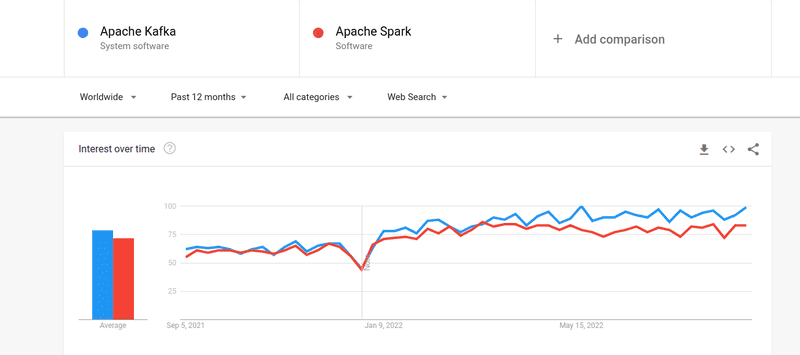
Obwohl das Interesse der Leute an Kafka und Spark fast gleich war, gibt es einige große Unterschiede zwischen den beiden; werfen wir einen Blick.
#1. Datenverarbeitung
Kafka ist ein Echtzeit-Datenstreaming- und Speichertool, das für die Übertragung von Daten zwischen Anwendungen verantwortlich ist, aber es reicht nicht aus, um eine vollständige Lösung zu erstellen. Daher werden für Aufgaben, die Kafka nicht übernimmt, andere Tools benötigt, z. B. Spark. Spark hingegen ist eine Batch-First-Datenverarbeitungsplattform, die Daten aus Kafka-Themen zieht und sie in kombinierte Schemas umwandelt.
#2. Speicherverwaltung
Spark verwendet Robust Distributed Datasets (RDD) für die Speicherverwaltung. Anstatt zu versuchen, riesige Datensätze zu verarbeiten, verteilt es sie auf mehrere Knoten in einem Cluster. Kafka hingegen nutzt ähnlich wie HDFS einen sequentiellen Zugriff und legt Daten in einem Pufferspeicher ab.
#3. ETL-Transformation
Sowohl Spark als auch Kafka unterstützen den ETL-Transformationsprozess, der Datensätze von einer Datenbank in eine andere kopiert, normalerweise von einer Transaktionsbasis (OLTP) auf eine Analysebasis (OLAP). Im Gegensatz zu Spark, das über eine integrierte Fähigkeit für ETL-Prozesse verfügt, verlässt sich Kafka jedoch auf die Streams-API, um dies zu unterstützen.
#4. Datenpersistenz

Durch die Verwendung von RRD in Spark können Sie die Daten zur späteren Verwendung an mehreren Orten speichern, während Sie in Kafka Dataset-Objekte in der Konfiguration definieren müssen, um Daten beizubehalten.
#5. Schwierigkeit
Spark ist eine vollständige Lösung und leichter zu erlernen, da es verschiedene höhere Programmiersprachen unterstützt. Kafka hängt von einer Reihe verschiedener APIs und Modulen von Drittanbietern ab, was die Arbeit erschweren kann.
#6. Wiederherstellung
Sowohl Spark als auch Kafka bieten Wiederherstellungsoptionen. Spark verwendet RRD, wodurch Daten kontinuierlich gespeichert und bei einem Clusterausfall wiederhergestellt werden können.

Kafka repliziert kontinuierlich Daten innerhalb des Clusters und repliziert über Broker hinweg, sodass Sie bei einem Fehler zu den verschiedenen Brokern wechseln können.
Ähnlichkeiten zwischen Spark und Kafka
Apache SparkApache KafkaOpenSourceOpenSourceBuild Data Streaming ApplicationBuild Data Streaming ApplicationSupports Stateful ProcessingSupports Stateful ProcessingSupports SQLSupports SQLÄhnlichkeiten zwischen Spark und Kafka
Letzte Worte
Kafka und Spark sind beide in Scala und Java geschriebene Open-Source-Tools, mit denen Sie Echtzeit-Daten-Streaming-Anwendungen erstellen können. Sie haben mehrere Gemeinsamkeiten, darunter zustandsbehaftete Verarbeitung, Unterstützung für SQL und ETL. Kafka und Spark können auch als komplementäre Tools verwendet werden, um das Problem der Komplexität der Datenübertragung zwischen Anwendungen zu lösen.