
In diesem Artikel werden einige der besten Python-Bibliotheken für Datenwissenschaftler und das Team für maschinelles Lernen erwähnt und erläutert.
Python ist eine ideale Sprache, die in diesen beiden Bereichen hauptsächlich für die angebotenen Bibliotheken verwendet wird.
Dies liegt an den Anwendungen der Python-Bibliotheken wie Dateneingabe/-ausgabe I/O und Datenanalyse sowie an anderen Datenbearbeitungsvorgängen, die Data Scientists und Experten für maschinelles Lernen verwenden, um Daten zu verarbeiten und zu untersuchen.
Inhaltsverzeichnis
Python-Bibliotheken, was ist das?
Eine Python-Bibliothek ist eine umfangreiche Sammlung integrierter Module, die vorkompilierten Code enthalten, einschließlich Klassen und Methoden, sodass der Entwickler keinen Code von Grund auf neu implementieren muss.
Bedeutung von Python in Data Science und maschinellem Lernen
Python verfügt über die besten Bibliotheken zur Verwendung durch Experten für maschinelles Lernen und Data Science.
Seine Syntax ist einfach, wodurch es effizient ist, komplexe maschinelle Lernalgorithmen zu implementieren. Darüber hinaus verkürzt die einfache Syntax die Lernkurve und erleichtert das Verständnis.
Python unterstützt auch die schnelle Entwicklung von Prototypen und das reibungslose Testen von Anwendungen.
Die große Python-Community ist praktisch für Data Scientists, um bei Bedarf schnell nach Lösungen für ihre Fragen zu suchen.
Wie nützlich sind Python-Bibliotheken?
Python-Bibliotheken sind maßgeblich an der Erstellung von Anwendungen und Modellen für maschinelles Lernen und Data Science beteiligt.
Diese Bibliotheken tragen wesentlich dazu bei, den Entwickler bei der Wiederverwendbarkeit von Code zu unterstützen. Daher können Sie eine relevante Bibliothek importieren, die eine bestimmte Funktion in Ihrem Programm implementiert, außer das Rad neu zu erfinden.
Python-Bibliotheken, die im maschinellen Lernen und in der Datenwissenschaft verwendet werden
Data-Science-Experten empfehlen verschiedene Python-Bibliotheken, mit denen Data-Science-Enthusiasten vertraut sein müssen. Abhängig von ihrer Relevanz in der Anwendung wenden die Experten für maschinelles Lernen und Data Science verschiedene Python-Bibliotheken an, die in Bibliotheken kategorisiert sind, um Modelle bereitzustellen, Daten zu extrahieren und zu kratzen, Daten zu verarbeiten und Daten zu visualisieren.
Dieser Artikel identifiziert einige häufig verwendete Python-Bibliotheken in Data Science und maschinellem Lernen.
Schauen wir sie uns jetzt an.
Nüppig
Die Numpy-Python-Bibliothek, vollständig auch numerischer Python-Code, wurde mit gut optimiertem C-Code erstellt. Datenwissenschaftler bevorzugen es wegen seiner tiefgreifenden mathematischen Berechnungen und wissenschaftlichen Berechnungen.
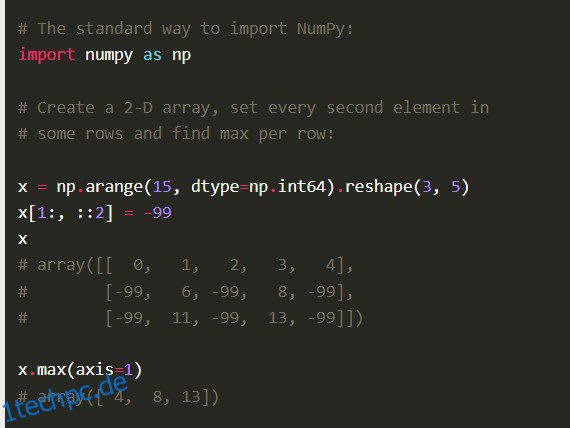
Merkmale
Numpy verfügt über weitere umfassende Funktionen wie die Vektorisierung mathematischer Operationen, Indizierung und Schlüsselkonzepte bei der Implementierung von Arrays und Matrizen.
