

MapReduce bietet eine effektive, schnellere und kostengünstigere Möglichkeit, Anwendungen zu erstellen.
Dieses Modell nutzt fortschrittliche Konzepte wie Parallelverarbeitung, Datenlokalität usw., um Programmierern und Organisationen viele Vorteile zu bieten.
Aber es gibt so viele Programmiermodelle und Frameworks auf dem Markt, dass die Auswahl schwierig wird.
Und wenn es um Big Data geht, kann man sich nicht aussuchen. Sie müssen solche Technologien auswählen, die große Datenmengen verarbeiten können.
MapReduce ist eine großartige Lösung dafür.
In diesem Artikel werde ich diskutieren, was MapReduce wirklich ist und wie es nützlich sein kann.
Lasst uns beginnen!
Inhaltsverzeichnis
Was ist MapReduce?
MapReduce ist ein Programmiermodell oder Software-Framework innerhalb des Apache Hadoop-Frameworks. Es wird zum Erstellen von Anwendungen verwendet, die in der Lage sind, riesige Datenmengen parallel auf Tausenden von Knoten (Cluster oder Grids genannt) mit Fehlertoleranz und Zuverlässigkeit zu verarbeiten.
Diese Datenverarbeitung erfolgt in einer Datenbank oder einem Dateisystem, in dem die Daten gespeichert werden. MapReduce kann mit einem Hadoop-Dateisystem (HDFS) zusammenarbeiten, um auf große Datenmengen zuzugreifen und diese zu verwalten.
Dieses Framework wurde 2004 von Google eingeführt und durch Apache Hadoop populär gemacht. Es ist eine Verarbeitungsschicht oder Engine in Hadoop, auf der MapReduce-Programme ausgeführt werden, die in verschiedenen Sprachen entwickelt wurden, darunter Java, C++, Python und Ruby.
Die MapReduce-Programme im Cloud-Computing laufen parallel und eignen sich daher für die Durchführung von Datenanalysen in großem Umfang.
MapReduce zielt darauf ab, eine Aufgabe mithilfe der Funktionen „map“ und „reduce“ in kleinere, mehrere Aufgaben aufzuteilen. Es ordnet jede Aufgabe zu und reduziert sie dann auf mehrere gleichwertige Aufgaben, was zu einer geringeren Verarbeitungsleistung und einem geringeren Overhead im Cluster-Netzwerk führt.
Beispiel: Angenommen, Sie bereiten ein Essen für ein Haus voller Gäste zu. Wenn Sie also versuchen, alle Gerichte zuzubereiten und alle Prozesse selbst zu erledigen, wird es hektisch und zeitaufwändig.
Angenommen, Sie beziehen einige Ihrer Freunde oder Kollegen (keine Gäste) mit ein, um Ihnen bei der Zubereitung des Essens zu helfen, indem Sie verschiedene Prozesse auf eine andere Person verteilen, die die Aufgaben gleichzeitig ausführen kann. In diesem Fall bereiten Sie das Essen viel schneller und einfacher zu, während Ihre Gäste noch im Haus sind.
MapReduce arbeitet auf ähnliche Weise mit verteilten Aufgaben und paralleler Verarbeitung, um eine schnellere und einfachere Möglichkeit zu ermöglichen, eine bestimmte Aufgabe zu erledigen.
Mit Apache Hadoop können Programmierer MapReduce verwenden, um Modelle auf großen verteilten Datensätzen auszuführen und fortschrittliche maschinelle Lern- und Statistiktechniken zu verwenden, um Muster zu finden, Vorhersagen zu treffen, Korrelationen zu erkennen und vieles mehr.
Funktionen von MapReduce
Einige der Hauptfunktionen von MapReduce sind:
- Benutzeroberfläche: Sie erhalten eine intuitive Benutzeroberfläche, die angemessene Details zu jedem Aspekt des Frameworks bietet. Es hilft Ihnen, Ihre Aufgaben nahtlos zu konfigurieren, anzuwenden und abzustimmen.

- Payload: Anwendungen verwenden Mapper- und Reducer-Schnittstellen, um die Karten- und Reduktionsfunktionen zu aktivieren. Der Mapper ordnet eingegebene Schlüssel-Wert-Paare Zwischen-Schlüssel-Wert-Paaren zu. Reducer wird verwendet, um Zwischenschlüssel-Wert-Paare, die einen Schlüssel teilen, auf andere kleinere Werte zu reduzieren. Es führt drei Funktionen aus – Sortieren, Mischen und Reduzieren.
- Partitionierer: Er steuert die Aufteilung der Zwischenkarten-Ausgabeschlüssel.
