Web Scraping mit Perl: Daten automatisch aus dem Web extrahieren
Einführung:
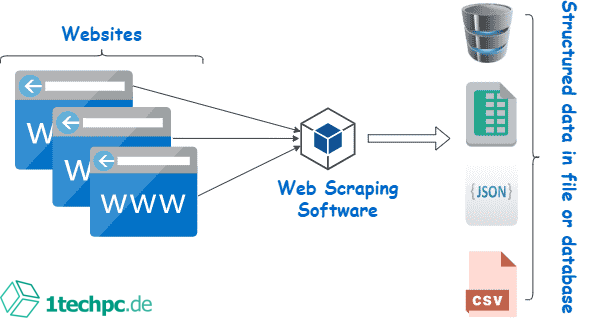
In der heutigen Zeit ist der Zugriff auf Informationen von entscheidender Bedeutung. Sei es für Recherchen, um Geschäftsstrategien zu entwickeln oder einfach nur, um auf dem neuesten Stand zu bleiben. Das Web enthält jedoch eine enorme Menge an Daten, die manuell gesammelt werden müssen. Hier kommt Web Scraping ins Spiel. Mit Web Scraping-Tools können große Mengen von Daten aus dem Internet automatisch extrahiert werden. In diesem Artikel betrachten wir die Möglichkeiten des Web Scraping mit Perl und wie Sie Daten effizient aus dem Web extrahieren können.
Inhaltsverzeichnis
Warum Web Scraping?
Web Scraping ist eine effektive Methode, um Daten aus dem Web automatisch zu extrahieren. Es bietet eine Vielzahl von Vorteilen, darunter:
1. Zeitersparnis:
Durch die Automatisierung des Extraktionsprozesses sparen Sie Zeit und können Ihre Ressourcen für wichtigere Aspekte Ihres Unternehmens einsetzen.
2. Datenqualität:
Web Scraping ermöglicht es Ihnen, konsistente und strukturierte Daten zu erhalten, die genau Ihren Anforderungen entsprechen. Sie haben die Kontrolle über die gewünschten Datenfelder und können diese in einem geeigneten Format speichern.
3. Konkurrenzanalyse:
Durch das Scrapen von Daten können Sie wertvolle Einblicke in Ihre Konkurrenz gewinnen. Sie können herausfinden, welche Produkte oder Dienstleistungen sie anbieten, ihre Preise vergleichen und gezielt auf dem Markt agieren.
Web Scraping mit Perl:
Vorteile von Perl:
Perl ist eine leistungsstarke und vielseitige Skriptsprache, die sich hervorragend für das Web Scraping eignet. Perl bietet eine große Auswahl an Modulen und Bibliotheken, die speziell für das Extrahieren von Daten aus dem Web entwickelt wurden. Dank seiner Syntax und Untersützung für reguläre Ausdrücke ist Perl eine effiziente Wahl für Web Scraping-Projekte.
Mögliche Einsatzgebiete:
Perl kann in verschiedenen Szenarien für das Web-Scraping eingesetzt werden. Hier sind einige Beispiele, wie Perl eingesetzt werden kann:
1. Datenextraktion für Forschungszwecke:
Perl kann verwendet werden, um akademische Forschungsprojekte zu unterstützen. Indem Sie gezielt Daten aus wissenschaftlichen Artikeln extrahieren, können Sie wertvolle Erkenntnisse gewinnen und bestimmte Forschungsfelder analysieren.
2. Preisvergleiche:
Perl ist eine großartige Wahl, wenn es darum geht, Preise von Produkten auf verschiedenen Websites zu sammeln und zu vergleichen. Sie können automatisch die besten Angebote finden und Zeit beim Online-Shopping sparen.
3. Lead-Generierung:
Wenn Sie ein Unternehmen besitzen, können Sie Perl verwenden, um potenzielle Kunden zu finden und Kontaktdaten wie E-Mails oder Telefonnummern zu extrahieren. Dies kann helfen, Ihre Vertriebs- und Marketingaktivitäten anzukurbeln.
Web Scraping Workflow:
Der Prozess des Web Scraping mit Perl kann in mehrere Phasen unterteilt werden:
1. Analyse:
Definieren Sie Ihre Anforderungen und entscheiden Sie, welche Informationen Sie sammeln möchten. Identifizieren Sie die relevanten Websites und Struktur der Webseite, von der Sie Daten extrahieren möchten.
2. Code-Entwicklung:
Nach der Analyse können Sie den Scraping-Code in Perl mithilfe der verfügbaren Module und Bibliotheken entwickeln. Hier können Sie reguläre Ausdrücke oder XPath verwenden, um die gewünschten Datenpunkte zu extrahieren.
3. Extraktion der Daten:
Führen Sie den entwickelten Code aus, um die Daten von den entsprechenden Websites zu extrahieren. Überprüfen Sie die Genauigkeit der erfassten Daten und nehmen Sie gegebenenfalls Anpassungen an Ihrem Code vor.
4. Datenverarbeitung und -speicherung:
Nach der Extraktion der Daten können Sie diese weiterverarbeiten und in einem geeigneten Format speichern. Dies kann eine Datenbank, eine CSV-Datei oder ein anderes Dateiformat sein, das Ihren Anforderungen entspricht.
