

Video-Deepfakes bedeuten, dass Sie nicht allem vertrauen können, was Sie sehen. Nun können Audio-Deepfakes bedeuten, dass Sie Ihren Ohren nicht mehr trauen können. War das wirklich der Präsident, der Kanada den Krieg erklärte? Fragt wirklich Ihr Vater am Telefon nach seinem E-Mail-Passwort?
Fügen Sie der Liste, wie unsere eigene Hybris uns unweigerlich zerstören könnte, eine weitere existenzielle Sorge hinzu. Während der Reagan-Ära waren die einzigen wirklichen technologischen Risiken die Bedrohung durch nukleare, chemische und biologische Kriegsführung.
In den folgenden Jahren hatten wir die Gelegenheit, uns über die graue Masse der Nanotechnologie und die globalen Pandemien zu besinnen. Jetzt haben wir Deepfakes – Leute, die die Kontrolle über ihr Abbild oder ihre Stimme verlieren.
Inhaltsverzeichnis
Was ist ein Audio-Deepfake?
Die meisten von uns haben ein Video-Deepfake gesehen, in dem Deep-Learning-Algorithmen verwendet werden, um eine Person durch das Abbild einer anderen Person zu ersetzen. Die besten sind erschreckend realistisch, und jetzt ist Audio an der Reihe. Ein Audio-Deepfake liegt vor, wenn eine „geklonte“ Stimme, die potenziell nicht von der echten Person zu unterscheiden ist, verwendet wird, um synthetisches Audio zu erzeugen.
„Es ist wie Photoshop für die Stimme“, sagte Zohaib Ahmed, CEO von Ähneln KI, über die Voice-Cloning-Technologie seines Unternehmens.
Schlechte Photoshop-Jobs lassen sich jedoch leicht entlarven. Eine Sicherheitsfirma, mit der wir gesprochen haben, sagte, dass die Leute normalerweise nur mit einer Genauigkeit von 57 Prozent raten, ob ein Audio-Deepfake echt oder gefälscht ist – nicht besser als ein Münzwurf.
Da so viele Sprachaufnahmen von Telefongesprächen mit geringer Qualität sind (oder an lauten Orten aufgenommen wurden), können Audio-Deepfakes noch ununterscheidbarer gemacht werden. Je schlechter die Klangqualität, desto schwieriger ist es, diese verräterischen Anzeichen dafür zu erkennen, dass eine Stimme nicht echt ist.
Aber wozu braucht man überhaupt ein Photoshop für Stimmen?
Das überzeugende Argument für synthetisches Audio
Tatsächlich besteht eine enorme Nachfrage nach synthetischem Audio. Laut Ahmed „ist der ROI sehr unmittelbar.“
Dies gilt insbesondere, wenn es um Spiele geht. In der Vergangenheit war Sprache die einzige Komponente in einem Spiel, die nicht auf Abruf erstellt werden konnte. Selbst in interaktiven Titeln mit in Echtzeit gerenderten Szenen in Kinoqualität sind verbale Interaktionen mit nicht spielenden Charakteren immer im Wesentlichen statisch.
Inzwischen hat die Technik jedoch aufgeholt. Studios haben das Potenzial, die Stimme eines Schauspielers zu klonen und Text-to-Speech-Engines zu verwenden, damit Charaktere alles in Echtzeit sagen können.
Es gibt auch traditionellere Anwendungen in der Werbung sowie im technischen und Kundensupport. Hier kommt es auf eine authentisch menschlich klingende Stimme an, die ohne menschliches Zutun persönlich und kontextuell antwortet.
Auch Unternehmen für das Klonen von Stimmen sind von medizinischen Anwendungen begeistert. Natürlich ist Stimmersatz in der Medizin nichts Neues – Stephen Hawking verwendete bekanntlich eine robotergesteuerte synthetisierte Stimme, nachdem er 1985 seine eigene verloren hatte. Das moderne Klonen von Stimmen verspricht jedoch noch etwas Besseres.
Im Jahr 2008, Synthetic Voice Company, CereProcEr gab dem verstorbenen Filmkritiker Roger Ebert seine Stimme zurück, nachdem der Krebs sie weggenommen hatte. CereProc hatte eine Webseite veröffentlicht, auf der die Leute Nachrichten eingeben konnten, die dann mit der Stimme des ehemaligen Präsidenten George Bush gesprochen wurden.