- Reporter: Es ist eine Funktion, um den Fortschritt zu melden, Zähler zu aktualisieren und Statusmeldungen festzulegen.
- Zähler: Stellt globale Zähler dar, die eine MapReduce-Anwendung definiert.
- OutputCollector: Diese Funktion sammelt Ausgabedaten von Mapper oder Reducer anstelle von Zwischenausgaben.
- RecordWriter: Er schreibt die Datenausgabe oder Schlüssel-Wert-Paare in die Ausgabedatei.
- DistributedCache: Es verteilt effizient größere, schreibgeschützte Dateien, die anwendungsspezifisch sind.
- Datenkomprimierung: Der Anwendungsautor kann sowohl Jobausgaben als auch Zwischenkartenausgaben komprimieren.
- Überspringen fehlerhafter Datensätze: Sie können mehrere fehlerhafte Datensätze überspringen, während Sie Ihre Karteneingaben verarbeiten. Diese Funktion kann über die Klasse SkipBadRecords gesteuert werden.
- Debugging: Sie erhalten die Option, benutzerdefinierte Skripts auszuführen und das Debugging zu aktivieren. Wenn eine Aufgabe in MapReduce fehlschlägt, können Sie Ihr Debug-Skript ausführen und die Probleme finden.
MapReduce-Architektur
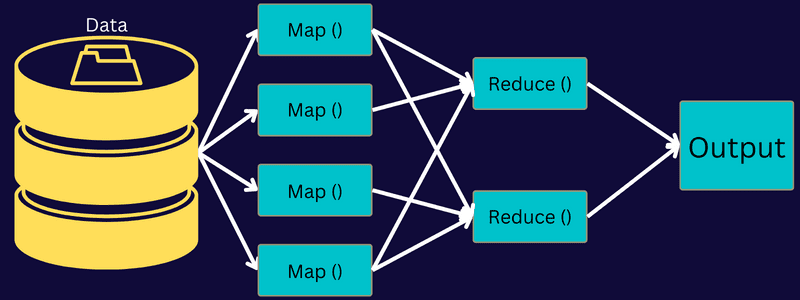
Lassen Sie uns die Architektur von MapReduce verstehen, indem wir uns eingehender mit seinen Komponenten befassen:
- Job: Ein Job in MapReduce ist die eigentliche Aufgabe, die der MapReduce-Client ausführen möchte. Es besteht aus mehreren kleineren Aufgaben, die zusammen die endgültige Aufgabe bilden.
- Job History Server: Dies ist ein Daemon-Prozess zum Speichern aller Verlaufsdaten zu einer Anwendung oder Aufgabe, z. B. Protokolle, die nach oder vor der Ausführung eines Jobs erstellt wurden.
- Client: Ein Client (Programm oder API) bringt MapReduce einen Auftrag zur Ausführung oder Verarbeitung. In MapReduce können ein oder mehrere Clients kontinuierlich Aufträge zur Verarbeitung an den MapReduce Manager senden.
- MapReduce Master: Ein MapReduce Master unterteilt einen Job in mehrere kleinere Teile, um sicherzustellen, dass Aufgaben gleichzeitig fortschreiten.
- Job-Teile: Die Sub-Jobs oder Job-Teile werden durch Teilung des Hauptjobs erhalten. Sie werden bearbeitet und schließlich kombiniert, um die endgültige Aufgabe zu erstellen.
- Eingabedaten: Dies ist der Datensatz, der MapReduce zur Aufgabenverarbeitung zugeführt wird.
- Ausgabedaten: Dies ist das Endergebnis, das nach der Verarbeitung der Aufgabe erhalten wird.
Was in dieser Architektur wirklich passiert, ist, dass der Client einen Auftrag an den MapReduce-Master sendet, der ihn in kleinere, gleiche Teile aufteilt. Dadurch kann der Auftrag schneller verarbeitet werden, da kleinere Aufgaben weniger Zeit für die Verarbeitung benötigen als größere Aufgaben.
Stellen Sie jedoch sicher, dass die Aufgaben nicht in zu kleine Aufgaben aufgeteilt werden, denn wenn Sie das tun, müssen Sie möglicherweise einen größeren Aufwand für die Verwaltung von Aufteilungen bewältigen und viel Zeit dafür verschwenden.
Als Nächstes werden die Auftragsteile verfügbar gemacht, um mit den Aufgaben „Zuordnen“ und „Reduzieren“ fortzufahren. Darüber hinaus verfügen die Map- und Reduce-Aufgaben über ein geeignetes Programm, das auf dem Anwendungsfall basiert, an dem das Team arbeitet. Der Programmierer entwickelt den logikbasierten Code, um die Anforderungen zu erfüllen.
