
Lassen Sie uns herausfinden, wie Sie Ihre Produktion mit Hilfe von Chaos Engineering-Tools zuverlässig halten können.
Chaos Engineering ist eine Disziplin, in der Sie an Ihrem System oder Ihrer Anwendung experimentieren, um deren Schwächen und Kapazitätsausfälle aufzudecken. Das sind Dinge, von denen Sie nicht gedacht hätten, dass sie beim Erstellen passieren könnten. Sie würden also absichtlich einige Fehler auf Ihrem System verursachen, um seine Schwächen aufzuzeigen, um die Korrekturen vorzunehmen und Ihr System und Ihre Anwendung widerstandsfähiger zu machen.
Viele bekannte Organisationen wie Netflix, LinkedIn und Facebook führen Chaos Engineering durch, um ihre Microservices-Architektur und verteilten Systeme besser zu verstehen. Es hilft, neue Probleme früher als echte Benutzerbeschwerden zu finden und die erforderlichen Maßnahmen zu ergreifen, um sie zu beheben. Auf diese Weise können diese Organisationen Millionen von Benutzern bedienen, ihre Produktivität steigern und Millionen von Dollar sparen 🤑.
Vorteile von Chaos Engineering:
- Kontrollieren Sie Einnahmeverluste, indem Sie kritische Probleme finden
- Reduzierung von System- oder Anwendungsausfällen
- Bessere Benutzererfahrung mit weniger Unterbrechungen und hoher Serviceverfügbarkeit
- Es hilft Ihnen, das System kennenzulernen und Vertrauen zu gewinnen.
Wie zuversichtlich sind Sie in Bezug auf Ihre Produktionssicherheit? Ist es wirklich katastrophensicher?
Finden wir es mit Hilfe der folgenden beliebten Chaos-Test-Tools heraus.
Inhaltsverzeichnis
Chaos-Mesh
Chaos-Mesh ist eine Chaos-Engineering-Managementlösung, die Fehler in jede Schicht eines Kubernetes-Systems einfügt. Dazu gehören Pods, das Netzwerk, System-I/O und der Kernel. Chaos Mesh kann Kubernetes-Pods automatisch beenden und Latenzen simulieren. Es kann die Pod-zu-Pod-Kommunikation stören und Lese-/Schreibfehler simulieren. Es kann Regeln für die Experimente planen und deren Umfang definieren. Diese Experimente werden mithilfe von YAML-Dateien spezifiziert.
Chaos Mesh verfügt über ein Dashboard, um Analysen zu Experimenten anzuzeigen. Es läuft auf Kubernetes und unterstützt den Großteil der Cloud-Plattform. Es ist Open Source und wurde kürzlich als CNCF-Sandbox-Projekt akzeptiert. Mithilfe der Chaos-Engineering-Prinzipien können Sie Chaos Mesh zu Ihrem DevOps-Workflow hinzufügen, um robuste Anwendungen zu erstellen.
Chaos-Engineering-Funktionen:
- Einfache Bereitstellung auf Kubernetes-Clustern ohne Änderung der Bereitstellungslogik
- Für die Bereitstellung sind keine eindeutigen Abhängigkeiten erforderlich
- Definiert Chaosobjekte mit CustomResourceDefinitions (CRD)
- Bietet ein Dashboard, um alle Experimente zu verfolgen
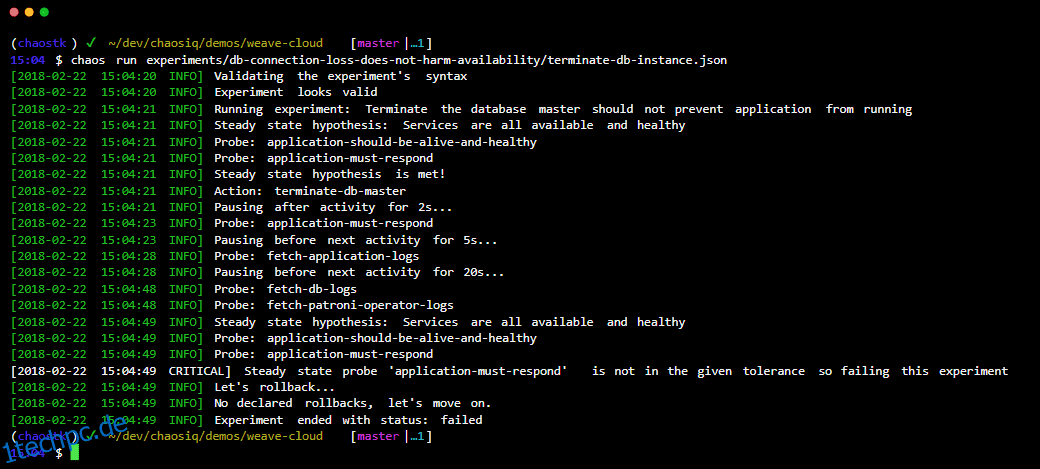
Chaos-Toolkit ist ein quelloffenes und einfaches Tool für die Automatisierung von Chaos Engineering-Experimenten.
