
Das mehrdimensionale Schema dient zum Erstellen eines Data-Warehouse-Systemmodells.
Der Hauptzweck dieser Schemas besteht darin, die Anforderungen größerer Datenbanken zu erfüllen, die für Analysezwecke (OLAP) erstellt wurden.
Diese Methode wird verwendet, um Daten in der Datenbank mit einer guten Anordnung der Inhalte in einer Datenbank zu ordnen. Das Schema ermöglicht es Kunden, Fragen zu Geschäfts- oder Markttrends zu stellen.
Darüber hinaus stellt ein mehrdimensionales Schema die Daten in Form von Datenwürfeln dar, die es ermöglichen, Daten aus verschiedenen Perspektiven und Dimensionen zu betrachten und zu modellieren.
Es gibt drei Arten, aber viele verwechseln Stern und Schneeflocke. Daher wird es für sie schwierig, das bevorzugte Modell auszuwählen.
Wenn Sie einer von ihnen sind, lassen Sie uns die Unterschiede zwischen dem Stern- und dem Schneeflockenschema besprechen, beginnend mit der Definition und dem Verständnis ihrer Vorteile, Herausforderungen, Diagramme und Eigenschaften.
Inhaltsverzeichnis
Was ist ein mehrdimensionales Schema?
Schema bezieht sich auf die logische Beschreibung einer vollständigen Datenbank und Data Marts. Es enthält den Namen von Datensätzen und ihre Beschreibungen, einschließlich Aggregate und zugehöriger Datenelemente.
Eine Datenbank verwendet im Allgemeinen ein relationales Modell zur Beschreibung, während ein Data-Warehouse-System ein Schema-Modell verwendet.
Mehrdimensionale Schemas können mit Data Mining Query Language (DMQL) definiert werden.
Um die Data Marts und Data Warehouses zu definieren, verwendet es zwei Primitive – Dimensionsdefinition und Cube-Definition.
Das mehrdimensionale Schema verwendet verschiedene Arten von Schemamodellen. Sie sind:
- Sternschema
- Snowflake-Schema
- Galaxy-Schema
Lassen Sie uns diskutieren, was Stern- und Snowflake-Schemata sind.
Stern vs. Schneeflocke: Was sind sie?
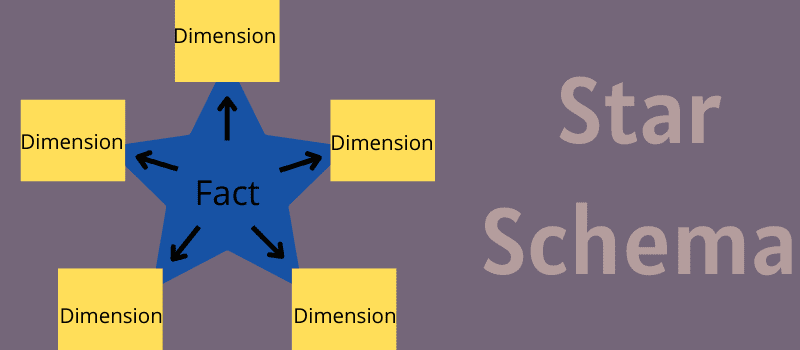
Was ist Star-Schema?
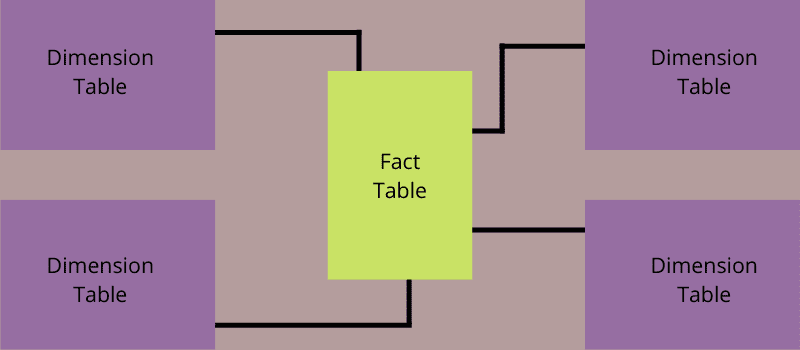
Ein Sternschema ist ein architektonisches Data-Warehousing- und Business-Intelligence-Modell, das eine einzige Faktentabelle zum Speichern von Mess- und Transaktionsdaten erfordert. Es verwendet auch verschiedene kleinere Dimensionstabellen, um Attribute zu Geschäftsdaten zu speichern.