Danach werden die Eingabedaten an die Map-Aufgabe übergeben, damit die Map schnell die Ausgabe als Schlüssel-Wert-Paar generieren kann. Anstatt diese Daten auf HDFS zu speichern, wird eine lokale Festplatte verwendet, um die Daten zu speichern, um die Wahrscheinlichkeit einer Replikation auszuschließen.
Sobald die Aufgabe abgeschlossen ist, können Sie die Ausgabe verwerfen. Daher wird die Replikation zu einem Overkill, wenn Sie die Ausgabe auf HDFS speichern. Die Ausgabe jeder Map-Aufgabe wird der Reduce-Aufgabe zugeführt, und die Map-Ausgabe wird der Maschine bereitgestellt, die die Reduce-Aufgabe ausführt.
Als nächstes wird die Ausgabe zusammengeführt und an die vom Benutzer definierte Reduce-Funktion übergeben. Schließlich wird die reduzierte Ausgabe auf einem HDFS gespeichert.
Darüber hinaus kann der Prozess je nach Endziel mehrere Map-and-Reduce-Aufgaben für die Datenverarbeitung haben. Die Map- und Reduce-Algorithmen sind optimiert, um die zeitliche oder räumliche Komplexität minimal zu halten.
Da MapReduce in erster Linie Map- und Reduce-Aufgaben umfasst, ist es wichtig, mehr darüber zu verstehen. Lassen Sie uns also die Phasen von MapReduce besprechen, um eine klare Vorstellung von diesen Themen zu bekommen.
Phasen von MapReduce
Karte
Die Eingabedaten werden in dieser Phase den Ausgabe- oder Schlüssel-Wert-Paaren zugeordnet. Hier kann sich der Schlüssel auf die ID einer Adresse beziehen, während der Wert der tatsächliche Wert dieser Adresse sein kann.
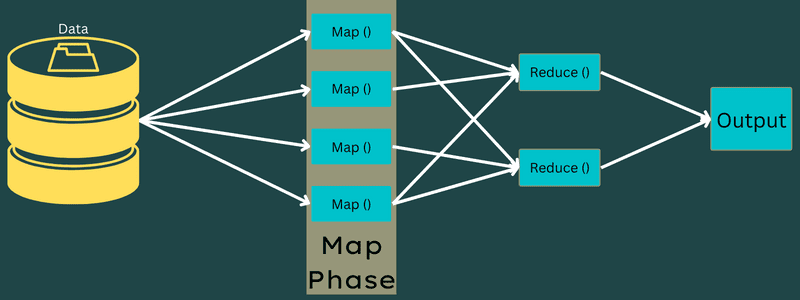
In dieser Phase gibt es nur eine, aber zwei Aufgaben – Splits und Mapping. Splits bedeutet die vom Hauptjob abgeteilten Neben- oder Auftragsteile. Diese werden auch Input-Splits genannt. Ein Input-Split kann also als Input-Chunk bezeichnet werden, der von einer Map verbraucht wird.
Als nächstes findet die Mapping-Aufgabe statt. Es wird als die erste Phase beim Ausführen eines Map-Reduce-Programms betrachtet. Hier werden die in jeder Teilung enthaltenen Daten an eine Zuordnungsfunktion übergeben, um die Ausgabe zu verarbeiten und zu generieren.
Die Funktion – Map() wird im Speicher-Repository auf den eingegebenen Schlüssel-Wert-Paaren ausgeführt und generiert ein Zwischen-Schlüssel-Wert-Paar. Dieses neue Schlüssel-Wert-Paar dient als Eingabe für die Funktion Reduce() oder Reducer.
Reduzieren
Die in der Mapping-Phase erhaltenen Zwischenschlüssel-Wert-Paare dienen als Eingabe für die Reduce-Funktion oder den Reducer. Ähnlich wie bei der Mapping-Phase sind zwei Aufgaben beteiligt – Mischen und Reduzieren.
Die erhaltenen Schlüssel-Wert-Paare werden also sortiert und gemischt, um dem Reducer zugeführt zu werden. Als Nächstes gruppiert oder aggregiert der Reducer die Daten gemäß ihrem Schlüssel-Wert-Paar basierend auf dem Reducer-Algorithmus, den der Entwickler geschrieben hat.
Hier werden die Werte aus der Mischphase kombiniert, um einen Ausgangswert zurückzugeben. Diese Phase fasst den gesamten Datensatz zusammen.
