Google JAX oder Just After Execution ist ein von Google entwickeltes Framework zur Beschleunigung von maschinellen Lernaufgaben.
Sie können es als Bibliothek für Python betrachten, die bei der schnelleren Ausführung von Aufgaben, wissenschaftlichen Berechnungen, Funktionstransformationen, Deep Learning, neuronalen Netzen und vielem mehr hilft.
Inhaltsverzeichnis
Über Google JAX
Das grundlegendste Berechnungspaket in Python ist das NumPy-Paket, das alle Funktionen wie Aggregationen, Vektoroperationen, lineare Algebra, n-dimensionale Array- und Matrixmanipulationen und viele andere erweiterte Funktionen enthält.
Was wäre, wenn wir die mit NumPy durchgeführten Berechnungen weiter beschleunigen könnten – insbesondere für riesige Datensätze?
Haben wir etwas, das ohne Codeänderungen auf verschiedenen Prozessortypen wie GPU oder TPU gleich gut funktionieren könnte?
Wie wäre es, wenn das System zusammensetzbare Funktionstransformationen automatisch und effizienter durchführen könnte?
Google JAX ist eine Bibliothek (oder Framework, wie Wikipedia sagt), die genau das tut und vielleicht noch viel mehr. Es wurde entwickelt, um die Leistung zu optimieren und maschinelles Lernen (ML) und Deep-Learning-Aufgaben effizient auszuführen. Google JAX bietet die folgenden Transformationsfunktionen, die es gegenüber anderen ML-Bibliotheken einzigartig machen und bei fortgeschrittener wissenschaftlicher Berechnung für Deep Learning und neuronale Netze helfen:
- Automatische Differenzierung
- Automatische Vektorisierung
- Automatische Parallelisierung
- Just-in-time (JIT)-Kompilierung
Die einzigartigen Funktionen von Google JAX
Alle Transformationen verwenden XLA (Accelerated Linear Algebra) für höhere Leistung und Speicheroptimierung. XLA ist eine domänenspezifische optimierende Compiler-Engine, die lineare Algebra ausführt und TensorFlow-Modelle beschleunigt. Die Verwendung von XLA zusätzlich zu Ihrem Python-Code erfordert keine wesentlichen Codeänderungen!
Lassen Sie uns jede dieser Funktionen im Detail untersuchen.
Funktionen von Google JAX
Google JAX verfügt über wichtige zusammensetzbare Transformationsfunktionen, um die Leistung zu verbessern und Deep-Learning-Aufgaben effizienter auszuführen. Zum Beispiel die automatische Differenzierung, um den Gradienten einer Funktion zu erhalten und Ableitungen beliebiger Ordnung zu finden. Ebenso Autoparallelisierung und JIT, um mehrere Aufgaben parallel auszuführen. Diese Transformationen sind der Schlüssel für Anwendungen wie Robotik, Spiele und sogar Forschung.
Eine zusammensetzbare Transformationsfunktion ist eine reine Funktion, die einen Datensatz in eine andere Form umwandelt. Sie werden zusammensetzbar genannt, da sie in sich abgeschlossen sind (dh diese Funktionen haben keine Abhängigkeiten zum Rest des Programms) und zustandslos sind (dh dieselbe Eingabe führt immer zu derselben Ausgabe).
Y(x) = T: (f(x))
In der obigen Gleichung ist f(x) die ursprüngliche Funktion, auf die eine Transformation angewendet wird. Y(x) ist die resultierende Funktion nach Anwendung der Transformation.
Wenn Sie beispielsweise eine Funktion mit dem Namen „total_bill_amt“ haben und das Ergebnis als Funktionstransformation wünschen, können Sie einfach die gewünschte Transformation verwenden, sagen wir, Gradient (Grad):
grad_total_bill = grad(total_bill_amt)
Durch die Transformation numerischer Funktionen mit Funktionen wie grad() können wir leicht ihre Ableitungen höherer Ordnung erhalten, die wir ausgiebig in Deep-Learning-Optimierungsalgorithmen wie Gradientenabstieg verwenden können, wodurch die Algorithmen schneller und effizienter werden. In ähnlicher Weise können wir mit jit() Python-Programme just-in-time (faul) kompilieren.
#1. Automatische Differenzierung
Python verwendet die Autograd-Funktion, um NumPy und nativen Python-Code automatisch zu unterscheiden. JAX verwendet eine modifizierte Version von Autograd (d. h. Grad) und kombiniert XLA (Accelerated Linear Algebra), um eine automatische Differenzierung durchzuführen und Ableitungen beliebiger Ordnung für GPU (Graphic Processing Units) und TPU (Tensor Processing Units) zu finden.]