Sicherheitsaspekte:
Beim Web Scraping mit Perl sollten auch Sicherheitsaspekte berücksichtigt werden. Hier sind einige bewährte Maßnahmen, um sicherzustellen, dass Sie keine rechtlichen oder ethischen Probleme haben:
1. Einhaltung der Nutzungsbedingungen:
Stellen Sie sicher, dass Sie die Nutzungsbedingungen der jeweiligen Website verstehen und einhalten. Einige Websites haben Regeln gegen Web Scraping oder begrenzen die Anzahl der Anfragen, die Sie senden können.
2. Robots.txt beachten:
Überprüfen Sie die robots.txt-Dateien der Websites, von denen Sie Daten extrahieren möchten. Diese Dateien geben Anweisungen darüber, welche Teile der Website gecrawlt werden dürfen und welche nicht.
3. IP-Rotierung:
Um das Risiko von Blockierungen oder IP-Sperren zu minimieren, verwenden Sie IP-Rotierung. Dadurch ändert sich Ihre IP-Adresse für jede Anfrage, und Sie werden weniger wahrscheinlich als ein automatisches Scraping-Tool erkannt.
FAQs:
1. Ist Web Scraping legal?
Ja, Web Scraping ist grundsätzlich legal, solange Sie die Nutzungsbedingungen und geltende Gesetze einhalten. Es ist jedoch wichtig zu beachten, dass einige Websites das Scraping explizit verbieten oder einschränken können.
2. Was ist der Unterschied zwischen Web Crawling und Web Scraping?
Web Crawling bezieht sich auf den automatisierten Prozess des Durchsuchens des Internets, um Informationen zu sammeln. Web Scraping hingegen bezieht sich auf das Extrahieren oder Scannen von spezifischen Datenpunkten aus einer bestimmten Webseite.
3. Welche Herausforderungen gibt es beim Web Scraping?
Einige Herausforderungen beim Web Scraping sind die dynamische Struktur von Websites, Captchas zum Schutz vor Bots sowie die Notwendigkeit, rechtliche und ethische Aspekte zu berücksichtigen.
4. Gibt es Alternativen zu Perl für Web Scraping?
Ja, es gibt viele andere Programmiersprachen wie Python, Ruby oder JavaScript, die ebenfalls für das Web Scraping verwendet werden können. Die Wahl der Sprache hängt von den individuellen Anforderungen und Vorlieben ab.
5. Wie kann ich meine gescrapten Daten analysieren und visualisieren?
Es gibt verschiedene Tools und Bibliotheken wie Pandas, Matplotlib oder Tableau, mit denen Sie Ihre gescrapten Daten analysieren und visualisieren können. Diese Tools bieten Funktionen zur Datenmanipulation, statistischen Analysen und Erstellung von Diagrammen.
Schlussfolgerung:
Web Scraping mit Perl eröffnet eine Vielzahl von Möglichkeiten, um Daten effizient aus dem Web zu extrahieren. Die Kombination von Perl und spezifischen Modulen ermöglicht es Ihnen, große Mengen an Informationen zu sammeln und weiterzuverarbeiten. Es ist jedoch wichtig, die rechtlichen und ethischen Aspekte des Scrapings zu berücksichtigen, um unnötige Probleme zu vermeiden. Nutzen Sie die Vorteile des Web Scrapings, um wertvolle Informationen zu erhalten und Ihr Unternehmen erfolgreicher zu machen.
FAQs:
1. Ist Web Scraping legal?
Ja, Web Scraping ist grundsätzlich legal, solange Sie die Nutzungsbedingungen und geltende Gesetze einhalten. Es ist jedoch wichtig zu beachten, dass einige Websites das Scraping explizit verbieten oder einschränken können.
2. Was ist der Unterschied zwischen Web Crawling und Web Scraping?
Web Crawling bezieht sich auf den automatisierten Prozess des Durchsuchens des Internets, um Informationen zu sammeln. Web Scraping hingegen bezieht sich auf das Extrahieren oder Scannen von spezifischen Datenpunkten aus einer bestimmten Webseite.
3. Welche Herausforderungen gibt es beim Web Scraping?
Einige Herausforderungen beim Web Scraping sind die dynamische Struktur von Websites, Captchas zum Schutz vor Bots sowie die Notwendigkeit, rechtliche und ethische Aspekte zu berücksichtigen.
4. Gibt es Alternativen zu Perl für Web Scraping?
Ja, es gibt viele andere Programmiersprachen wie Python, Ruby oder JavaScript, die ebenfalls für das Web Scraping verwendet werden können. Die Wahl der Sprache hängt von den individuellen Anforderungen und Vorlieben ab.
5. Wie kann ich meine gescrapten Daten analysieren und visualisieren?
Es gibt verschiedene Tools und Bibliotheken wie Pandas, Matplotlib oder Tableau, mit denen Sie Ihre gescrapten Daten analysieren und visualisieren können. Diese Tools bieten Funktionen zur Datenmanipulation, statistischen Analysen und Erstellung von Diagrammen.