„Ebert sah das und dachte: ‚Nun, wenn sie Bushs Stimme kopieren könnten, sollten sie auch meine kopieren können’“, sagte Matthew Aylett, Chief Scientific Officer von CereProc. Ebert bat dann das Unternehmen, eine Ersatzstimme zu erstellen, was sie durch die Verarbeitung einer großen Bibliothek von Sprachaufnahmen taten.
„Es war eines der ersten Mal, dass jemand so etwas getan hat, und es war ein echter Erfolg“, sagte Aylett.
In den letzten Jahren haben eine Reihe von Unternehmen (einschließlich CereProc) mit dem ALS-Vereinigung an Projektabrechnung Menschen, die an ALS leiden, mit synthetischen Stimmen zu versorgen.

So funktioniert synthetisches Audio
Das Klonen von Stimmen hat gerade einen Moment, und eine Reihe von Unternehmen entwickeln Tools. Ähneln KI und Beschreiben haben Online-Demos, die jeder kostenlos ausprobieren kann. Sie nehmen einfach die Sätze auf, die auf dem Bildschirm erscheinen, und in wenigen Minuten wird ein Modell Ihrer Stimme erstellt.
Sie können der KI – insbesondere Deep-Learning-Algorithmen – dafür danken, dass sie aufgezeichnete Sprache mit Text abgleichen können, um die Komponentenphoneme zu verstehen, aus denen Ihre Stimme besteht. Es verwendet dann die resultierenden linguistischen Bausteine, um Wörter anzunähern, von denen es Sie nicht gehört hat.
Die Basistechnologie gibt es schon seit einiger Zeit, aber wie Aylett betonte, brauchte sie etwas Hilfe.
„Stimme zu kopieren war ein bisschen wie Gebäck zu backen“, sagte er. „Es war ziemlich schwierig und es gab verschiedene Möglichkeiten, es von Hand zu optimieren, damit es funktioniert.“
Entwickler benötigten enorme Mengen an aufgezeichneten Sprachdaten, um passable Ergebnisse zu erzielen. Dann öffneten sich vor einigen Jahren die Schleusen. Als kritisch erwies sich die Forschung im Bereich Computer Vision. Wissenschaftler entwickelten Generative Adversarial Networks (GANs), die erstmals Extrapolationen und Vorhersagen auf der Grundlage vorhandener Daten machen konnten.
„Anstatt dass ein Computer ein Bild von einem Pferd sieht und sagt ‚Das ist ein Pferd‘, könnte mein Modell jetzt ein Pferd in ein Zebra verwandeln“, sagte Aylett. „Die Explosion der Sprachsynthese ist jetzt also der akademischen Arbeit von Computer Vision zu verdanken.“
Eine der größten Innovationen beim Klonen von Stimmen war die allgemeine Reduzierung der Menge an Rohdaten, die zum Erstellen einer Stimme benötigt werden. In der Vergangenheit benötigten Systeme Dutzende oder sogar Hunderte von Stunden Audio. Jetzt können jedoch aus nur wenigen Minuten Inhalt kompetente Stimmen generiert werden.
Die existenzielle Angst, irgendetwas nicht zu vertrauen
Diese Technologie ist zusammen mit Atomkraft, Nanotechnologie, 3D-Druck und CRISPR gleichzeitig aufregend und erschreckend. Immerhin gab es in den Nachrichten bereits Fälle, in denen Menschen von Stimmklonen getäuscht wurden. Im Jahr 2019 behauptete ein Unternehmen in Großbritannien, es sei von einem Audio-Deepfake ausgetrickst Telefonanruf, um Geld an Kriminelle zu überweisen.
Sie müssen auch nicht weit gehen, um überraschend überzeugende Audio-Fakes zu finden. Youtube Kanal Stimmsynthese zeigt bekannte Leute, die Dinge sagen, die sie nie gesagt haben, wie zum Beispiel George W. Bush liest „In Da Club“ von 50 Cent. Es ist genau richtig.
An anderer Stelle auf YouTube kann man eine Schar von Ex-Präsidenten hören, darunter Obama, Clinton und Reagan rappen NWA. Die Musik und die Hintergrundgeräusche helfen, einige der offensichtlichen Roboterfehler zu verbergen, aber selbst in diesem unvollkommenen Zustand ist das Potenzial offensichtlich.
