
Die Kontrolle und Verwaltung von Daten kann eine anstrengende Aufgabe sein. Diese AWS S3-Befehle helfen Ihnen, Ihre AWS S3-Buckets und -Daten schnell und effizient zu verwalten.
AWS-S3 ist der von AWS bereitgestellte Objektspeicherdienst. Es ist der am weitesten verbreitete Speicherdienst von AWS, der praktisch unendlich viele Daten speichern kann. Es ist hochverfügbar, langlebig und einfach in mehrere andere AWS-Services zu integrieren.
AWS S3 kann von Personen mit allen Anforderungen verwendet werden, wie z. B. Speicherung von mobilen/Webanwendungen, Big Data-Speicherung, Datenspeicherung für maschinelles Lernen, Hosting statischer Websites und vielem mehr.
Wenn Sie S3 in Ihrem Projekt verwendet haben, wissen Sie, dass angesichts der enormen Menge an Speicherkapazität die Verwaltung von Hunderten von Buckets und Terabytes an Daten in diesen Buckets eine anspruchsvolle Aufgabe sein kann. Wir haben eine Liste von AWS S3-Befehlen mit Beispielen, die Sie verwenden können, um Ihre AWS S3-Buckets und -Daten effizient zu verwalten.
Inhaltsverzeichnis
AWS CLI-Setup
Nachdem Sie die AWS CLI erfolgreich heruntergeladen und installiert haben, müssen Sie die AWS-Anmeldeinformationen konfigurieren, um auf Ihr AWS-Konto und Ihre Services zugreifen zu können. Lassen Sie uns kurz durchgehen, wie Sie AWS CLI konfigurieren können.
Der erste Schritt besteht darin, einen Benutzer mit programmgesteuertem Zugriff auf das AWS-Konto zu erstellen. Denken Sie daran, dieses Kontrollkästchen zu aktivieren, wenn Sie einen Benutzer für AWS CLI erstellen.
Geben Sie die Berechtigungen und erstellen Sie einen Benutzer. Kopieren Sie auf dem letzten Bildschirm, nachdem Sie diesen Benutzer erfolgreich erstellt haben, die Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel für diesen Benutzer. Wir verwenden diese Anmeldeinformationen, um uns über die AWS CLI anzumelden.
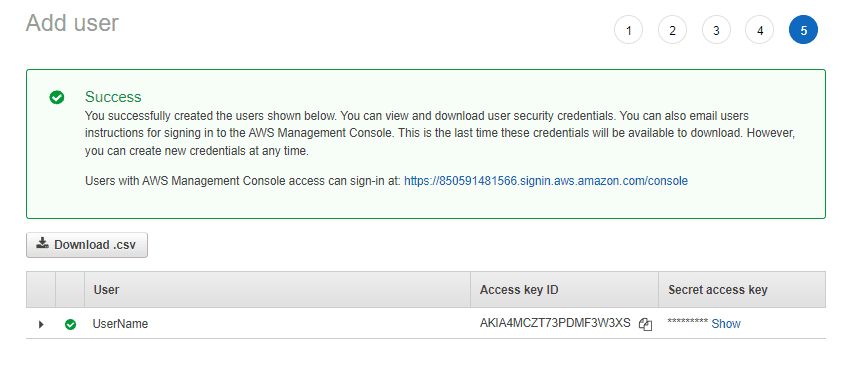
Gehen Sie nun zum Terminal Ihrer Wahl und führen Sie den folgenden Befehl aus.
aws configure
Geben Sie die Zugriffsschlüssel-ID und den geheimen Zugriffsschlüssel ein, wenn Sie dazu aufgefordert werden. Wählen Sie eine beliebige AWS-Region Ihrer Wahl und das Befehlsausgabeformat aus. Ich persönlich bevorzuge das JSON-Format. Dies ist keine große Sache, Sie können diese Werte später jederzeit ändern.

Sie können jetzt jeden AWS CLI-Befehl in der Konsole ausführen. Lassen Sie uns nun die AWS S3-Befehle durchgehen.
vgl
Der cp-Befehl kopiert einfach die Daten in und aus S3-Buckets. Es kann verwendet werden, um Dateien von lokal nach S3, von S3 nach lokal und zwischen zwei S3-Buckets zu kopieren. Es gibt viele andere Parameter, die Sie mit den Befehlen angeben können.
Beispielsweise der Parameter -dryrun zum Testen des Befehls, der Parameter –storage-class zum Angeben der Speicherklasse Ihrer Daten in S3, andere Parameter zum Festlegen der Verschlüsselung und vieles mehr. Das cp-Befehl gibt Ihnen die vollständige Kontrolle darüber, wie Sie Ihre Datensicherheit in S3 konfigurieren.