Es wird nach seiner Struktur benannt. Wie ein Stern nimmt die Faktentabelle ihren Platz in der Mitte des Diagramms ein, und kleine Dimensionstabellen sitzen wie Zweige an der Mitteltabelle, um eine sternähnliche Struktur zu bilden.
Jedes Sternschema besteht aus einer einzelnen Faktentabelle, aber mehreren kleinen Dimensionstabellen. Die Faktentabellen enthalten spezifische, messbare Daten, die analysiert werden müssen, wie z. B. protokollierte Leistung, Finanzdaten oder Verkaufsaufzeichnungen. Es kann sich um einen Schnappschuss historischer Daten zu einem Zeitpunkt oder um Transaktionsdaten handeln.
Darüber hinaus ist das Star-Schema das einfachste und grundlegendste unter den Data Warehouses und Data Mart-Schemata. Es ist effizient bei der Behandlung grundlegender Abfragen. Das Star-Schema unterstützt im Allgemeinen Business Intelligence, Ad-hoc-Abfragen, Analyseanwendungen und analytische Online-Verarbeitungswürfel.
Das Star-Schema unterstützt auch Zählung, Durchschnitt, Summe und andere Aggregationen vieler Datensätze. Benutzer können die Aggregationen einfach nach Dimensionen filtern und gruppieren. Beispielsweise generieren Benutzer Abfragen wie „alle Verkaufsaufzeichnungen im Juni finden“ oder „Gesamtumsatz des Büros XYZ im Jahr 2022 analysieren“.
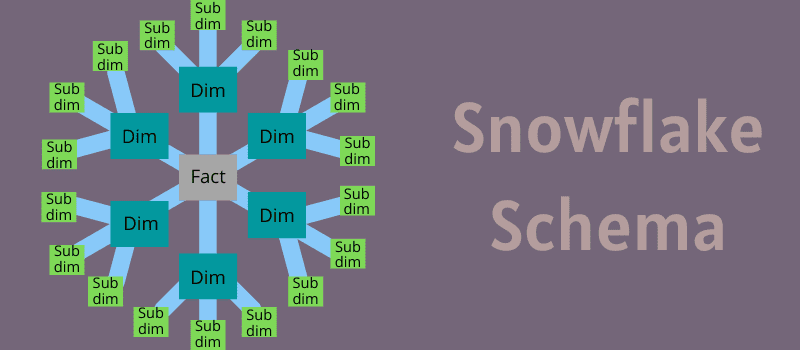
Was ist das Snowflake-Schema?
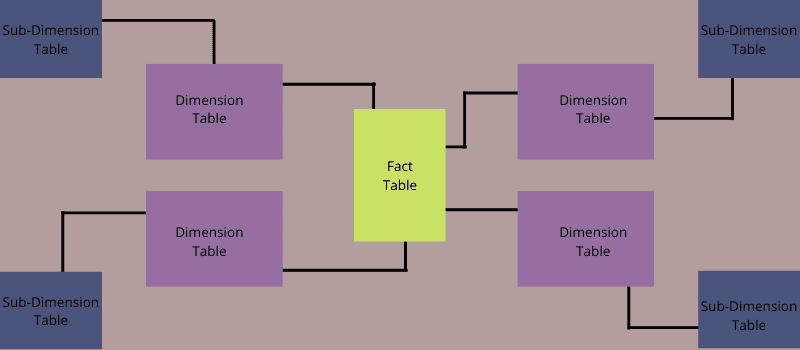
Ein Schneeflockenschema ist ein mehrdimensionales Datenmodell, das auch als Erweiterung des Sternschemas bezeichnet werden kann. Dies liegt daran, dass Dimensionstabellen im Schneeflockenschema in Unterdimensionen zerlegt werden.
Ein Schema ist eine Schneeflocke, wenn eine oder mehrere Dimensionstabellen nicht direkt mit der Faktentabelle verknüpft sind, sondern über andere Dimensionstabellen verbunden sind.
Snowflaking ist ein Phänomen, das die Dimensionstabellen in einem Sternschema normalisiert. Wenn Sie alle Dimensionstabellen normalisieren, ähnelt die resultierende Struktur einer Schneeflocke, die eine Faktentabelle in der Mitte der Struktur enthält.
Einfach ausgedrückt besteht das Schneeflockenschema aus einer Faktentabelle in der Mitte des Modells, die mit Dimensionstabellen verbunden ist, die wiederum mit anderen Dimensionstabellen verknüpft sind. Dieses Schema wird verwendet, um die Leistung der Abfragen zu verbessern.
Das Modell wurde für schnelle, flexible Abfragen über komplexe Beziehungen und Dimensionen hinweg erstellt. Es ist hilfreich für Eins-zu-Viele- und Viele-zu-Viele-Beziehungen zwischen verschiedenen Dimensionsebenen.