Wir experimentierten mit den Tools auf Ähneln KI und Beschreiben und erstellte Sprachklon. Descript verwendet eine Voice-Cloning-Engine, die ursprünglich Lyrebird hieß und besonders beeindruckend war. Wir waren schockiert über die Qualität. Ihre eigene Stimme Dinge sagen zu hören, von denen Sie wissen, dass Sie sie nie gesagt haben, ist beunruhigend.
Die Rede hat definitiv eine roboterhafte Qualität, aber bei einem gelegentlichen Hören haben die meisten Leute keinen Grund zu der Annahme, dass es sich um eine Fälschung handelt.
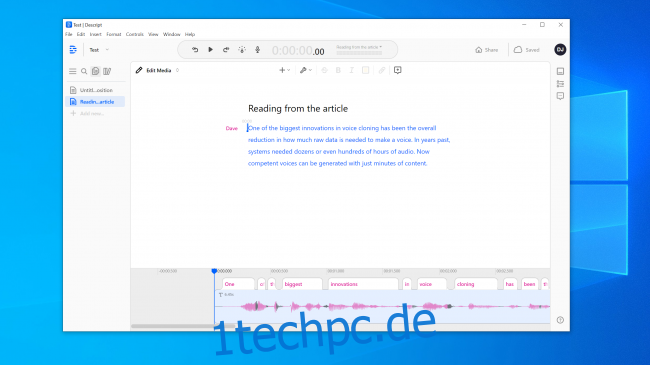
Wir hatten noch größere Hoffnungen für die KI von Resemble. Es gibt Ihnen die Werkzeuge, um ein Gespräch mit mehreren Stimmen zu erstellen und die Ausdruckskraft, Emotion und das Tempo des Dialogs zu variieren. Wir waren jedoch der Meinung, dass das Sprachmodell nicht die wesentlichen Qualitäten der von uns verwendeten Stimme erfasst. Tatsächlich war es unwahrscheinlich, dass es jemanden täuschen würde.
Ein Vertreter von Resemble AI sagte uns: „Die meisten Leute sind überwältigt von den Ergebnissen, wenn sie es richtig machen.“ Wir haben zweimal ein Sprachmodell mit ähnlichen Ergebnissen erstellt. Es ist also offensichtlich nicht immer einfach, einen Sprachklon zu erstellen, mit dem Sie einen digitalen Raubüberfall durchführen können.
Trotzdem glaubt Kundan Kumar, der Gründer von Lyrebird (der jetzt Teil von Descript ist), dass wir diese Schwelle bereits überschritten haben.
„Für einen kleinen Prozentsatz der Fälle ist es bereits da“, sagte Kumar. „Wenn ich synthetisches Audio verwende, um ein paar Wörter in einer Rede zu ändern, ist es bereits so gut, dass Sie schwer erkennen können, was sich geändert hat.“
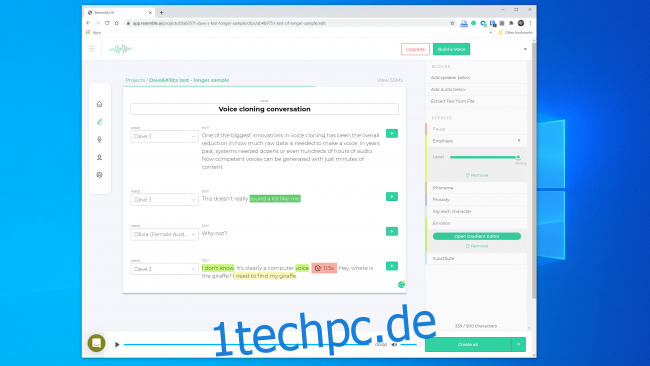
Wir können auch davon ausgehen, dass diese Technologie mit der Zeit nur besser wird. Systeme benötigen weniger Audio, um ein Modell zu erstellen, und schnellere Prozessoren können das Modell in Echtzeit erstellen. Intelligentere KI wird lernen, wie man eine überzeugendere menschenähnliche Kadenz und Betonung der Sprache hinzufügt, ohne ein Beispiel zu haben, an dem man arbeiten kann.
Was bedeutet, dass wir uns der weit verbreiteten Verfügbarkeit des mühelosen Klonens von Stimmen möglicherweise nähern.