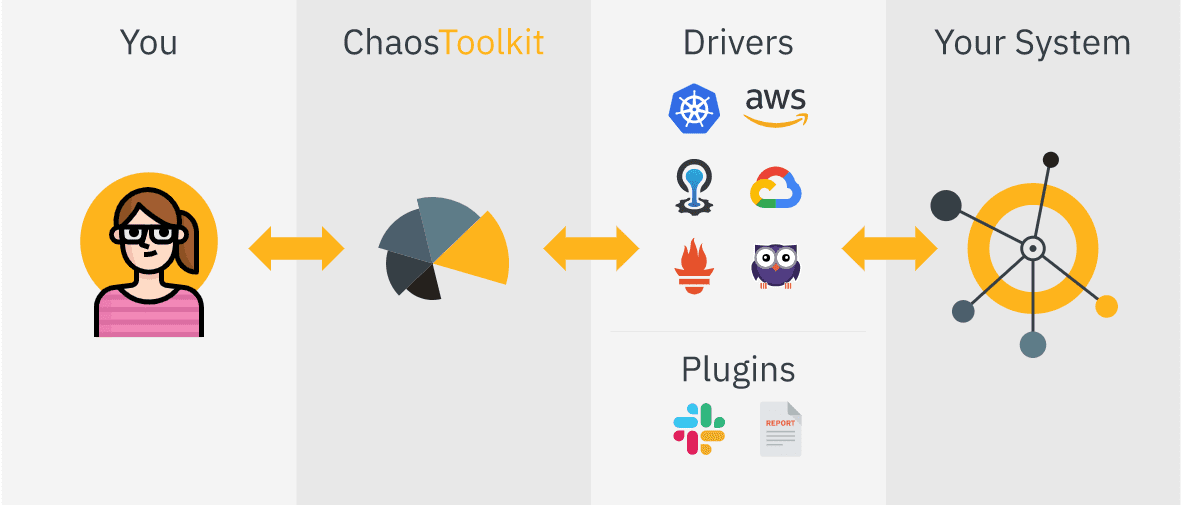
Sie integrieren Chaos ToolKit in Ihr System, indem Sie eine Reihe von Treibern oder Plugins verwenden, die AWS, Google Cloud, Slack, Prometheus usw. unterstützen.
Funktionen des Chaos-ToolKits:
- Stellt eine deklarative offene API bereit, um Chaos-Experimente unabhängig von einem Anbieter oder einer Technologie zu erstellen
- Kann zur Automatisierung einfach in CICD-Pipelines eingebettet werden
- Bietet kommerzielle und Unternehmensunterstützung auch durch ChaosIQ
ChaosKube
Wie Sie dem Namen entnehmen können, handelt es sich um Kubernetes.
Chaoskube ist ein Open-Source-Chaos-Tool, das zufällige Pods regelmäßig im Kubernetes-Cluster beendet. Es hilft Ihnen zu verstehen, wie Ihr System reagiert, wenn der Pod ausfällt. Standardmäßig beendet es alle 10 Minuten einen Pod in einem beliebigen Namespace. Sie können die Ziel-Pods in Chaoskube mithilfe von Namespaces, Labels, Anmerkungen usw. filtern. Es kann einfach mit Chaoskube installiert werden.