Aufgrund der strengeren Einhaltung von mehr Normalisierungsstandards erhalten Sie eine höhere Speichereffizienz. Die Datenredundanz ist jedoch vernachlässigbar, und die Leistung ist im Vergleich zu denormalisierten Datenmodellen wie dem Sternschema gering.
Star vs. Snowflake: Wie funktionieren sie?
Wie funktioniert ein Sternschema?
Die Faktentabelle in der Mitte des Sternmodells speichert zwei Arten von Informationen – numerische und Dimensionsattributwerte. Lassen Sie uns sie anhand eines Beispiels einer Verkaufsdatenbank verstehen.
- Numerische Werte sind für jede Zeile und jeden Datenpunkt eindeutig. Dies korreliert oder bezieht sich nicht auf die Daten, die in einer anderen Zeile gespeichert sind. Dies sind Fakten zu einer bestimmten Transaktion, wie z. B. Gesamtbetrag, Bestellmenge, genaue Zeit, Nettogewinn, Bestell-ID usw.
- Dimensionsattributwerte speichern keine Daten direkt, sondern Fremdschlüsselwerte für die Zeile in einer Dimensionstabelle. Verschiedene Zeilen in der mittleren Tabelle verweisen auf diese Informationen, z. B. Datenwert, Vertriebsmitarbeiter-ID, Zweigstellen-ID, Produkt-ID usw.
Dimensionstabellen speichern immer unterstützende Informationen aus der Faktentabelle. Jede Dimensionstabelle bezieht sich auf die Spalte einer Faktentabelle zusammen mit einem Dimensionswert und speichert zusätzliche Daten zu diesem Wert.
Beispiel: Die Mitarbeiterdimensionstabelle verwendet die Mitarbeiter-ID als Schlüsselwert und enthält auch Informationen wie Name, Geschlecht, Adresse und Telefonnummer. In ähnlicher Weise speichert eine Produktdimensionstabelle Informationen, einschließlich Produktname, Farbe, Datum der ersten Markteinführung, Herstellungskosten usw.
Wie funktioniert ein Snowflake-Schema?
Stellen Sie sich ein Schneeflocken-Design mit einem mittleren Kästchen und verschiedenen Verbindungen durch dieses Kästchen zu verschiedenen Punkten vor. Um Data Marts und Data Warehouses zu warten, kommt das Schneeflocken-Schema-Design ins Spiel.
Es ähnelt dem Sternschema, jedoch mit geringfügigen Änderungen. Im Gegensatz zum Sternschema erweitert das Schneeflockenschema seine Unterdimensionstabellen, die mit Dimensionstabellen verknüpft sind.
Der Hauptzweck dieses Modells besteht darin, die denormalisierten Informationen des Sternmodells zu normalisieren. Auf diese Weise können häufige Probleme im Zusammenhang mit einem Sternschema gelöst werden.
Im Kern des Schemas finden Sie eine Faktentabelle, die mit den in Dimensionstabellen enthaltenen Informationen verknüpft ist. Diese Tabellen strahlen wiederum nach außen zu Unterdimensionstabellen aus, die detaillierte Informationen haben, die die Dimensionstabelleninformationen beschreiben.
Beispiel: Das Schneeflockenschema enthält eine Verkaufsfaktentabelle und Tabellen mit Geschäftsstandorten, Linien, Familien, Produkten und Zeitdimensionen. Die Marktdimensionen bestehen aus zwei Dimensionstabellen, wobei das Geschäft die primäre Dimensionstabelle und der Standort des Geschäfts die Unterdimensionstabelle ist. Die Produktdimension hat drei Unterdimensionstabellen, die eine Produkt-, eine Linien- und eine Familien-Unterdimensionstabelle erwähnen.
Stern vs. Schneeflocke: Eigenschaften
Eigenschaften des Sternschemas
- Star-Schema kann Daten aus normalisierten Daten filtern, um Data-Warehousing-Anforderungen zu erfüllen. Der eindeutige Schlüssel wird aus den zugehörigen Informationen für jede Faktentabelle generiert, um jede Zeile zu identifizieren.
- Es bietet schnelle Berechnungen und Aggregationen, wie z. B. die erzielten Einnahmen und die Gesamtzahl der verkauften Artikel am Ende jedes Monats. Diese Details können nach Bedarf gefiltert werden, indem geeignete Abfragen formuliert werden.
