
In der heutigen datengesteuerten Welt ist die traditionelle Methode der manuellen Datenerfassung veraltet. Ein Computer mit Internetanschluss auf jedem Schreibtisch machte das Internet zu einer riesigen Datenquelle. Die effizientere und zeitsparendere moderne Methode zur Datenerhebung ist daher das Web Scraping. Und wenn es um Web Scraping geht, hat Python ein Tool namens Beautiful Soup. In diesem Beitrag werde ich Sie durch die Installationsschritte von Beautiful Soup führen, um mit Web Scraping zu beginnen.
Bevor Sie Beautiful Soup installieren und damit arbeiten, lassen Sie uns herausfinden, warum Sie sich dafür entscheiden sollten.
Inhaltsverzeichnis
Was ist eine schöne Suppe?
Nehmen wir an, Sie recherchieren zu den „Auswirkungen von COVID auf die Gesundheit der Menschen“ und haben einige Webseiten mit relevanten Daten gefunden. Aber was ist, wenn sie Ihnen keine Download-Option mit einem Klick anbieten, um ihre Daten auszuleihen? Hier kommt die Beautiful Soup ins Spiel.
Beautiful Soup gehört zum Index der Python-Bibliotheken, um die Daten von Zielseiten abzurufen. Komfortabler ist es, Daten von HTML- oder XML-Seiten abzurufen.
Leonard Richardson brachte 2004 die Idee von Beautiful Soup zum Scrapen des Webs ans Licht. Aber sein Beitrag zu dem Projekt dauert bis heute an. Stolz aktualisiert er die Neuerscheinungen jeder Beautiful Soup auf seinem Twitter-Account.
Obwohl Beautiful Soup für Web Scraping mit Python 3.8 entwickelt wurde, funktioniert es sowohl mit Python 3 als auch mit Python 2.4 perfekt.
Häufig verwenden Websites Captcha-Schutz, um ihre Daten vor KI-Tools zu retten. In diesem Fall können ein paar Änderungen am „User-Agent“-Header in Beautiful Soup oder die Verwendung von Captcha-lösenden APIs einen zuverlässigen Browser imitieren und das Erkennungstool austricksen.
Wenn Sie jedoch keine Zeit haben, Beautiful Soup zu erkunden, oder möchten, dass das Scraping effizient und einfach durchgeführt wird, sollten Sie sich diese Web-Scraping-API nicht entgehen lassen, wo Sie einfach eine URL angeben und die Daten abrufen können deine Hände.
Wenn Sie bereits Programmierer sind, wird die Verwendung von Beautiful Soup zum Scrapen aufgrund seiner unkomplizierten Syntax beim Navigieren auf Webseiten und beim Extrahieren der gewünschten Daten basierend auf bedingtem Parsing nicht abschreckend sein. Gleichzeitig ist es auch anfängerfreundlich.
Obwohl Beautiful Soup nicht für fortgeschrittenes Scraping geeignet ist, funktioniert es am besten, die Daten aus Dateien zu schaben, die in Markup-Sprachen geschrieben sind.
Eine klare und detaillierte Dokumentation ist ein weiterer Pluspunkt, den Beautiful Soup eingepackt hat.
Lassen Sie uns einen einfachen Weg finden, schöne Suppe in Ihre Maschine zu bekommen.
Wie installiere ich Beautiful Soup für Web Scraping?
Pip – Ein müheloser Python-Paketmanager, der 2008 entwickelt wurde, ist heute ein Standardwerkzeug unter Entwicklern, um beliebige Python-Bibliotheken oder -Abhängigkeiten zu installieren.
Pip wird standardmäßig mit der Installation neuerer Python-Versionen geliefert. Wenn Sie also aktuelle Python-Versionen auf Ihrem System installiert haben, können Sie loslegen.
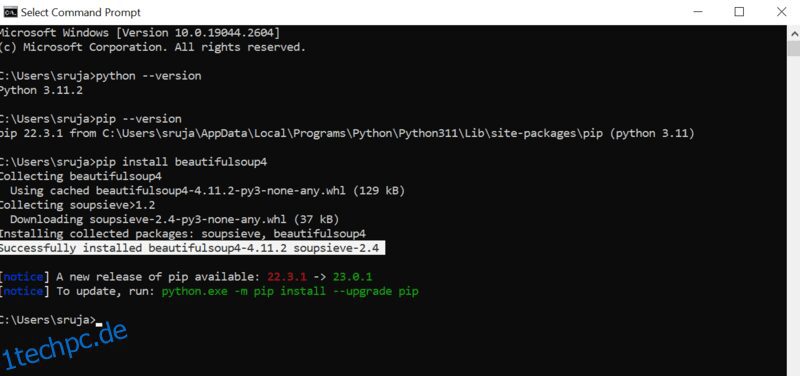
Öffnen Sie die Eingabeaufforderung und geben Sie den folgenden Pip-Befehl ein, um die schöne Suppe sofort zu installieren.
pip install beautifulsoup4
Sie werden etwas Ähnliches wie den folgenden Screenshot auf Ihrem Display sehen.