Chaos-Affe
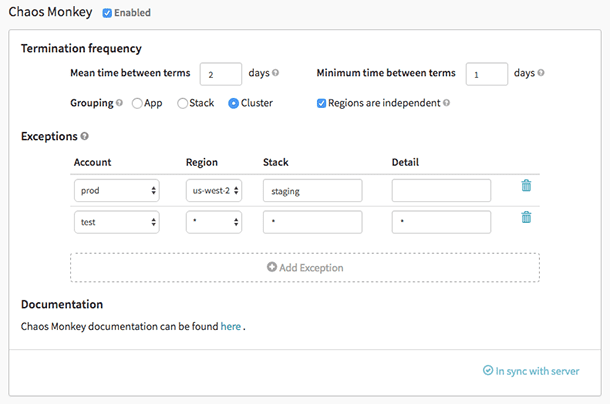
Chaos-Affe ist ein Tool, mit dem die Widerstandsfähigkeit der Cloud-Systeme überprüft wird, indem absichtlich Fehler erstellt werden, damit diese Systeme ihre Reaktion verstehen können. Netflix hat es entwickelt, um die Belastbarkeit und Wiederherstellbarkeit seiner AWS-Infrastruktur zu testen. Es wurde Chaos Monkey genannt, weil es Zerstörung wie ein wilder und bewaffneter Affe erzeugt, um die Fehler zu testen.
Außerdem war es Chaos Monkey, der das neue Ingenieurbüro Chaos Engineering hervorbrachte. Es wurde nach dem Prinzip entwickelt, dass es besser ist, wiederholt zu scheitern, um plötzliche signifikante Fehler zu vermeiden.
Eigenschaften von Chaos Monkey:
- Es hilft Ihnen, sich auf zufällige Instanzausfälle vorzubereiten.
- Fördert Redundanz für unerwartete Ausfälle
- Verwendet Spinnaker, um Cloud-übergreifende Kompatibilität zu ermöglichen
- Bietet einen konfigurierbaren Zeitplan zum Simulieren von Ausfällen
- Integriert mit Gouverneur um neue Abhängigkeiten zu Chaos Monkey hinzuzufügen
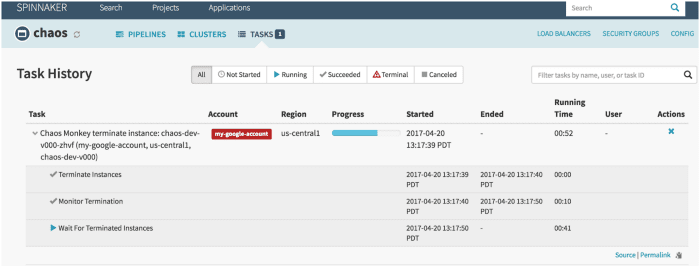
Simmy
Simmy ist ein Fault-Injection-Chaos-Tool, das in das Polly-Resilience-Projekt für .NET integriert ist. Es ermöglicht Ihnen, Chaos-Injection-Richtlinien über Polly zu erstellen, wo Sie Ihre Codes ausführen. Es bietet verschiedene Richtlinien, z. B. Ausnahmerichtlinien zum Einfügen von Ausnahmen in das System, Verhaltensrichtlinien zum Einfügen von neuem Verhalten usw. Diese Richtlinien sind so konzipiert, dass sie das Verhalten nach dem Zufallsprinzip einfügen.
