

Wenn Sie ein paar Computerprogrammiersprachen gelernt haben, haben Sie vielleicht schon einmal den Begriff Parsing Text gehört. Dies wird verwendet, um die komplexen Datenwerte der Datei zu vereinfachen. Der Artikel hilft Ihnen zu wissen, wie Sie Text mit der Sprache parsen. Wenn Sie außerdem auf einen Fehler beim Analysieren von Text x gestoßen sind, wissen Sie, wie Sie den Parsing-Fehler im Artikel beheben können.

Inhaltsverzeichnis
So analysieren Sie Text
In diesem Artikel haben wir eine vollständige Anleitung zum Parsen von Text auf verschiedene Arten gezeigt und auch eine kurze Einführung in das Parsen von Text gegeben.
Was ist Textanalyse?
Bevor Sie sich mit den Konzepten des Analysierens von Text unter Verwendung eines beliebigen Codes vertraut machen. Es ist wichtig, die Grundlagen der Sprache und der Codierung zu kennen.
NLP oder Natural Language Processing
Um Text zu analysieren, wird die Verarbeitung natürlicher Sprache oder NLP verwendet, die ein Untergebiet der Domäne der künstlichen Intelligenz ist. Die Python-Sprache, eine der Sprachen, die zu dieser Kategorie gehören, wird zum Analysieren von Text verwendet.
Die NLP-Codes ermöglichen es Computern, menschliche Sprachen zu verstehen und zu verarbeiten, um sie für verschiedene Anwendungen geeignet zu machen. Um ML- oder maschinelle Lerntechniken auf die Sprache anzuwenden, müssen die unstrukturierten Textdaten in strukturierte Tabellendaten umgewandelt werden. Zur Vervollständigung der Parsing-Aktivität wird die Python-Sprache verwendet, um die Programmcodes zu ändern.
Was ist Textanalyse?
Das Analysieren von Text bedeutet einfach das Konvertieren der Daten von einem Format in ein anderes Format. Das Format, in dem die Datei gespeichert wird, muss geparst oder in eine Datei in einem anderen Format konvertiert werden, damit der Benutzer sie in verschiedenen Anwendungen verwenden kann.
- Mit anderen Worten bedeutet der Prozess, die Zeichenkette oder einen Text zu analysieren und in logische Komponenten umzuwandeln, indem das Format der Datei geändert wird.
- Einige Regeln der Python-Sprache werden verwendet, um diese allgemeine Programmieraufgabe abzuschließen. Beim Analysieren von Text wird die gegebene Textreihe in kleinere Komponenten zerlegt.
Was sind die Gründe, Text zu parsen?
Die Gründe, aus denen der Text geparst werden muss, werden in diesem Abschnitt angegeben, und es ist eine Grundvoraussetzung, bevor Sie wissen, wie Text geparst wird.
- Alle computerisierten Daten haben nicht das gleiche Format und können je nach Anwendung unterschiedlich sein.
- Die Datenformate variieren für verschiedene Anwendungen und ein inkompatibler Code würde zu diesem Fehler führen.
- Es gibt kein individuelles universelles Computerprogramm zum Auswählen der Daten aller Datenformate.
Methode 1: Durch DataFrame-Klasse
Die DataFrame-Klasse der Python-Sprache verfügt über alle erforderlichen Funktionen zum Analysieren von Text. Diese eingebaute Bibliothek enthält die notwendigen Codes, um Daten eines beliebigen Formats in ein anderes Format zu parsen.
Kurze Einführung in die DataFrame-Klasse
Die DataFrame-Klasse ist eine funktionsreiche Datenstruktur, die als Datenanalysetool verwendet wird. Dies ist ein leistungsstarkes Datenanalysetool, mit dem Daten mit minimalem Aufwand analysiert werden können.
- Der Code wird in den pandas DataFrame eingelesen, um die Analyse in der Python-Sprache durchzuführen.
- Die Klasse enthält zahlreiche von den Pandas bereitgestellte Pakete, die von Python-Datenanalysten verwendet werden.
- Das Merkmal dieser Klasse ist eine Abstraktion, ein Code, in dem die interne Funktionalität der Funktion vor den Benutzern der NumPy-Bibliothek verborgen ist. Die NumPy-Bibliothek ist eine Python-Bibliothek, die die Befehle und Funktionen zum Arbeiten mit Arrays umfasst.
- Die DataFrame-Klasse kann verwendet werden, um ein zweidimensionales Array mit mehreren Zeilen- und Spaltenindizes zu rendern. Diese Indizes helfen beim Speichern mehrdimensionaler Daten und werden daher MultiIndex genannt. Diese müssen geändert werden, um zu wissen, wie Parsing-Fehler behoben werden können.