Pandas
Pandas ist eine berühmte Bibliothek für maschinelles Lernen, die hochrangige Datenstrukturen und zahlreiche Tools bereitstellt, um riesige Datensätze mühelos und effektiv zu analysieren. Mit sehr wenigen Befehlen kann diese Bibliothek komplexe Operationen mit Daten übersetzen.
Zahlreiche eingebaute Methoden, die Daten gruppieren, indizieren, abrufen, aufteilen, umstrukturieren und Sätze filtern können, bevor sie in ein- und mehrdimensionale Tabellen eingefügt werden; bildet diese Bibliothek.
Die Hauptfunktionen der Pandas-Bibliothek
Es ist hocheffizient für seine gute Datenanalysefunktionalität und hohe Flexibilität.
Matplotlib
Die grafische Python-Bibliothek Matplotlib 2D kann Daten aus zahlreichen Quellen problemlos verarbeiten. Die erstellten Visualisierungen sind statisch, animiert und interaktiv, in die der Benutzer hineinzoomen kann, wodurch sie für Visualisierungen und das Erstellen von Diagrammen effizient sind. Es ermöglicht auch die Anpassung des Layouts und des visuellen Stils.
Seine Dokumentation ist Open Source und bietet eine umfassende Sammlung von Werkzeugen, die für die Implementierung erforderlich sind.
Matplotlib importiert Hilfsklassen, um Jahr, Monat, Tag und Woche zu implementieren, wodurch Zeitreihendaten effizient bearbeitet werden können.
Scikit-lernen
Wenn Sie eine Bibliothek in Betracht ziehen, die Ihnen bei der Arbeit mit komplexen Daten hilft, sollte Scikit-learn Ihre ideale Bibliothek sein. Experten für maschinelles Lernen verwenden Scikit-learn in großem Umfang. Die Bibliothek ist mit anderen Bibliotheken wie NumPy, SciPy und matplotlib verknüpft. Es bietet sowohl überwachte als auch unüberwachte Lernalgorithmen, die für Produktionsanwendungen verwendet werden können.

Funktionen der Scikit-learn-Python-Bibliothek
Die Scikit-learn-Bibliothek ist effizient bei der Merkmalsextraktion aus Text- und Bilddatensätzen. Darüber hinaus ist es möglich, die Genauigkeit von überwachten Modellen anhand von unsichtbaren Daten zu überprüfen. Seine zahlreichen verfügbaren Algorithmen ermöglichen Data Mining und andere Aufgaben des maschinellen Lernens.
SciPy
SciPy (Scientific Python Code) ist eine Bibliothek für maschinelles Lernen, die Module bereitstellt, die auf mathematische Funktionen und Algorithmen angewendet werden, die weit verbreitet sind. Seine Algorithmen lösen algebraische Gleichungen, Interpolation, Optimierung, Statistik und Integration.