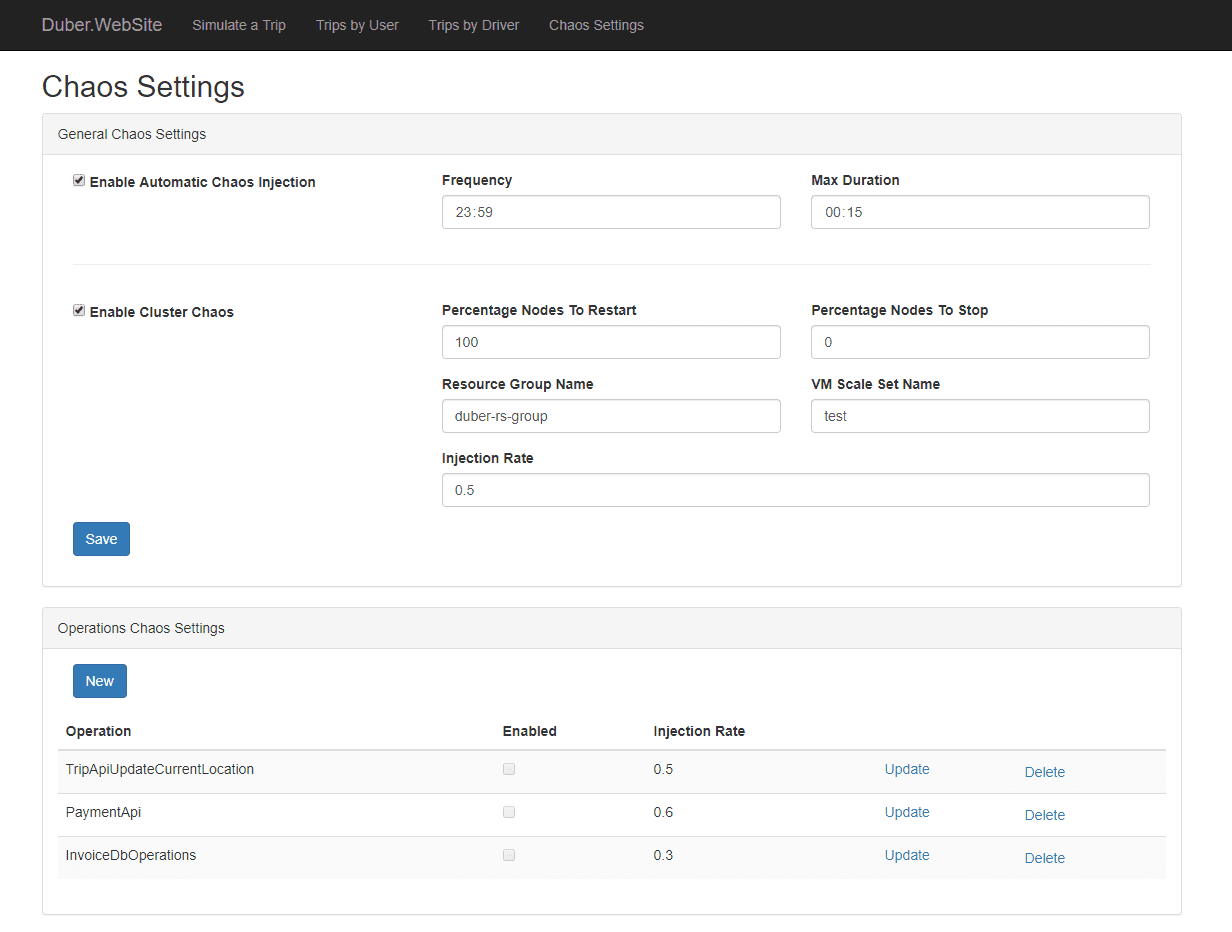
Simmy-Funktionen:
- Stellt Monkey-Richtlinien oder Chaos-Richtlinien bereit, um Chaos zu injizieren
- Einfaches Testen von Abhängigkeitsfehlern
- Es hilft, schnell zum Arbeitsmodell zurückzukehren, und steuert den Explosionsradius.
- Es ist produktionsreif.
- Es kann Fehler auch basierend auf externen Faktoren definieren (z. B. Fehler aufgrund globaler Konfiguration).
Pystole
Pystole ist ein Tool, das zum Einfügen fehlerhafter Injektionen in Cloud-nativen Umgebungen verwendet wird. Es beobachtet Ereignisse in der ETCD über Kubernetes-Operatoren. Wenn eine Fehlerinjektionsaktion ausgeführt wird, erstellen die Operatoren die Pods und führen einige Ansible-Sammlungen aus. Entwickler müssen also keine eigenen auszuführenden Aktionen schreiben.