- Es ist die Messung von Ereignissen, die endliche Zahlenwerte enthält, die aus dem Fremdschlüssel bestehen. Diese Schlüssel beziehen sich auf die Maßtabellen. Es gibt verschiedene Arten von Faktentabellen, die auf atomarer Ebene mit Werten eingerahmt sind.
- Die Transaktionsfaktentabelle enthält Daten zu bestimmten Ereignissen wie Verkäufen und Feiertagen.
- Die Erfassung von Fakten umfasst bestimmte Zeiträume wie Kontoinformationen zum Jahresende oder quartalsweise.
- Die Dimensionstabelle enthält detaillierte Daten zu Attributen oder Datensätzen, die in der mittleren Tabelle gefunden wurden.
- Der Benutzer ist in der Lage, einen eigenen Tisch nach seinen Bedürfnissen zu entwerfen.
- Sie können das Star-Schema verwenden, um Snapshot-Tabellen zu sammeln.
Eigenschaften des Snowflake-Schemas
- Das Snowflake-Schema benötigt wenig Speicherplatz.
- Dieses Modell ist aufgrund seiner separaten und Hauptabmessungstabellen einfach zu implementieren.
- Die Dimensionstabellen enthalten mindestens zwei Attribute, um Informationen in mehreren Körnungen zu definieren.
- Aufgrund mehrerer Tabellen ist die Performance im Vergleich zum Sternschema gering.
- Das Snowflake-Schema hat aufgrund der Normalisierung die höchste Datenintegritätsstufe und geringe Redundanzen.
Stern vs. Schneeflocke: Vorteile

Vorteile des Sternschemas
- Das Star-Schema ist der einfachste Weg unter den Data-Mart-Schemata.
- Es hat eine einfache Berichtslogik. Diese Logik wird dynamisch impliziert.
- Es wurde unter Verwendung von Fütterungswürfeln entwickelt, die über den Online-Transaktionsprozess angewendet werden, damit die Würfel effizient und effektiv funktionieren.
- Das Star-Schema wird mit einfacher Logik und Abfragen gebildet, die sich leicht aus dem Transaktionsprozess extrahieren lassen.
- Es bietet eine verbesserte Leistung für Berichtsanwendungen.
- Es wird eingesetzt, um die schnelle Wiederherstellung von Daten zu steuern.
- Die gefilterten und ausgewählten Informationen können einfach in verschiedenen Fällen angewendet werden.
Vorteile des Snowflake-Schemas
- Das Star-Schema wird verwendet, um die Abfrageleistung aufgrund geringerer Anforderungen an den Festplattenspeicher zu verbessern.
- Es bietet eine größere Skalierbarkeit in den Beziehungen zwischen Komponenten und Dimensionsebenen.
- Es ist einfacher zu pflegen.
- Star-Schema bietet schnellen Datenabruf.
- Es ist ein allgemeines und einfaches Datenschema für Data Warehousing.
- Es trägt zur Verbesserung der Datenqualität bei.
- Die strukturierten Daten reduzieren das Problem der Datenintegrität.
Star vs. Snowflake: Einschränkungen
Einschränkungen des Sternschemas
Es hat einen hohen denormalisierten und Integritätszustand. Der gesamte Prozess bricht zusammen, wenn der Benutzer die Daten nicht aktualisiert. Die Sicherheit und der Schutz sind ebenfalls begrenzt. Außerdem ist das Sternschema nicht so flexibel wie das analytische Modell. Es bietet keine effiziente Unterstützung für verschiedene Beziehungen.
Einschränkungen des Snowflake-Schemas
Die Haupteinschränkung bei Snowflake ist der zusätzliche Wartungsaufwand aufgrund der zunehmenden Anzahl kleiner Dimensionstabellen. Viele komplexe Abfragen machen es schwierig, die erforderlichen Daten zu finden. Außerdem ist die Umsetzungszeit der Frage aufgrund höherer Tabellen hoch. Dieses Modell ist auch starr und erfordert höhere Wartungskosten.
Stern vs. Schneeflocke: Unterschiede
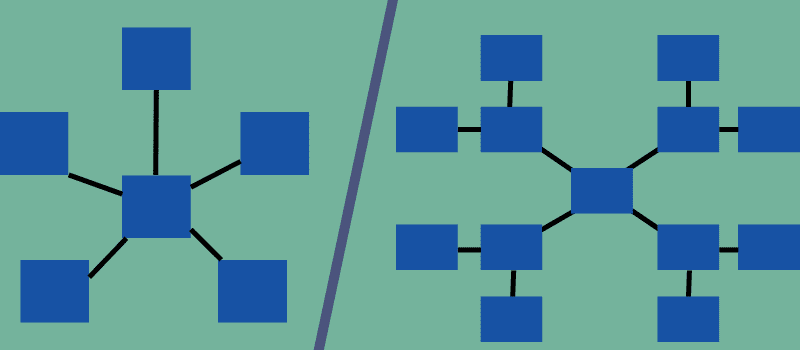
Star und Snowflake sind Arten von multidimensionalen Schemas, haben aber unterschiedliche Strukturen und Eigenschaften. Ersteres ist wie ein Stern und letzteres ähnelt einer Schneeflocke, die ihre Namen definiert.