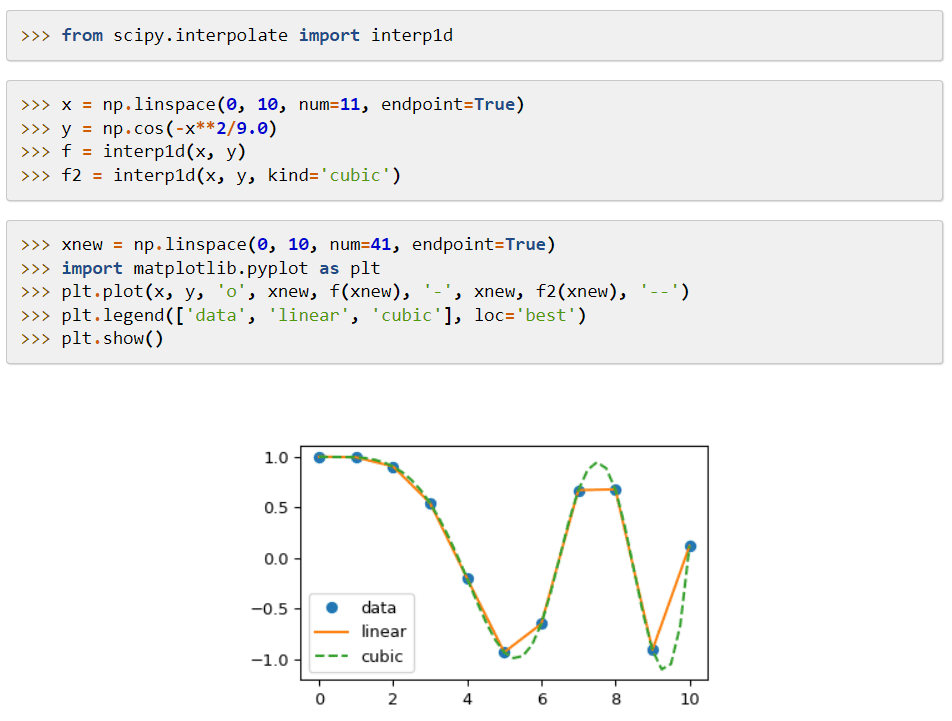
Sein Hauptmerkmal ist seine Erweiterung zu NumPy, die Tools zum Lösen der mathematischen Funktionen hinzufügt und Datenstrukturen wie Sparse-Matrizen bereitstellt.
SciPy verwendet High-Level-Befehle und -Klassen, um Daten zu manipulieren und zu visualisieren. Seine Datenverarbeitungs- und Prototypensysteme machen es zu einem noch effektiveren Werkzeug.
Darüber hinaus erleichtert die High-Level-Syntax von SciPy die Verwendung für Programmierer aller Erfahrungsstufen.
Der einzige Nachteil von SciPy ist sein alleiniger Fokus auf numerische Objekte und Algorithmen; daher keine Plotfunktion anbieten.
PyTorch
Diese vielseitige Bibliothek für maschinelles Lernen implementiert effizient Tensorberechnungen mit GPU-Beschleunigung und erstellt dynamische Berechnungsdiagramme und automatische Gradientenberechnungen. Die Torch-Bibliothek, eine auf C entwickelte Open-Source-Bibliothek für maschinelles Lernen, baut die PyTorch-Bibliothek auf.

Zu den Hauptmerkmalen gehören:
Sie können PyTorch bei der Entwicklung von NLP-Anwendungen verwenden.
Keras
Keras ist eine Open-Source-Python-Bibliothek für maschinelles Lernen, die zum Experimentieren mit tiefen neuronalen Netzen verwendet wird.
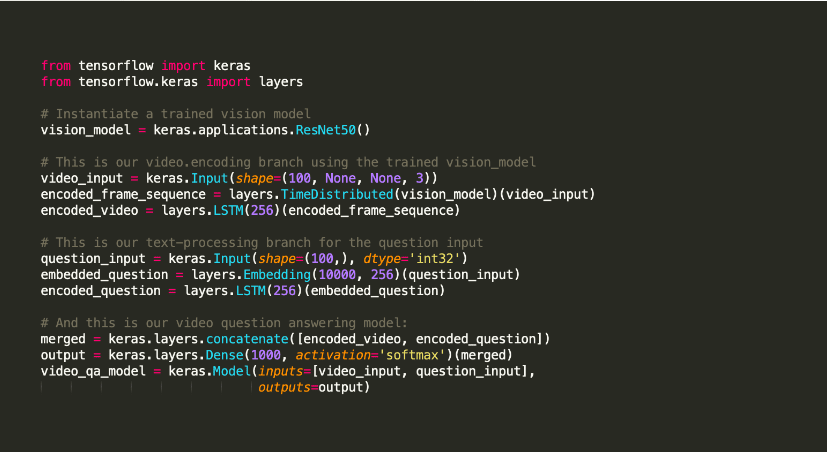
Es ist berühmt dafür, Dienstprogramme anzubieten, die unter anderem Aufgaben wie das Kompilieren von Modellen und die Visualisierung von Diagrammen unterstützen. Es wendet Tensorflow für sein Backend an. Alternativ können Sie Theano oder neuronale Netze wie CNTK im Backend verwenden. Diese Backend-Infrastruktur hilft ihm, Berechnungsgraphen zu erstellen, die zur Implementierung von Operationen verwendet werden.