Pystol bietet vorgefertigte Aktionen zum Testen des Systems. Wenn ein Entwickler jedoch eine neue Aktion erstellen möchte, kann dies mit GoLang und Python erfolgen.
Es bietet ein Continuous-Integration-Dashboard, um eine zusammenfassende Ansicht aller Jobvorgänge zu geben. Sie können Pystol lokal ausführen oder es mit seinem Docker-Image in einem Container bereitstellen. Pystol bietet zwei Schnittstellen, eine ist die Web-Benutzeroberfläche und die andere über die CLI. Offensichtlich ist die Web-Benutzeroberfläche die bessere Option.
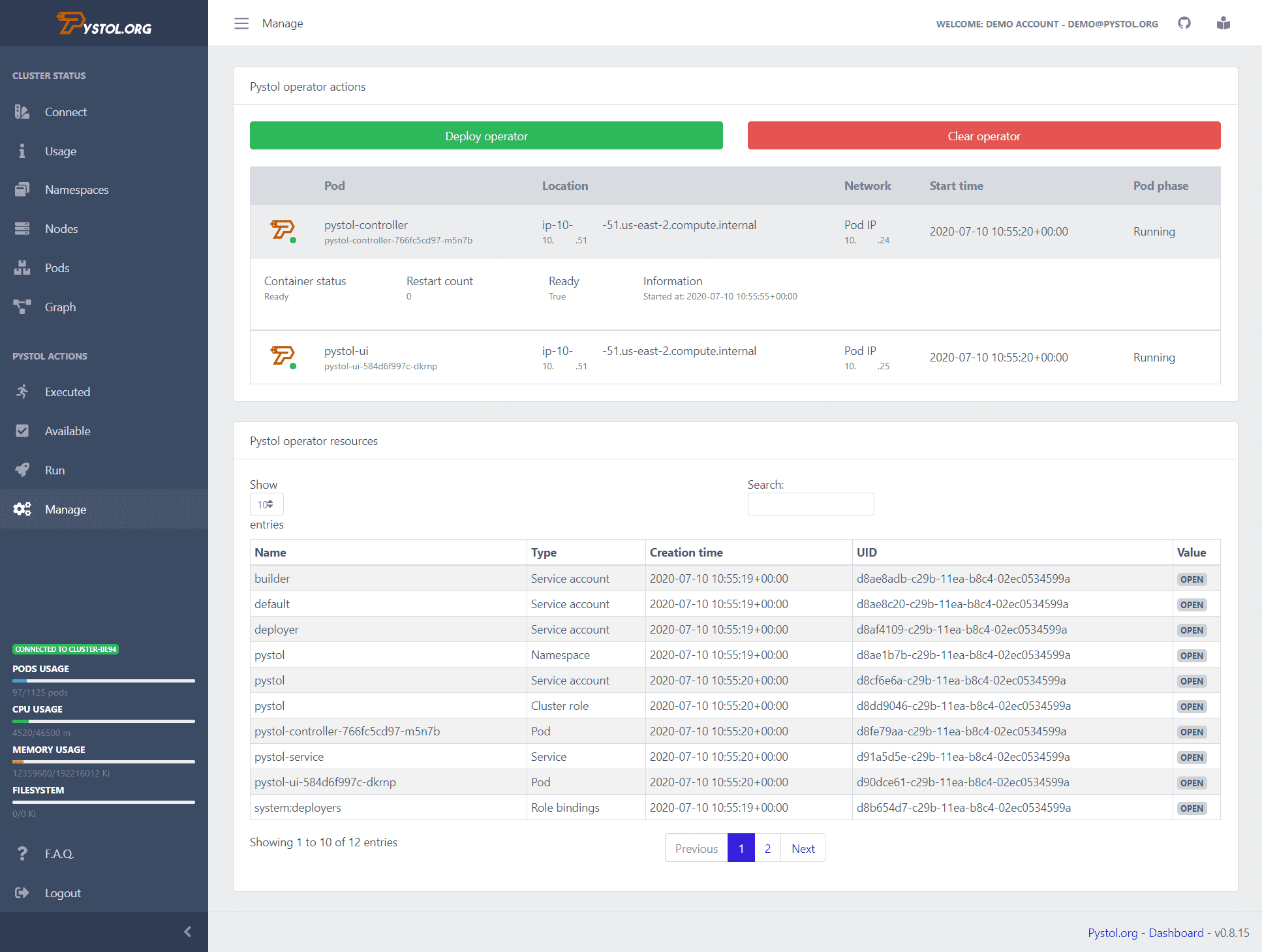
Muffig
Muffig ist ein Proxy zum Testen Ihrer Resilienz- und Fehlertoleranzmuster für Ausfälle verteilter Systeme in der realen Welt. Es kann die Transportebene (Schicht 4), die TCP-Sitzungsebene (Schicht 5) und die HTTP-Protokollebene (Schicht 7) manipulieren.