Die Pandas der Python-Sprache helfen bei der Durchführung von SQL- oder Datenbankoperationen mit höchster Perfektion, um Fehler beim Analysieren von Text x zu vermeiden. Es enthält auch einige IO-Tools, die bei der Analyse der Dateien von CSV, MS Excel, JSON, HDF5 und anderen Datenformaten helfen.
Prozess zum Analysieren von Text mithilfe der DataFrame-Klasse
Um zu wissen, wie Text analysiert wird, können Sie den Standardprozess mit der in diesem Abschnitt angegebenen DataFrame-Klasse verwenden.
- Entschlüsseln Sie das Datenformat der Eingabedaten.
- Legen Sie die Ausgabedaten der Daten wie CSV oder Comma Separated Value fest.
- Schreiben Sie in den Code einen primitiven Datentyp wie list oder dict.
Hinweis: Das Schreiben des Codes in einen leeren DataFrame kann mühsam und komplex sein. Die Pandas ermöglichen das Erstellen der Daten in der DataFrame-Klasse aus diesen Datentypen. Daher können die Daten im primitiven Datentyp leicht in das erforderliche Datenformat geparst werden.
- Analysieren Sie die Daten mit dem Datenanalysetool Pandas DataFrame und drucken Sie das Ergebnis aus.
Option I: Standardformat
Die Standardmethode zum Formatieren einer beliebigen Datei mit einem bestimmten Datenformat wie CSV wird hier erläutert.
- Speichern Sie die Datei mit den Datenwerten lokal auf Ihrem PC. Sie können die Datei beispielsweise data.txt nennen.
- Importieren Sie die Datei in Pandas mit einem bestimmten Namen und importieren Sie die Daten in eine andere Variable. Beispielsweise werden die Pandas der Sprache in den Namen pd im angegebenen Code importiert.
- Der Import sollte einen vollständigen Code mit Angabe des Namens der Eingabedatei, der Funktion und des Formats der Eingabedatei enthalten.
Hinweis: Hier wird die Variable namens res verwendet, um die Lesefunktion der Daten in der Datei data.txt unter Verwendung der in pd importierten Pandas auszuführen. Das Datenformat des Eingabetextes wird im CSV-Format angegeben.
- Rufen Sie den benannten Dateityp auf und analysieren Sie den geparsten Text auf dem gedruckten Ergebnis. Beispielsweise hilft der Befehl res nach der Befehlszeilenausführung beim Drucken des analysierten Textes.
Ein Beispielcode für den oben erläuterten Prozess ist unten angegeben und hilft beim Verständnis, wie Text analysiert wird.
import pandas as pd res = pd.read_csv(‘data.txt’) res
Wenn Sie in diesem Fall die Datenwerte in die Datei data.txt eingeben, wie z [1,2,3]würde es analysiert und als 1 2 3 angezeigt.
Option II: String-Methode
Wenn der an den Code übergebene Text nur Zeichenfolgen oder Alphazeichen enthält, können die Sonderzeichen in der Zeichenfolge wie Kommas, Leerzeichen usw. verwendet werden, um den Text zu trennen und zu analysieren. Der Prozess ähnelt den üblichen internen Zeichenfolgenoperationen. Um herauszufinden, wie Sie den Parsing-Fehler beheben können, müssen Sie den Prozess des Parsings des Textes mit dieser Option befolgen, der unten erklärt wird.
- Die Daten werden aus dem String extrahiert und alle Sonderzeichen, die den Text trennen, notiert.
Beispielsweise werden in dem unten angegebenen Code die Sonderzeichen in der Zeichenfolge my_string, die „,“ und „:“ sind, identifiziert. Dieser Prozess muss sorgfältig durchgeführt werden, um Fehler im Analysetext x zu vermeiden.
- Der Text im String wird individuell anhand der Werte und der Position der Sonderzeichen aufgeteilt.
Beispielsweise wird die Zeichenkette in Textdatenwerte aufgeteilt, basierend auf den Sonderzeichen, die mit dem Split-Befehl identifiziert wurden.
- Die Datenwerte der Zeichenfolge werden allein als geparster Text ausgegeben. Hier wird die print-Anweisung verwendet, um den geparsten Datenwert des Textes zu drucken.
Der Beispielcode für den oben erläuterten Prozess ist unten angegeben.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
In diesem Fall würde das Ergebnis der geparsten Zeichenfolge wie unten gezeigt angezeigt.