Verwendungszweck
aws s3 cp <SOURCE> <DESTINATION> [--options]
Beispiele
Kopieren Sie Daten von lokal nach S3
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt
Daten von S3 auf lokal kopieren
aws s3 cp s3://bucket_name/file_name_2.txt file_name.txt
Kopieren Sie Daten zwischen S3-Buckets
aws s3 cp s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
Kopieren Sie Daten von lokal nach S3 – IA
aws s3 cp file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
Kopieren Sie alle Daten aus einem lokalen Ordner nach S3
aws s3 cp ./local_folder s3://bucket_name --recursive
ls
Das ls-Befehl wird verwendet, um die Buckets oder den Inhalt der Buckets aufzulisten. Wenn Sie also einfach nur Informationen zu Ihren Buckets oder den Daten in diesen Buckets anzeigen möchten, können Sie den Befehl ls verwenden.
Verwendungszweck:
aws s3 ls NONE or <BUCKET_NAME> [--options]
Beispiele
Alle Buckets im Konto auflisten
aws s3 ls Output: 2022-02-02 18:20:14 BUCKET_NAME_1 2022-03-20 13:12:43 BUCKET_NAME_2 2022-03-29 10:52:33 BUCKET_NAME_3
Dieser Befehl listet alle Buckets in Ihrem Konto mit dem Bucket-Erstellungsdatum auf.
Alle Objekte der obersten Ebene in einem Bucket auflisten
aws s3 ls BUCKET_NAME_1 or s3://BUCKET_NAME_1
Output:
PRE samplePrefix/
2021-12-09 12:23:20 8754 file_1.png
2021-12-09 12:23:21 1290 file_2.json
2021-12-09 12:23:21 3088 file_3.html
Dieser Befehl listet alle Objekte der obersten Ebene in einem S3-Bucket auf. Beachten Sie hier, dass die Objekte mit dem Präfix samplePrefix/ hier nicht angezeigt werden, sondern nur die Objekte der obersten Ebene.
Alle Objekte in einem Bucket auflisten
aws s3 ls BUCKET_NAME_1 or s3://BUCKET_NAME_1 --recursive Output: 2021-12-09 12:23:20 8754 file_1.png 2021-12-09 12:23:21 1290 file_2.json 2021-12-09 12:23:21 3088 file_3.html 2021-12-09 12:23:20 16328 samplePrefix/file_1.txt 2021-12-09 12:23:20 29325 samplePrefix/sampleSubPrefix/file_1.css
Dieser Befehl listet alle Objekte in einem S3-Bucket auf. Beachten Sie hier, dass die Objekte mit dem Präfix samplePrefix/ und allen Unterpräfixen ebenfalls angezeigt werden.
mb
Das mb-Befehl wird einfach verwendet, um neue S3-Buckets zu erstellen. Dies ist ein ziemlich einfacher Befehl, aber um neue Buckets zu erstellen, sollte der Name des neuen Buckets für alle S3-Buckets eindeutig sein.
Verwendungszweck
aws s3 mb <BUCKET_NAME>
Beispiel
Erstellen Sie einen neuen Bucket in einer bestimmten Region
aws s3 mb myUniqueBucketName --region eu-west-1
mv
Das mv-Befehl verschiebt die Daten einfach in und aus S3-Buckets. Genau wie der Befehl cp wird der Befehl mv verwendet, um Daten von lokal nach S3, von S3 nach lokal oder zwischen zwei S3-Buckets zu verschieben.
Der einzige Unterschied zwischen dem mv- und dem cp-Befehl besteht darin, dass bei Verwendung des mv-Befehls die Datei aus der Quelle gelöscht wird. AWS verschiebt diese Datei an das Ziel. Es gibt viele Optionen, die Sie mit dem Befehl angeben können.
Verwendungszweck
aws s3 mv <SOURCE> <DESTINATION> [--options]
Beispiele
Verschieben Sie Daten von lokal nach S3
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt
Verschieben Sie Daten von S3 auf lokal
aws s3 mv s3://bucket_name/file_name_2.txt file_name.txt
Verschieben Sie Daten zwischen S3-Buckets
aws s3 mv s3://bucket_name/file_name.txt s3://bucket_name_2/file_name_2.txt
Verschieben Sie Daten von lokal nach S3 – IA
aws s3 mv file_name.txt s3://bucket_name/file_name_2.txt --storage-class STANDARD_IA
Verschieben Sie alle Daten von einem Präfix in S3 in einen lokalen Ordner.
aws s3 mv s3://bucket_name/somePrefix ./localFolder --recursive
vormerken
Der Presign-Befehl generiert eine vorsignierte URL für einen Schlüssel im S3-Bucket. Sie können diesen Befehl verwenden, um URLs zu generieren, die von anderen verwendet werden können, um auf eine Datei im angegebenen S3-Bucket-Schlüssel zuzugreifen.