Kurzer Hinweis zu TPU, GPU und CPU: Die CPU oder Central Processing Unit verwaltet alle Vorgänge auf dem Computer. GPU ist ein zusätzlicher Prozessor, der die Rechenleistung erhöht und High-End-Operationen ausführt. TPU ist eine leistungsstarke Einheit, die speziell für komplexe und schwere Arbeitslasten wie KI und Deep-Learning-Algorithmen entwickelt wurde.
Ähnlich wie die autograd-Funktion, die durch Schleifen, Rekursionen, Verzweigungen usw. unterscheiden kann, verwendet JAX die grad()-Funktion für Gradienten im umgekehrten Modus (Backpropagation). Außerdem können wir mit grad eine Funktion von jeder Ordnung unterscheiden:
grad(grad(grad(sin θ))) (1.0)
Autodifferenzierung höherer Ordnung
Wie wir bereits erwähnt haben, ist grad sehr nützlich, um die partiellen Ableitungen einer Funktion zu finden. Wir können eine partielle Ableitung verwenden, um den Gradientenabfall einer Kostenfunktion in Bezug auf die neuronalen Netzwerkparameter beim Deep Learning zu berechnen, um Verluste zu minimieren.
Partielle Ableitung berechnen
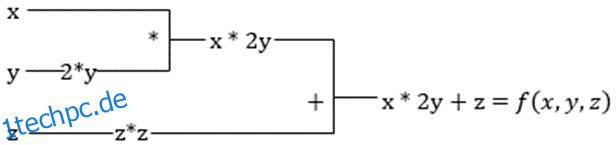
Angenommen, eine Funktion hat mehrere Variablen, x, y und z. Das Ermitteln der Ableitung einer Variablen durch Konstanthalten der anderen Variablen wird als partielle Ableitung bezeichnet. Angenommen, wir haben eine Funktion,
f(x,y,z) = x + 2y + z2
Beispiel zur Darstellung der partiellen Ableitung
Die partielle Ableitung von x ist ∂f/∂x, was uns sagt, wie sich eine Funktion für eine Variable ändert, wenn andere konstant sind. Wenn wir dies manuell durchführen, müssen wir ein Programm zum Differenzieren schreiben, es auf jede Variable anwenden und dann den Gradientenabfall berechnen. Dies würde für mehrere Variablen zu einer komplexen und zeitaufwändigen Angelegenheit.
Die automatische Differenzierung zerlegt die Funktion in eine Reihe elementarer Operationen wie +, -, *, / oder sin, cos, tan, exp usw. und wendet dann die Kettenregel an, um die Ableitung zu berechnen. Wir können dies sowohl im Vorwärts- als auch im Rückwärtsmodus tun.
Das ist es nicht! All diese Berechnungen laufen so schnell ab (nun, denken Sie an eine Million Berechnungen ähnlich der oben genannten und die Zeit, die es dauern kann!). XLA kümmert sich um die Geschwindigkeit und Leistung.
#2. Beschleunigte Lineare Algebra
Nehmen wir die vorherige Gleichung. Ohne XLA benötigt die Berechnung drei (oder mehr) Kernel, wobei jeder Kernel eine kleinere Aufgabe ausführt. Zum Beispiel,
Kernel k1 –> x * 2y (Multiplikation)
k2 –> x * 2y + z (Addition)
k3 –> Reduktion
Wenn die gleiche Aufgabe vom XLA ausgeführt wird, kümmert sich ein einzelner Kernel um alle Zwischenoperationen, indem er sie fusioniert. Die Zwischenergebnisse elementarer Operationen werden gestreamt, anstatt sie im Speicher zu speichern, wodurch Speicher gespart und die Geschwindigkeit erhöht wird.
#3. Just-in-Time-Zusammenstellung
JAX verwendet intern den XLA-Compiler, um die Ausführungsgeschwindigkeit zu erhöhen. XLA kann die Geschwindigkeit von CPU, GPU und TPU steigern. All dies ist mit der JIT-Code-Ausführung möglich. Um dies zu verwenden, können wir jit via import verwenden:
from jax import jit def my_function(x): …………some lines of code my_function_jit = jit(my_function)
Eine andere Möglichkeit besteht darin, jit über die Funktionsdefinition zu dekorieren:
@jit def my_function(x): …………some lines of code
Dieser Code ist viel schneller, da die Transformation die kompilierte Version des Codes an den Aufrufer zurückgibt, anstatt den Python-Interpreter zu verwenden. Dies ist besonders nützlich für Vektoreingaben wie Arrays und Matrizen.