Hauptmerkmale der Bibliothek
Zu den Anwendungen von Keras gehören neuronale Netzwerkbausteine wie Ebenen und Ziele sowie andere Tools, die die Arbeit mit Bildern und Textdaten erleichtern.
Seegeboren
Seaborn ist ein weiteres wertvolles Tool zur Visualisierung statistischer Daten.
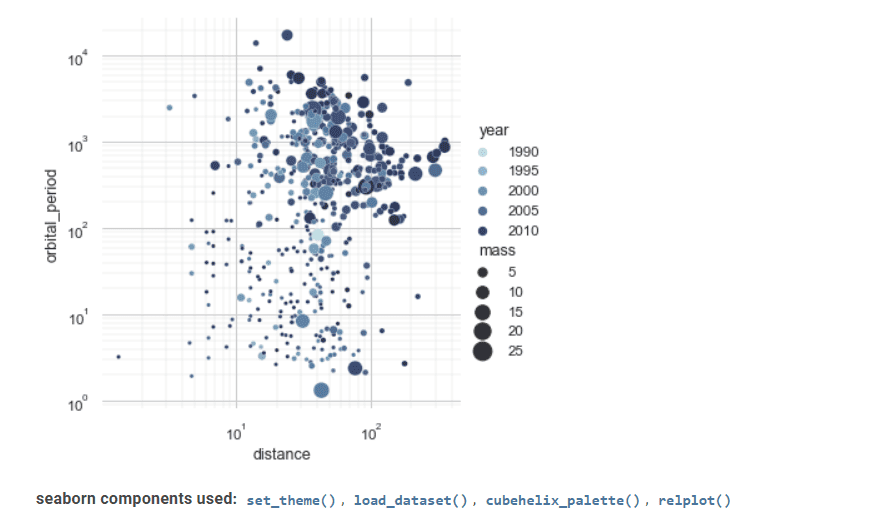
Seine fortschrittliche Schnittstelle kann attraktive und informative statistische Grafikzeichnungen implementieren.
Plotzlich
Plotly ist ein webbasiertes 3D-Visualisierungstool, das auf der Plotly JS-Bibliothek aufbaut. Es bietet breite Unterstützung für verschiedene Diagrammtypen wie Liniendiagramme, Streudiagramme und Sparklines vom Typ Box.
Seine Anwendung umfasst die Erstellung webbasierter Datenvisualisierungen in Jupyter-Notebooks.
Plotly eignet sich zur Visualisierung, da es mit seinem Hover-Tool auf Ausreißer oder Auffälligkeiten in der Grafik hinweisen kann. Sie können die Diagramme auch an Ihre Vorlieben anpassen.
Auf der anderen Seite von Plotly ist die Dokumentation veraltet; Daher kann es für den Benutzer schwierig sein, es als Leitfaden zu verwenden. Darüber hinaus verfügt es über zahlreiche Tools, die der Benutzer lernen sollte. Es kann schwierig sein, den Überblick über alle zu behalten.
Funktionen der Plotly-Python-Bibliothek
SimpleITK
SimpleITK ist eine Bildanalysebibliothek, die eine Schnittstelle zu Insight Toolkit (ITK) bietet. Es basiert auf C++ und ist Open Source.
Funktionen der SimpleITK-Bibliothek
Seine vereinfachte Schnittstelle ist in verschiedenen Programmiersprachen wie R, C#, C++, Java und Python verfügbar.