Stellen Sie sicher, dass Sie das PIP-Installationsprogramm auf die neueste Version aktualisiert haben, um häufige Fehler zu vermeiden.
Der Befehl zum Aktualisieren des Pip-Installationsprogramms auf die neueste Version lautet:
pip install --upgrade pip
Wir haben in diesem Beitrag erfolgreich die Hälfte des Bodens abgedeckt.
Jetzt haben Sie Beautiful Soup auf Ihrem Computer installiert, also lassen Sie uns in die Verwendung von Web Scraping eintauchen.
Wie importiere und arbeite ich mit Beautiful Soup für Web Scraping?
Geben Sie den folgenden Befehl in Ihre Python-IDE ein, um schöne Soup in das aktuelle Python-Skript zu importieren.
from bs4 import BeautifulSoup
Jetzt befindet sich die Beautiful Soup in Ihrer Python-Datei, die Sie zum Scrapen verwenden können.
Sehen wir uns ein Codebeispiel an, um zu erfahren, wie man die gewünschten Daten mit Beautiful Soup extrahiert.
Wir können Beautiful Soup anweisen, auf der Quellwebsite nach bestimmten HTML-Tags zu suchen und die in diesen Tags vorhandenen Daten zu kratzen.
In diesem Artikel verwende ich marketwatch.com, das die Aktienkurse verschiedener Unternehmen in Echtzeit aktualisiert. Lassen Sie uns einige Daten von dieser Website herausziehen, um sich mit der Beautiful Soup-Bibliothek vertraut zu machen.
Importieren Sie das „requests“-Paket, das es uns ermöglicht, HTTP-Anfragen zu empfangen und darauf zu antworten, und „urllib“, um die Webseite von ihrer URL zu laden.
from urllib.request import urlopen import requests
Speichern Sie den Webseiten-Link in einer Variablen, damit Sie später leicht darauf zugreifen können.
url="https://www.marketwatch.com/investing/stock/amzn"
Der nächste wäre, die Methode „urlopen“ aus der Bibliothek „urllib“ zu verwenden, um die HTML-Seite in einer Variablen zu speichern. Übergeben Sie die URL an die Funktion „urlopen“ und speichern Sie das Ergebnis in einer Variablen.
page = urlopen(url)
Erstellen Sie ein Beautiful Soup-Objekt und parsen Sie die gewünschte Webseite mit „html.parser“.
soup_obj = BeautifulSoup(page, 'html.parser')
Jetzt wird das gesamte HTML-Skript der anvisierten Webseite in der Variable „soup_obj“ gespeichert.
Bevor wir fortfahren, sehen wir uns den Quellcode der Zielseite an, um mehr über das HTML-Skript und die Tags zu erfahren.
Klicken Sie mit der rechten Maustaste auf eine beliebige Stelle auf der Webseite. Dann finden Sie eine Inspektionsoption, wie unten angezeigt.
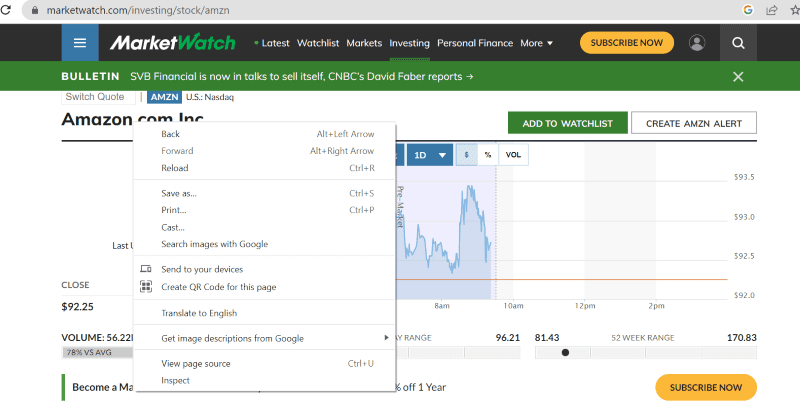
Klicken Sie auf Inspizieren, um den Quellcode anzuzeigen.