Dasselbe gilt auch für alle vorhandenen Python-Funktionen. Zum Beispiel Funktionen aus dem Paket NumPy. In diesem Fall sollten wir jax.numpy als jnp statt als NumPy importieren:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Sobald Sie dies getan haben, ersetzt das Kern-JAX-Array-Objekt namens DeviceArray das standardmäßige NumPy-Array. DeviceArray ist faul – die Werte werden im Beschleuniger gehalten, bis sie benötigt werden. Dies bedeutet auch, dass das JAX-Programm nicht darauf wartet, dass Ergebnisse an das aufrufende (Python-)Programm zurückgegeben werden, und somit einem asynchronen Versand folgt.
#4. Automatische Vektorisierung (vmap)
In einer typischen Welt des maschinellen Lernens haben wir Datensätze mit einer Million oder mehr Datenpunkten. Höchstwahrscheinlich würden wir einige Berechnungen oder Manipulationen an jedem oder den meisten dieser Datenpunkte durchführen – was eine sehr zeit- und speicherintensive Aufgabe ist! Wenn Sie zum Beispiel das Quadrat von jedem der Datenpunkte im Datensatz finden möchten, würden Sie als erstes daran denken, eine Schleife zu erstellen und das Quadrat nacheinander zu nehmen – argh!
Wenn wir diese Punkte als Vektoren erstellen, könnten wir alle Quadrate auf einmal erstellen, indem wir Vektor- oder Matrixmanipulationen an den Datenpunkten mit unserem Lieblings-NumPy durchführen. Und wenn Ihr Programm das automatisch machen könnte – können Sie mehr verlangen? Genau das macht JAX! Es kann alle Ihre Datenpunkte automatisch vektorisieren, sodass Sie problemlos alle Operationen an ihnen ausführen können – wodurch Ihre Algorithmen viel schneller und effizienter werden.
JAX verwendet die vmap-Funktion für die automatische Vektorisierung. Betrachten Sie das folgende Array:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Indem Sie genau das obige tun, wird die Quadratmethode für jeden Punkt im Array ausgeführt. Aber wenn Sie Folgendes tun:
vmap(jnp.square(x))
Die Methode square wird nur einmal ausgeführt, da die Datenpunkte jetzt automatisch mit der vmap-Methode vektorisiert werden, bevor die Funktion ausgeführt wird, und die Schleifenbildung auf die elementare Ebene der Operation heruntergedrückt wird – was zu einer Matrixmultiplikation anstelle einer skalaren Multiplikation führt und somit eine bessere Leistung ergibt .
#5. SPMD-Programmierung (pmap)
SPMD – oder Single Program Multiple Data-Programmierung ist in Deep-Learning-Kontexten unerlässlich – Sie würden oft dieselben Funktionen auf verschiedene Datensätze anwenden, die sich auf mehreren GPUs oder TPUs befinden. JAX hat eine Funktion namens pump, die eine parallele Programmierung auf mehreren GPUs oder einem beliebigen Beschleuniger ermöglicht. Wie JIT werden Programme, die pmap verwenden, von XLA kompiliert und simultan auf allen Systemen ausgeführt. Diese automatische Parallelisierung funktioniert sowohl für Vorwärts- als auch für Rückwärtsberechnungen.