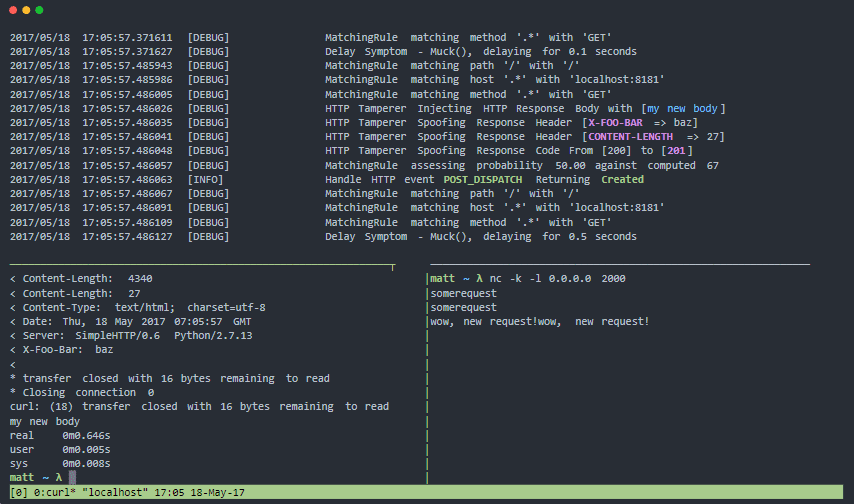
Muxy-Funktionen:
- Modulare Architektur und leicht erweiterbar
- Hat einen offiziellen Docker-Container
- Einfach zu installieren, keine Abhängigkeiten erforderlich.
- Ideal zum kontinuierlichen Testen der Belastbarkeit
- Simuliert Netzwerkkonnektivitätsprobleme für verteilte Systeme und mobile Geräte
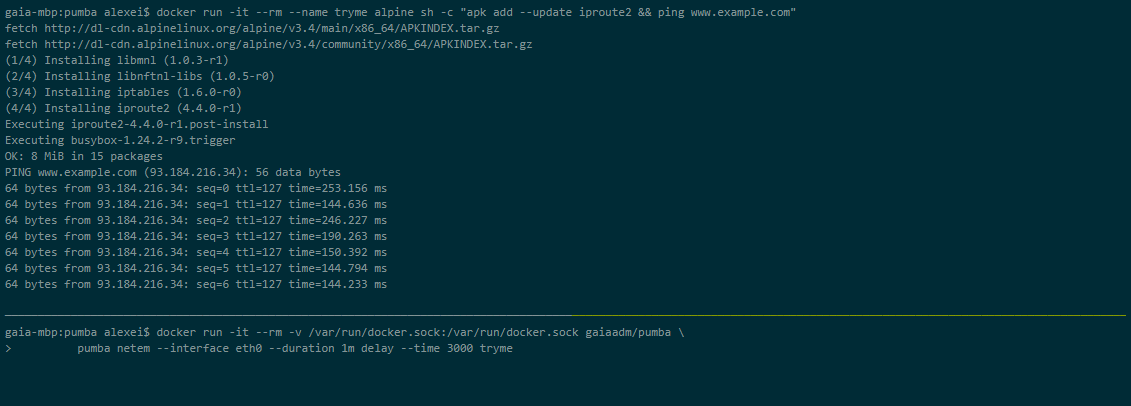
Pumba
Pumba ist ein Befehlszeilentool, das Chaostests für Docker-Container durchführt. Mit Pumba lassen Sie die Docker-Container der Anwendung absichtlich abstürzen, um zu sehen, wie das System reagiert. Sie können auch Stresstests für die Containerressourcen wie CPU, Speicher, Dateisystem, Ein-/Ausgabe usw. durchführen.