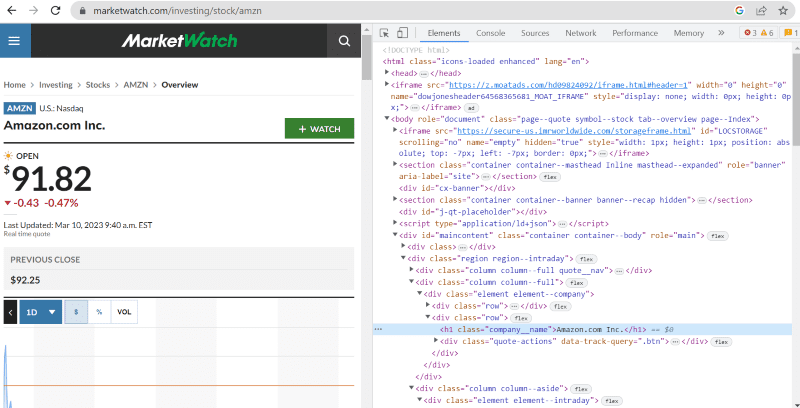
Im obigen Quellcode finden Sie Tags, Klassen und spezifischere Informationen zu jedem Element, das auf der Benutzeroberfläche der Website sichtbar ist.
Die „Find“-Methode in Beautiful Soup ermöglicht es uns, nach den angeforderten HTML-Tags zu suchen und die Daten abzurufen. Dazu geben wir den Klassennamen und Tags an die Methode, die bestimmte Daten extrahiert.
Zum Beispiel „Amazon.com Inc.“ die auf der Webseite angezeigt wird, hat den Klassennamen: ‚company__name‘, der unter ‚h1‘ getaggt ist. Wir können diese Informationen in die „find“-Methode eingeben, um das relevante HTML-Snippet in eine Variable zu extrahieren.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Lassen Sie uns das in der Variable „name“ gespeicherte HTML-Skript und den gewünschten Text auf dem Bildschirm ausgeben.
print(name) print(name.text)

Sie können die extrahierten Daten auf dem Bildschirm ausgeben sehen.
Web Scrape die IMDb-Website
Viele von uns suchen auf der Website von IMBb nach Filmbewertungen, bevor sie sich einen Film ansehen. Diese Demonstration gibt Ihnen eine Liste der am besten bewerteten Filme und hilft Ihnen, sich an die schöne Soup for Web Scraping zu gewöhnen.
Schritt 1: Importieren Sie die schönen Soup- und Request-Bibliotheken.
from bs4 import BeautifulSoup import requests
Schritt 2: Lassen Sie uns die URL, die wir scrapen möchten, einer Variablen namens „url“ zuweisen, um den Zugriff im Code zu erleichtern.
Das Paket „requests“ wird verwendet, um die HTML-Seite von der URL zu erhalten.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Schritt 3: Im folgenden Code-Snippet parsen wir die HTML-Seite der aktuellen URL, um ein schönes Soup-Objekt zu erstellen.
soup_obj = BeautifulSoup(url.text, 'html.parser')
Die Variable „soup_obj“ enthält nun das gesamte HTML-Skript der gewünschten Webseite, wie im folgenden Bild.
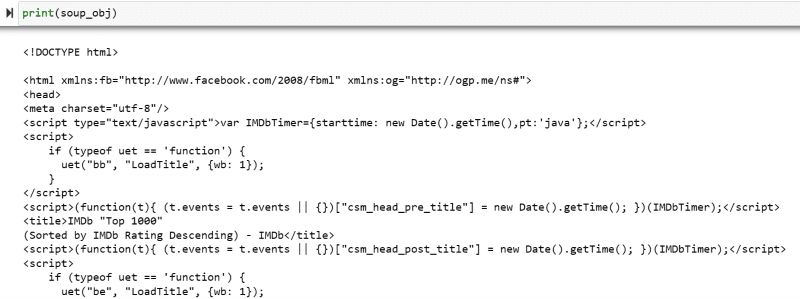
Untersuchen wir den Quellcode der Webseite, um das HTML-Skript der Daten zu finden, die wir auslesen möchten.
Bewegen Sie den Mauszeiger über das Webseitenelement, das Sie extrahieren möchten. Klicken Sie als Nächstes mit der rechten Maustaste darauf und wählen Sie die Option „Inspizieren“, um den Quellcode dieses bestimmten Elements anzuzeigen. Die folgenden Grafiken werden Sie besser führen.
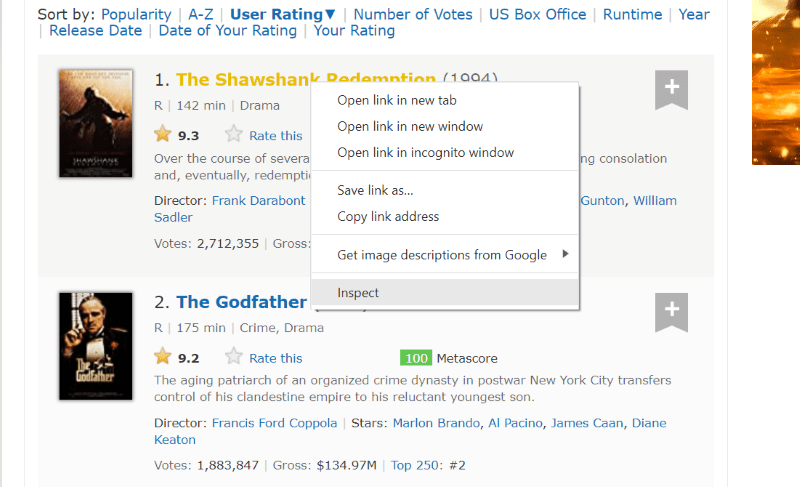
Die Klasse „lister-list“ enthält alle am besten bewerteten filmbezogenen Daten als Unterteilungen in aufeinanderfolgenden div-Tags.