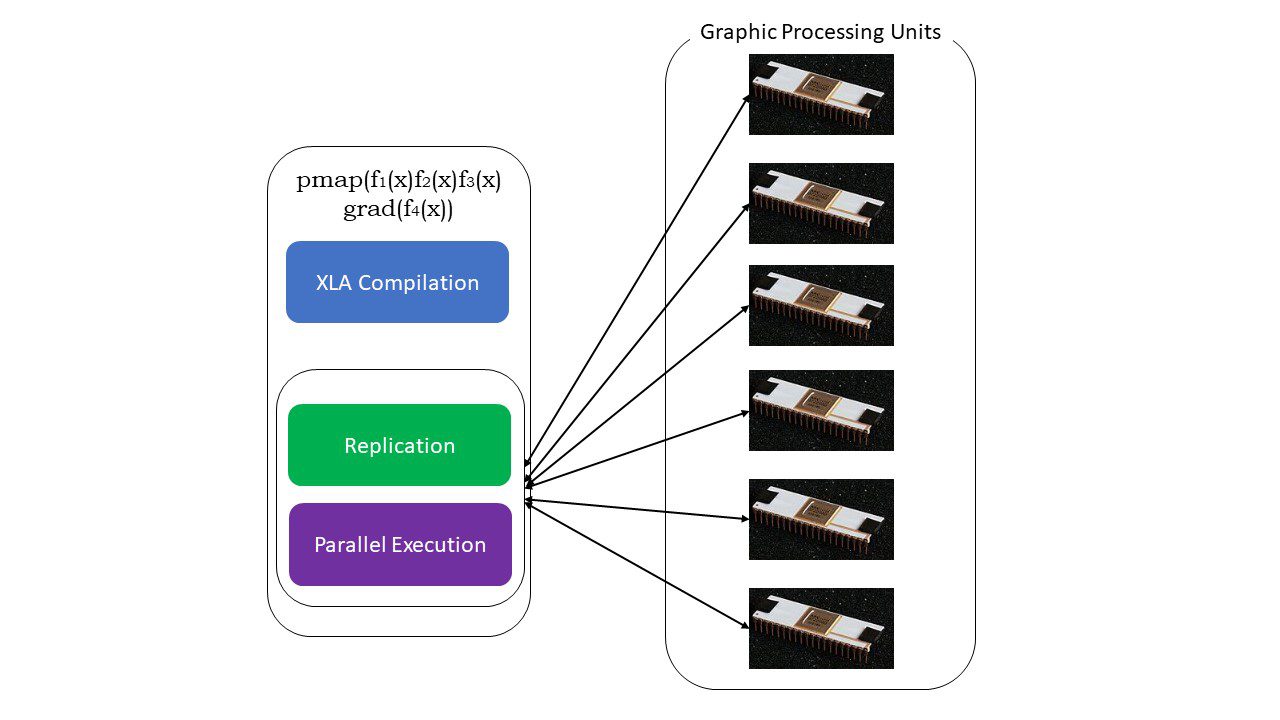 Wie funktioniert pmap
Wie funktioniert pmap
Wir können auch mehrere Transformationen auf einmal in beliebiger Reihenfolge auf jede Funktion anwenden als:
pmap(vmap(jit(grad (f(x)))))
Mehrere zusammensetzbare Transformationen
Einschränkungen von Google JAX
Google JAX-Entwickler haben gut darüber nachgedacht, Deep-Learning-Algorithmen zu beschleunigen und gleichzeitig all diese großartigen Transformationen einzuführen. Die wissenschaftlichen Berechnungsfunktionen und -pakete entsprechen NumPy, sodass Sie sich keine Gedanken über die Lernkurve machen müssen. JAX hat jedoch die folgenden Einschränkungen:
- Google JAX befindet sich noch in den frühen Entwicklungsstadien, und obwohl sein Hauptzweck die Leistungsoptimierung ist, bietet es keinen großen Nutzen für die CPU-Berechnung. NumPy scheint eine bessere Leistung zu erbringen, und die Verwendung von JAX erhöht möglicherweise nur den Overhead.
- JAX befindet sich noch in der Forschung oder in einem frühen Stadium und muss noch feiner abgestimmt werden, um die Infrastrukturstandards von Frameworks wie TensorFlow zu erreichen, die etablierter sind und über mehr vordefinierte Modelle, Open-Source-Projekte und Lernmaterial verfügen.
- Derzeit unterstützt JAX kein Windows-Betriebssystem – Sie benötigen eine virtuelle Maschine, damit es funktioniert.
- JAX funktioniert nur mit reinen Funktionen – also solchen, die keine Seiteneffekte haben. Für Funktionen mit Seiteneffekten ist JAX möglicherweise keine gute Option.
So installieren Sie JAX in Ihrer Python-Umgebung
Wenn Sie Python auf Ihrem System eingerichtet haben und JAX auf Ihrem lokalen Computer (CPU) ausführen möchten, verwenden Sie die folgenden Befehle:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Wenn Sie Google JAX auf einer GPU oder TPU ausführen möchten, befolgen Sie die Anweisungen auf GitHub-JAX Seite. Um Python einzurichten, besuchen Sie die offizielle Python-Downloads Seite.
Fazit
Google JAX eignet sich hervorragend zum Schreiben effizienter Deep-Learning-Algorithmen, Robotik und Forschung. Trotz der Einschränkungen wird es ausgiebig mit anderen Frameworks wie Haiku, Flax und vielen mehr verwendet. Sie werden einschätzen können, was JAX beim Ausführen von Programmen tut, und die Zeitunterschiede beim Ausführen von Code mit und ohne JAX sehen. Sie können mit dem Lesen beginnen offizielle Google JAX-Dokumentationdie ziemlich umfangreich ist.