Die Ethik der Büchse der Pandora
Die meisten Unternehmen, die in diesem Bereich tätig sind, scheinen bereit zu sein, mit der Technologie auf sichere und verantwortungsvolle Weise umzugehen. Ähneln KI zum Beispiel hat einen ganzen Abschnitt „Ethik“ auf seiner Website, und der folgende Auszug ist ermutigend:
„Wir arbeiten mit Unternehmen in einem strengen Prozess zusammen, um sicherzustellen, dass die Stimme, die sie klonen, von ihnen verwendet werden kann und dass die Synchronsprecher die entsprechenden Zustimmungen haben.“
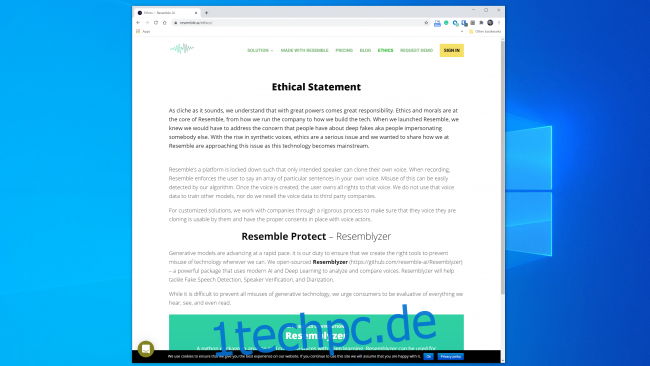
Ebenso sagte Kumar, dass Lyrebird von Anfang an über Missbrauch besorgt war. Deshalb erlaubt es jetzt als Teil von Descript den Leuten nur, ihre eigene Stimme zu klonen. Tatsächlich erfordern sowohl Resemble als auch Descript, dass die Leute ihre Samples live aufzeichnen, um nicht einvernehmliches Klonen von Stimmen zu verhindern.
Es ist ermutigend, dass die großen kommerziellen Akteure einige ethische Richtlinien auferlegt haben. Es ist jedoch wichtig, sich daran zu erinnern, dass diese Unternehmen keine Gatekeeper dieser Technologie sind. Es gibt bereits eine Reihe von Open-Source-Tools, für die es keine Regeln gibt. Laut Henry Ajder, Head of Threat Intelligence bei Tiefenverfolgung, Sie benötigen auch keine fortgeschrittenen Programmierkenntnisse, um es zu missbrauchen.
„Ein Großteil der Fortschritte in diesem Bereich ist durch gemeinschaftliche Arbeit an Orten wie GitHub zustande gekommen, bei der Open-Source-Implementierungen zuvor veröffentlichter wissenschaftlicher Arbeiten verwendet wurden“, sagte Ajder. „Es kann von jedem verwendet werden, der über mäßige Kenntnisse im Programmieren verfügt.“
Sicherheitsprofis haben das alles schon einmal gesehen
Kriminelle haben versucht, Geld per Telefon zu stehlen, lange bevor das Klonen von Stimmen möglich war, und Sicherheitsexperten waren immer in Bereitschaft, um dies zu erkennen und zu verhindern. Sicherheitsfirma Stecknadel fallen versucht, Bankbetrug zu stoppen, indem er überprüft, ob ein Anrufer der ist, für den er sich ausgibt. Allein im Jahr 2019 behauptet Pindrop, 1,2 Milliarden Sprachinteraktionen analysiert und Betrugsversuche im Wert von etwa 470 Millionen US-Dollar verhindert zu haben.
Vor dem Klonen von Stimmen haben Betrüger eine Reihe anderer Techniken ausprobiert. Am einfachsten war es, einfach von woanders mit persönlichen Informationen über die Marke anzurufen.
„Unsere akustische Signatur ermöglicht es uns, aufgrund der Klangeigenschaften festzustellen, dass ein Anruf tatsächlich von einem Skype-Telefon in Nigeria kommt“, sagte Vijay Balasubramaniyan, CEO von Pindrop. „Dann können wir vergleichen, dass der Kunde ein AT&T-Telefon in Atlanta verwendet.“
Einige Kriminelle haben auch Karriere gemacht, indem sie Hintergrundgeräusche verwenden, um Bankmitarbeiter abzuschrecken.
„Es gibt einen Betrüger namens Chicken Man, der immer Hähne im Hintergrund laufen ließ“, sagte Balasubramaniyan. „Und es gibt eine Dame, die im Hintergrund ein weinendes Baby benutzte, um die Callcenter-Agenten im Wesentlichen davon zu überzeugen, dass ‚Hey, ich mache eine schwere Zeit‘ durch, um Mitgefühl zu bekommen.“
Und dann sind da noch die männlichen Kriminellen, die hinter den Bankkonten von Frauen her sind.