Im HTML-Skript jeder Filmkarte haben wir unter der Klasse „lister-item mode-advanced“ ein Tag „h3“, das den Filmnamen, den Rang und das Erscheinungsjahr speichert, wie im folgenden Bild hervorgehoben.
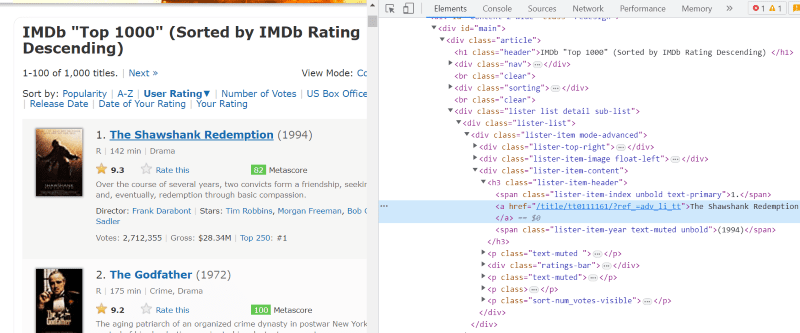
Hinweis: Die „Find“-Methode in Beautiful Soup sucht nach dem ersten Tag, das mit dem eingegebenen Namen übereinstimmt. Im Gegensatz zu „find“ sucht die Methode „find_all“ nach allen Tags, die mit der gegebenen Eingabe übereinstimmen.
Schritt 4: Sie können die Methoden „find“ und „find_all“ verwenden, um das HTML-Skript mit Name, Rang und Jahr jedes Films in einer Listenvariablen zu speichern.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
Schritt 5: Durchlaufen Sie die Liste der Filme, die in der Variablen „top_movies“ gespeichert sind, und extrahieren Sie mithilfe des folgenden Codes den Namen, den Rang und das Jahr jedes Films im Textformat aus seinem HTML-Skript.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
Im Ausgabe-Screenshot sehen Sie die Liste der Filme mit Name, Rang und Erscheinungsjahr.
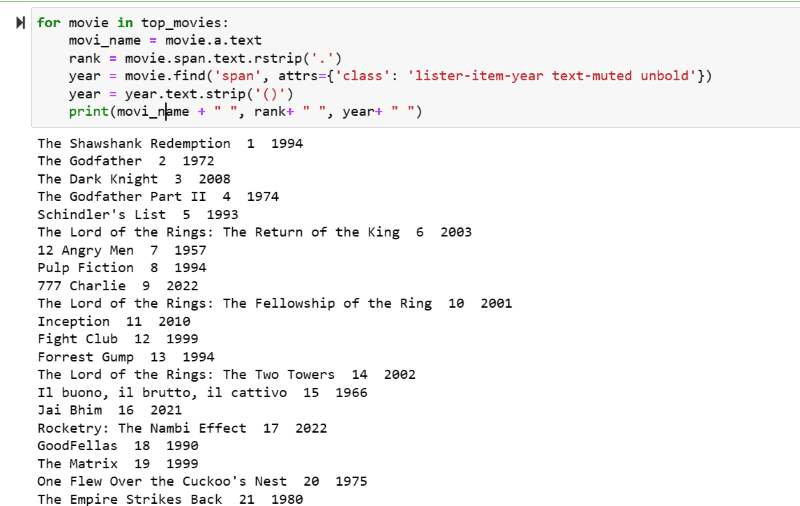
Sie können die gedruckten Daten mühelos mit etwas Python-Code in eine Excel-Tabelle verschieben und für Ihre Analyse verwenden.
Letzte Worte
Dieser Beitrag führt Sie durch die Installation von Beautiful Soup for Web Scraping. Auch die von mir gezeigten Scraping-Beispiele sollen Ihnen den Einstieg in Beautiful Soup erleichtern.
Da Sie daran interessiert sind, wie man Beautiful Soup für Web Scraping installiert, empfehle ich Ihnen dringend, sich diese verständliche Anleitung anzusehen, um mehr über Web Scraping mit Python zu erfahren.