Sie können Pumba auch auf einem Kubernetes-Cluster ausführen. Sie müssen DaemonSets verwenden, um Pumba auf Kubernetes-Knoten bereitzustellen. Sie können mehrere Pumba-Container verwenden, um mehrere Pumba-Befehle im selben DaemonSet auszuführen.
Chaosklinge
Chaosklinge ist ein Open-Source-Tool, um Experimente in die Systeme von Alibaba einzufügen. Es testet alle Fehler, mit denen Alibaba in den letzten zehn Jahren konfrontiert war, und wendet Best Practices an, um sie zu vermeiden. Es folgt Chaos-Engineering-Prinzipien, um die Fehlertoleranz verteilter Systeme zu überprüfen.
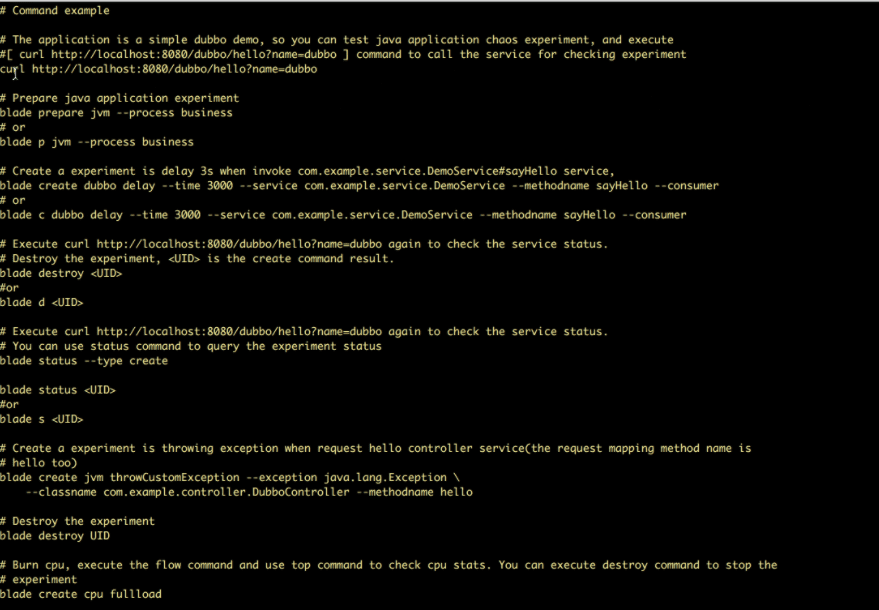
ChaosBlade-Funktionen:
- Bietet experimentelle Szenarien für mehrere Ressourcen wie CPU, Netzwerk, Arbeitsspeicher, Festplatte usw.
- Stellt experimentelle Szenarien für Knoten, Netzwerke und Pods auf der Kubernetes-Plattform bereit
- Bietet benutzerfreundliche CLI-Befehle zum Ausführen von Experimenten
Lackmus
Lackmus folgt Cloud-nativen Chaos-Engineering-Prinzipien. Die Mission des Lackmus-Tools besteht darin, ein vollständiges Framework zum Auffinden von Schwachstellen in Ihren Kubernetes-Systemen und Ihren laufenden Anwendungen auf Kubernetes bereitzustellen.
Es hat einen Chaos-Operator und die CRDs (CustomResourceDefinitions) darum herum, die Plug-and-Play-Fähigkeit ermöglichen. Es geht darum, Ihre Chaoslogik in ein Docker-Image zu packen, es in ein Lackmus-Framework zu werfen und sie mithilfe der CRDs zu orchestrieren.