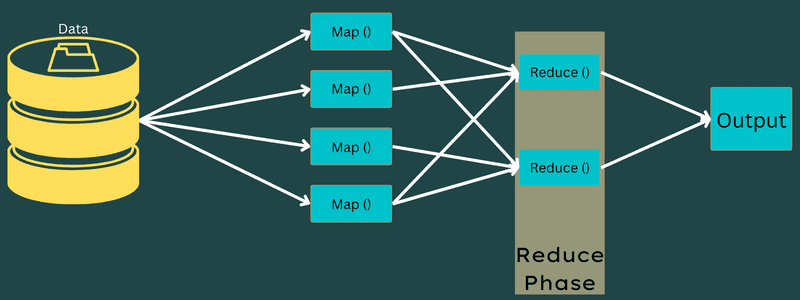
Jetzt wird der vollständige Prozess der Ausführung von Zuordnungs- und Reduzierungsaufgaben von einigen Entitäten gesteuert. Diese sind:
- Job Tracker: Einfach ausgedrückt fungiert ein Job Tracker als Master, der für die vollständige Ausführung eines eingereichten Jobs verantwortlich ist. Der Job-Tracker verwaltet alle Jobs und Ressourcen in einem Cluster. Darüber hinaus plant der Job-Tracker jede Map, die dem Task-Tracker hinzugefügt wird und auf einem bestimmten Datenknoten ausgeführt wird.
- Mehrere Task-Tracker: In einfachen Worten, mehrere Task-Tracker arbeiten als Sklaven, die die Aufgabe gemäß den Anweisungen des Job-Trackers ausführen. Ein Task-Tracker wird auf jedem Knoten separat im Cluster bereitgestellt, der die Map- und Reduce-Tasks ausführt.
Es funktioniert, weil ein Job in mehrere Tasks aufgeteilt wird, die auf verschiedenen Datenknoten eines Clusters ausgeführt werden. Der Job Tracker ist für die Koordinierung der Aufgabe verantwortlich, indem er die Aufgaben plant und auf mehreren Datenknoten ausführt. Als nächstes führt der Task Tracker, der auf jedem Datenknoten sitzt, Teile des Jobs aus und kümmert sich um jede Aufgabe.
Darüber hinaus senden die Task Tracker Fortschrittsberichte an den Job Tracker. Außerdem sendet der Task Tracker regelmäßig ein „Heartbeat“-Signal an den Job Tracker und benachrichtigt ihn über den Systemstatus. Im Falle eines Fehlers ist ein Job-Tracker in der Lage, den Job auf einem anderen Task-Tracker neu zu planen.
Ausgabephase: Wenn Sie diese Phase erreichen, werden die endgültigen Schlüssel-Wert-Paare vom Reducer generiert. Sie können einen Ausgabeformatierer verwenden, um die Schlüssel-Wert-Paare zu übersetzen und sie mit Hilfe eines Record Writers in eine Datei zu schreiben.
Warum MapReduce verwenden?
Hier sind einige der Vorteile von MapReduce und erläutern die Gründe, warum Sie es in Ihren Big-Data-Anwendungen verwenden müssen:
Parallelverarbeitung
Sie können einen Auftrag in verschiedene Knoten aufteilen, wobei jeder Knoten gleichzeitig einen Teil dieses Auftrags in MapReduce bearbeitet. Die Aufteilung größerer Aufgaben in kleinere verringert also die Komplexität. Da außerdem verschiedene Tasks parallel auf verschiedenen Maschinen statt auf einer einzigen Maschine laufen, dauert die Verarbeitung der Daten erheblich weniger.
Datenlokalität
In MapReduce können Sie die Verarbeitungseinheit zu den Daten verschieben, nicht umgekehrt.
Auf traditionelle Weise wurden die Daten zur Verarbeitung zur Verarbeitungseinheit gebracht. Mit dem schnellen Datenwachstum stellte dieser Prozess jedoch viele Herausforderungen dar. Einige davon waren höhere Kosten, mehr Zeitaufwand, Belastung des Masterknotens, häufige Ausfälle und reduzierte Netzwerkleistung.
Aber MapReduce hilft, diese Probleme zu überwinden, indem es einen umgekehrten Ansatz verfolgt – eine Verarbeitungseinheit zu Daten bringt. Auf diese Weise werden die Daten auf verschiedene Knoten verteilt, wobei jeder Knoten einen Teil der gespeicherten Daten verarbeiten kann.
Dadurch bietet es Kosteneffizienz und reduziert die Verarbeitungszeit, da jeder Knoten parallel mit seinem entsprechenden Datenteil arbeitet. Da außerdem jeder Knoten einen Teil dieser Daten verarbeitet, wird kein Knoten überlastet.