„Sie verwenden Technologie, um die Frequenz ihrer Stimme zu erhöhen, um weiblicher zu klingen“, erklärte Balasubramaniyan. Diese können erfolgreich sein, aber „gelegentlich vermasselt die Software und sie klingen wie Alvin und die Chipmunks.“
Natürlich ist das Klonen von Stimmen nur die neueste Entwicklung in diesem ständig eskalierenden Krieg. Sicherheitsfirmen haben bereits Betrüger mit synthetischem Audio bei mindestens einem Spearfishing-Angriff erwischt.
„Mit dem richtigen Ziel kann die Auszahlung massiv sein“, sagte Balasubramaniyan. „Es ist also sinnvoll, die Zeit zu investieren, um eine synthetisierte Stimme der richtigen Person zu erstellen.“
Kann jemand sagen, ob eine Stimme gefälscht ist?

Wenn es darum geht zu erkennen, ob eine Stimme gefälscht wurde, gibt es sowohl gute als auch schlechte Nachrichten. Das Schlimme ist, dass Sprachklone jeden Tag besser werden. Deep-Learning-Systeme werden immer intelligenter und erzeugen authentischere Stimmen, deren Erstellung weniger Audio erfordert.
Wie Sie in diesem Clip von sehen können Präsident Obama fordert MC Ren auf, Stellung zu beziehen, sind wir auch schon an dem Punkt angelangt, an dem ein klangtreues, sorgfältig konstruiertes Stimmmodell für das menschliche Ohr ziemlich überzeugend klingen kann.
Je länger ein Soundclip ist, desto wahrscheinlicher ist es, dass Sie feststellen, dass etwas nicht stimmt. Bei kürzeren Clips werden Sie jedoch möglicherweise nicht bemerken, dass es synthetisch ist – insbesondere, wenn Sie keinen Grund haben, seine Legitimität in Frage zu stellen.
Je klarer die Klangqualität, desto leichter sind Anzeichen für einen Audio-Deepfake zu erkennen. Wenn jemand direkt in ein Mikrofon in Studioqualität spricht, können Sie genau zuhören. Aber eine schlechte Telefongesprächsaufzeichnung oder ein Gespräch, das auf einem Handheld-Gerät in einem lauten Parkhaus aufgezeichnet wurde, ist viel schwieriger zu bewerten.
Die gute Nachricht ist, dass Computer nicht die gleichen Einschränkungen haben, auch wenn Menschen Schwierigkeiten haben, echtes von Fälschungen zu unterscheiden. Glücklicherweise gibt es bereits Tools zur Sprachüberprüfung. Pindrop hat eines, das Deep-Learning-Systeme gegeneinander ausspielt. Es verwendet beides, um herauszufinden, ob ein Audiosample die Person ist, die es sein soll. Es wird jedoch auch untersucht, ob ein Mensch überhaupt alle Geräusche im Sample erzeugen kann.
Je nach Audioqualität enthält jede Sprachsekunde zwischen 8.000 und 50.000 Datensamples, die analysiert werden können.
„Die Dinge, nach denen wir normalerweise suchen, sind Einschränkungen der Sprache aufgrund der menschlichen Evolution“, erklärte Balasubramanyan.
Beispielsweise haben zwei Stimmklänge einen minimal möglichen Abstand voneinander. Dies liegt daran, dass es physikalisch nicht möglich ist, sie aufgrund der Geschwindigkeit, mit der sich die Muskeln in Ihrem Mund und Ihre Stimmbänder neu konfigurieren können, schneller auszusprechen.
„Wenn wir uns synthetisiertes Audio ansehen“, sagte Balasubramaniyan, „sehen wir manchmal Dinge und sagen: ‚Dies hätte niemals von einem Menschen erzeugt werden können, weil die einzige Person, die dies hätte erzeugen können, einen zwei Meter langen Hals haben muss. ”
Es gibt auch eine Klangklasse, die „Frikative“ genannt wird. Sie werden gebildet, wenn Luft durch eine enge Verengung in Ihrem Hals strömt, wenn Sie Buchstaben wie f, s, v und z aussprechen. Frikative sind für Deep-Learning-Systeme besonders schwer zu beherrschen, da die Software Schwierigkeiten hat, sie von Rauschen zu unterscheiden.
Also, zumindest im Moment, stolpert die Software zum Klonen von Stimmen über die Tatsache, dass Menschen Fleischsäcke sind, die Luft durch Löcher in ihrem Körper strömen lassen