Lackmus-Funktionen:
- Hilft Site Reliability-Ingenieuren und -Entwicklern, Schwachstellen im Kubernetes-System zu finden
- Stellt gebrauchsfertige generische Experimente bereit
- Bietet Chaos-API für Chaos-Workflow-Management
- Litmus SDK unterstützt Go, Python und Ansible, um Ihre eigenen Experimente zu erstellen.
Gremlin
Gremlin hilft Ingenieuren, widerstandsfähigere Software zu entwickeln. Es bietet eine Plattform, um Chaos-Engineering-Experimente sicher und unkompliziert durchzuführen.

Mit Gremlin können Sie Fehler in Hosts oder Containern nachdenklich injizieren, unabhängig davon, wo sie sich befinden, ob es sich um die Public Cloud oder Ihr eigenes Rechenzentrum handelt.
Gremlin-Funktionen:
- Installiert einen einfachen Agenten auf Ihren Hosts oder Containern, um Fehler zu injizieren
- Bietet mehr als 10 verschiedene Infrastruktur-Angriffsmodi
- Mit Zustandsgremlins können Sie die Systemzeit manipulieren, Hosts herunterfahren oder neu starten und Prozessoren beenden.
- Netzwerkgremlins können Latenz injizieren, um Paketverluste einzuführen oder den Datenverkehr zu unterbrechen.
- Die Alfi-Bibliotheksangriffe von Gremlin können über die Web-App konfiguriert, gestartet und gestoppt werden. API oder CLI
- Ermöglicht es Ihnen, den Explosionsradius, den Sie angreifen möchten, genau anzuvisieren
- Ermöglicht es Ihnen, alle Angriffe zu stoppen und das System in einen stabilen Zustand zurückzusetzen
Steadybit
Steadybit zielt darauf ab, Ausfallzeiten proaktiv zu reduzieren und bietet Einblick in Systemprobleme. Sie können dieses Tool lokal in Ihrer Infrastruktur oder Cloud as a Service (SaaS) ausführen.
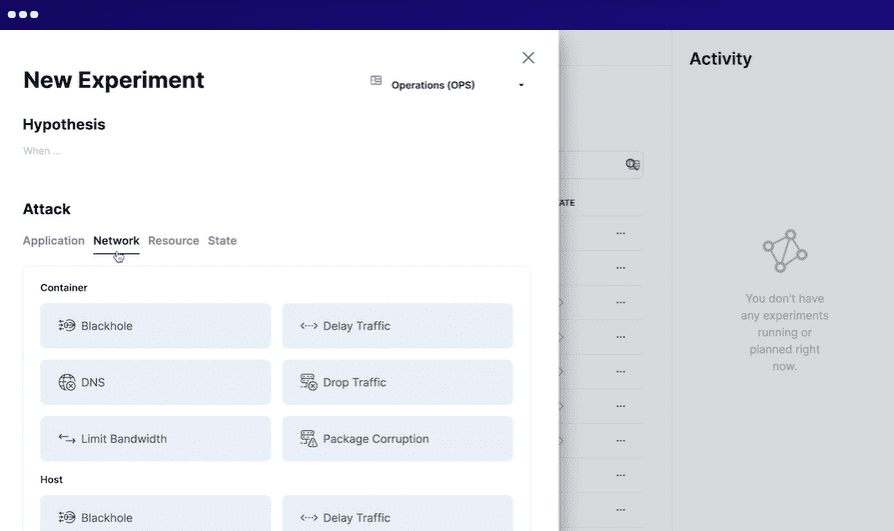
Um Steadybit zu verwenden, definieren Sie die Situation, simulieren die Experimente, führen die simulierten Experimente in der Produktion aus und automatisieren alle Experimente. Es führt intelligente Agenten auf Ihrem System aus, um potenzielle Probleme und Schwachstellen zu entdecken. Es lässt sich problemlos in mehrere Systeme integrieren.
Fazit
Seien Sie mutig genug, die Prinzipien des Chaos Engineering anzuwenden und testen Sie Ihre Produktion mit den oben genannten Tools. Diese Tools helfen Ihnen dabei, mehrere nicht identifizierte Schwachstellen in Ihrem System zu finden und Ihr System widerstandsfähiger zu machen.