Sicherheit

Das MapReduce-Modell bietet eine höhere Sicherheit. Es hilft, Ihre Anwendung vor nicht autorisierten Daten zu schützen und erhöht gleichzeitig die Cluster-Sicherheit.
Skalierbarkeit und Flexibilität
MapReduce ist ein hochskalierbares Framework. Es ermöglicht Ihnen, Anwendungen auf mehreren Computern auszuführen und Daten mit Tausenden von Terabyte zu verwenden. Es bietet auch die Flexibilität, Daten zu verarbeiten, die strukturiert, halbstrukturiert oder unstrukturiert und in jedem Format oder jeder Größe sein können.
Einfachheit
Sie können MapReduce-Programme in jeder Programmiersprache wie Java, R, Perl, Python und mehr schreiben. Daher ist es für jedermann einfach, Programme zu lernen und zu schreiben und gleichzeitig sicherzustellen, dass seine Datenverarbeitungsanforderungen erfüllt werden.
Anwendungsfälle von MapReduce
- Volltextindizierung: MapReduce wird verwendet, um eine Volltextindizierung durchzuführen. Sein Mapper kann jedes Wort oder jeden Satz in einem einzigen Dokument abbilden. Und der Reducer wird verwendet, um alle gemappten Elemente in einen Index zu schreiben.
- Berechnung des Pageranks: Google verwendet MapReduce zur Berechnung des Pageranks.
- Protokollanalyse: MapReduce kann Protokolldateien analysieren. Es kann eine große Protokolldatei in verschiedene Teile oder Splits zerlegen, während der Mapper nach aufgerufenen Webseiten sucht.
Ein Schlüssel-Wert-Paar wird dem Reducer zugeführt, wenn eine Webseite im Protokoll entdeckt wird. Hier ist die Webseite der Schlüssel und der Index „1“ ist der Wert. Nachdem ein Schlüssel-Wert-Paar an den Reducer übergeben wurde, werden verschiedene Webseiten aggregiert. Die endgültige Ausgabe ist die Gesamtzahl der Treffer für jede Webseite.

- Reverse Web-Link Graph: Das Framework findet auch Verwendung in Reverse Web-Link Graph. Hier liefert Map() das URL-Ziel und die Quelle und nimmt Eingaben von der Quelle oder Webseite entgegen.
Als nächstes aggregiert Reduce() die Liste jeder Quell-URL, die der Ziel-URL zugeordnet ist. Schließlich gibt es die Quellen und das Ziel aus.
- Wortzählung: MapReduce wird verwendet, um zu zählen, wie oft ein Wort in einem bestimmten Dokument vorkommt.
- Globale Erwärmung: Organisationen, Regierungen und Unternehmen können MapReduce verwenden, um Probleme der globalen Erwärmung zu lösen.
Beispielsweise möchten Sie vielleicht etwas über die erhöhte Temperatur des Ozeans aufgrund der globalen Erwärmung wissen. Dafür können Sie Tausende von Daten auf der ganzen Welt sammeln. Die Daten können hohe Temperatur, niedrige Temperatur, Breite, Länge, Datum, Uhrzeit usw. sein. Dies erfordert mehrere Karten und reduziert die Aufgaben, um die Ausgabe mit MapReduce zu berechnen.
- Arzneimittelstudien: Traditionell arbeiteten Datenwissenschaftler und Mathematiker zusammen, um ein neues Medikament zu formulieren, das eine Krankheit bekämpfen kann. Mit der Verbreitung von Algorithmen und MapReduce können IT-Abteilungen in Organisationen problemlos Probleme angehen, die nur von Supercomputers, Ph.D. Wissenschaftler usw. Jetzt können Sie die Wirksamkeit eines Medikaments für eine Gruppe von Patienten untersuchen.
- Andere Anwendungen: MapReduce kann sogar große Datenmengen verarbeiten, die sonst nicht in eine relationale Datenbank passen würden. Es verwendet auch Data-Science-Tools und ermöglicht deren Ausführung über verschiedene, verteilte Datensätze, was bisher nur auf einem einzigen Computer möglich war.
Aufgrund der Robustheit und Einfachheit von MapReduce findet es Anwendungen im Militär, in der Wirtschaft, in der Wissenschaft usw.
Fazit
MapReduce kann sich als technologischer Durchbruch erweisen. Es ist nicht nur ein schneller und einfacher Prozess, sondern auch kostengünstiger und weniger zeitaufwändig. Angesichts seiner Vorteile und zunehmenden Nutzung wird es wahrscheinlich eine stärkere Akzeptanz in Branchen und Organisationen erfahren.
Sie können auch einige der besten Ressourcen zum Erlernen von Big Data und Hadoop erkunden.