Statistikmodell
Statsmodel schätzt statistische Modelle, implementiert statistische Tests und untersucht statistische Daten mithilfe von Klassen und Funktionen.
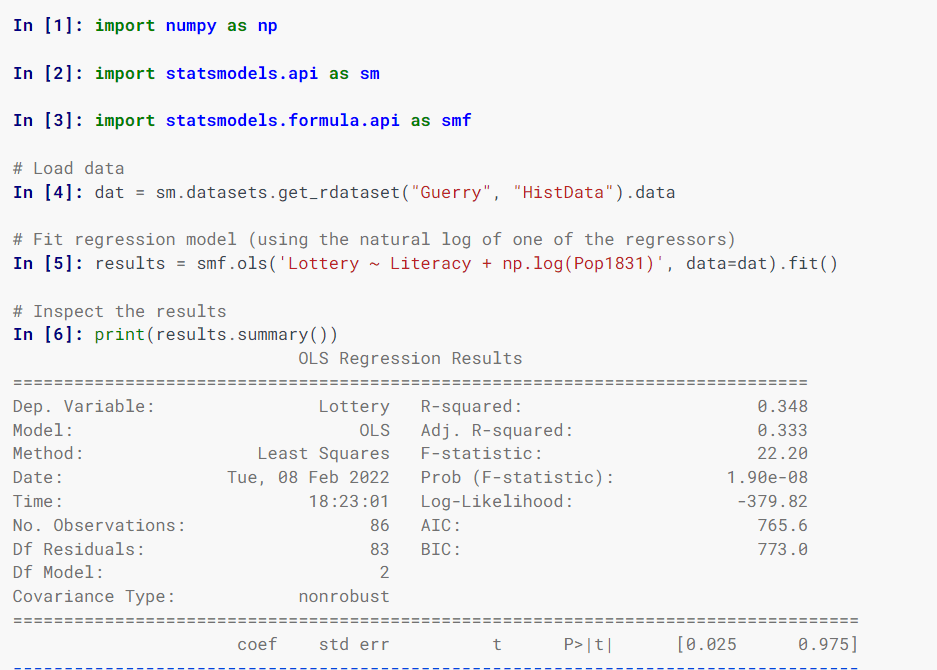
Bei der Angabe von Modellen werden Formeln im R-Stil, NumPy-Arrays und Pandas-Datenrahmen verwendet.
Schroff
Dieses Open-Source-Paket ist ein bevorzugtes Tool zum Abrufen (Scraping) und Crawlen von Daten von einer Website. Es ist asynchron und daher relativ schnell. Scrapy hat eine Architektur und Funktionen, die es effizient machen.
Auf der anderen Seite unterscheidet sich die Installation für verschiedene Betriebssysteme. Außerdem können Sie es nicht auf Websites verwenden, die auf JS basieren. Außerdem funktioniert es nur mit Python 2.7 oder späteren Versionen.
Data-Science-Experten wenden es beim Data Mining und automatisierten Testen an.
Merkmale
Kopfkissen
Pillow ist eine Python-Imaging-Bibliothek, die Bilder manipuliert und verarbeitet.
Es erweitert die Bildverarbeitungsfunktionen des Python-Interpreters, unterstützt verschiedene Dateiformate und bietet eine hervorragende interne Darstellung.
Dank Pillow kann problemlos auf Daten zugegriffen werden, die in einfachen Dateiformaten gespeichert sind.
Abschluss💃
Das fasst unsere Untersuchung einiger der besten Python-Bibliotheken für Data Scientists und Experten für maschinelles Lernen zusammen.
Wie dieser Artikel zeigt, verfügt Python über nützlichere Pakete für maschinelles Lernen und Data Science. Python hat andere Bibliotheken, die Sie in anderen Bereichen anwenden können.
Vielleicht möchten Sie etwas über einige der besten Data-Science-Notebooks erfahren.
Viel Spaß beim Lernen!