Verwendungszweck
aws s3 presign
Beispiel
Generieren Sie für ein Objekt im Bucket eine vorsignierte URL, die 1 Stunde lang gültig ist.
aws s3 presign s3://bucket_name/samplePrefix/file_name.png --expires-in 3600 Output: https://s3.ap-south-1.amazonaws.com/bucket_name/samplePrefix/file_name.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKIA4MCZT73PAX7ZMVFW%2F20220314%2Fap-south-1%2Fs3%2Faws4_request&X-Amz-Date=20220314T054113Z&X-Amz-Expires=3600&X-Amz-SignedHeaders=host&X-Amz-Signature=f14608bbf3e1f9f8d215eb5b439b87e167b1055bcd7a45c13a33debd3db1be96
rb
Der rb-Befehl wird einfach verwendet, um S3-Buckets zu löschen.
Verwendungszweck
aws rb <BUCKET_NAME>
Beispiel
Löschen Sie einen S3-Bucket.
aws s3 mb myBucketName # This command fails if there is any data in this bucket.
Löschen Sie einen S3-Bucket zusammen mit den Daten im S3-Bucket.
aws s3 mb myBucketName --force
rm
Der Befehl rm wird einfach verwendet, um die Objekte in S3-Buckets zu löschen.
Verwendungszweck
aws s3 rm <S3Uri_To_The_File>
Beispiele
Löschen Sie eine Datei aus dem S3-Bucket.
aws s3 rm s3://bucket_name/sample_prefix/file_name_2.txt
Löschen Sie alle Dateien mit einem bestimmten Präfix in einem S3-Bucket.
aws s3 rm s3://bucket_name/sample_prefix --recursive
Löschen Sie alle Dateien in einem S3-Bucket.
aws s3 rm s3://bucket_name --recursive
synchronisieren
Der sync-Befehl kopiert und aktualisiert Dateien von der Quelle zum Ziel, genau wie der cp-Befehl. Es ist wichtig, dass wir den Unterschied zwischen dem cp- und dem sync-Befehl verstehen. Wenn Sie cp verwenden, werden Daten von der Quelle zum Ziel kopiert, selbst wenn die Daten bereits am Ziel vorhanden sind.
Es werden auch keine Dateien vom Ziel gelöscht, wenn sie von der Quelle gelöscht werden. Die Synchronisierung sieht sich jedoch das Ziel an, bevor Sie Ihre Daten kopieren, und kopiert nur die neuen und aktualisierten Dateien. Das Sync-Befehl ähnelt dem Festschreiben und Übertragen von Änderungen an einen Remote-Zweig in Git. Der Sync-Befehl bietet viele Optionen, um den Befehl anzupassen.
Verwendungszweck
aws s3 sync <SOURCE> <DESTINATION> [--options]
Beispiele
Lokalen Ordner mit S3 synchronisieren
aws s3 sync ./local_folder s3://bucket_name
Synchronisieren Sie S3-Daten mit einem lokalen Ordner
aws s3 sync s3://bucket_name ./local_folder
Daten zwischen zwei S3-Buckets synchronisieren
aws s3 sync s3://bucket_name s3://bucket_name_2
Verschieben Sie Daten zwischen zwei S3-Buckets mit Ausnahme aller .txt-Dateien
aws s3 sync s3://bucket_name s3://bucket_name_2 --exclude "*.txt
Webseite
Sie können S3-Buckets verwenden, um statische Websites zu hosten. Der website-Befehl wird verwendet, um das statische S3-Website-Hosting für Ihren Bucket zu konfigurieren.
Sie geben den Index und die Fehlerdateien an und der S3 gibt Ihnen eine URL, wo Sie die Datei anzeigen können.
Verwendungszweck
aws s3 website <S3_URI> [--options]
Beispiel:
Konfigurieren Sie das statische Hosting für einen S3-Bucket und geben Sie die Index- und Fehlerdateien an
aws s3 website s3://bucket_name --index-document index.html --error-document error.html
Fazit
Ich hoffe, das Obige gibt Ihnen eine Vorstellung von einigen der häufig verwendeten AWS S3-Befehle zum Verwalten von Buckets. Wenn Sie mehr erfahren möchten, können Sie sich die AWS-Zertifizierungsdetails ansehen.