Im Sternschema stellt nur ein einzelner Join eine Beziehung zwischen der zentralen Faktentabelle und den Seitendimensionstabellen her. Andererseits sind im Snowflake-Schema mehrere Joins erforderlich, um eine Verknüpfung mit Dimensionstabellen herzustellen.
Das Sternschema wird im Allgemeinen verwendet, wenn Sie weniger Zeilen in der Dimensionstabelle haben, während das Schneeflockenschema verwendet wird, wenn eine Dimensionstabelle relativ groß ist.
Das folgende Diagramm unterscheidet die beiden Modelle und wie die Dimensionstabellen und die Faktentabelle in verschiedenen Schemas verknüpft sind.
ParameterStar-SchemaSnowflake-SchemaFestplattenspeicherplatzStar-Schema verwendet mehr Speicherplatz.Snowflake-Schema verwendet weniger Speicherplatz.DatenredundanzEs hat eine hohe Datenredundanz.Es hat eine geringe Datenredundanz.NormalisierungDie Dimensionstabellen sind denormalisiert, was bedeutet, dass derselbe Wert innerhalb der Tabelle wiederholt wird.Die Dimensionstabellen sind vollständig normalisiert. Abfrageleistung Die Ausführung der Abfragen erfordert nur minimale Zeit, was zu einer besseren Leistung führt. Die Ausführung der Abfrage dauert länger als beim Star-Schema und ist daher weniger leistungsfähig als das Star-Schema. Abfragekomplexität Die Abfragekomplexität ist gering. Die Abfragekomplexität ist höher als das Sternschema.WartungAufgrund der hohen Datenredundanz ist die Pflege des Sternschemas etwas schwierig.Aufgrund der geringen Datenredundanz ist es einfach, das Schneeflockenschema zu warten und zu ändern.DatenintegritätDie Datenintegrität ist hoch, da Daten redundant gespeichert werden, wo mehrfach Kopien sind in den Dimensionstabellen vorhanden. Die Datenintegrität ist gering, da sie die Dimensionstabellen vollständig normalisiert. Hierarchien Hierarchien für die Dimensionstabellen im Sternschema werden in der Dimensionstabelle gespeichert.Hierarchien sind in separate Dimensionstabellen unterteilt.DB-DesignEs hat ein einfaches DB-Design.Es hat ein sehr komplexes DB-Design.FaktentabelleMehrere Dimensionstabellen umgeben eine Faktentabelle. Die Faktentabelle ist von Dimensionstabellen umgeben, die auch von Unterdimensionstabellen umgeben sind. Einrichten Das Sternschema ist einfach zu entwerfen und einzurichten, da direkte Beziehungen sie darstellen. Andererseits ist das Schneeflockenschema etwas komplex einzurichten. Cube-VerarbeitungDie Cube-Verarbeitung ist schneller.Aufgrund der komplexen Verknüpfung ist die Cube-Verarbeitung etwas langsam.FremdschlüsselEs hat eine minimale Anzahl von Fremdschlüsseln.Es hat die maximale Anzahl von Fremdschlüsseln.
Fazit
Sowohl Star- als auch Snowflake-Schemata sind in verschiedenen Sektoren nützlich. Die Entscheidung, welches unter ihnen besser ist, basiert also auf ihren Anforderungen.
Das Snowflake-Schema ist die Erweiterung des Star-Schemas, wobei es die Dimensionstabellen im Star-Schema normalisiert.
Das Star-Schema hat ein einfaches Design, führt Abfragen schneller aus und ist einfach einzurichten. Andererseits ist das Snowflake-Schema einfacher zu warten, benötigt weniger Speicherplatz und ist weniger anfällig für Datenintegritätsprobleme.
Ein Sternschema könnte also die bessere Option sein, wenn Sie ein einfaches Design, weniger Fremdschlüssel und eine schnellere Cube-Verarbeitung benötigen. Wenn Sie jedoch weniger Speicherplatz, geringe Datenintegrität und geringen Wartungsaufwand benötigen, kann das Snowflake-Schema besser geeignet sein.
Sie können auch einige der besten Lösungen für Graphdatenbanken erkunden.