Names: [‘Tech’, ‘computer’]
Um eine bessere Übersichtlichkeit zu erhalten und um zu wissen, wie Text analysiert wird, während die Zeichenfolge text verwendet wird, wird eine for-Schleife verwendet und der Code wie folgt geändert.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
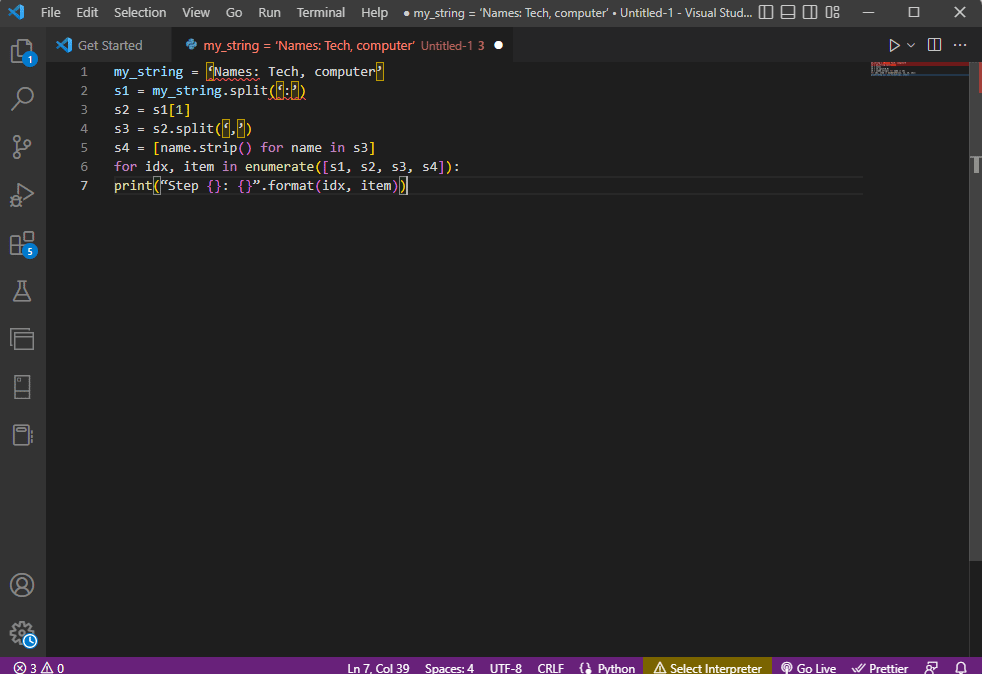
Das Ergebnis des geparsten Textes für jeden dieser Schritte wird wie unten angegeben angezeigt. Sie können feststellen, dass in Schritt 0 die Zeichenfolge basierend auf dem Sonderzeichen : getrennt wird und die Textdatenwerte basierend auf dem Zeichen in weiteren Schritten getrennt werden.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Option III: Analyse komplexer Dateien
In den meisten Fällen enthalten die zu parsenden Dateidaten unterschiedliche Datentypen und Datenwerte. In diesem Fall kann es schwierig sein, die Datei mit den zuvor erläuterten Methoden zu parsen.
Die Funktionen zum Analysieren der komplexen Daten in der Datei bestehen darin, dass die Datenwerte in einem tabellarischen Format angezeigt werden.
- Der Titel oder die Metadaten der Werte werden oben in der Datei gedruckt,
- Die Variablen und Felder werden in tabellarischer Form und in der Ausgabe ausgegeben
- Die Datenwerte bilden einen zusammengesetzten Schlüssel.
Bevor Sie lernen, wie Text mit dieser Methode analysiert wird, müssen Sie einige grundlegende Konzepte lernen. Das Parsen der Datenwerte erfolgt auf Basis von regulären Ausdrücken oder Regex.
Regex-Muster
Um zu wissen, wie Parsing-Fehler behoben werden können, müssen Sie sicherstellen, dass die Regex-Muster in den Ausdrücken korrekt sind. Der Code zum Analysieren der Datenwerte der Zeichenfolgen würde die allgemeinen Regex-Muster umfassen, die unten in diesem Abschnitt aufgeführt sind.
-
‚d‘ : stimmt mit der Dezimalziffer in der Zeichenfolge überein,
-
’s‘ : entspricht dem Leerzeichen,
-
‚w‘: entspricht dem alphanumerischen Zeichen,
-
‚+‘ oder ‚*‘ : führt eine Greedy-Übereinstimmung durch, indem ein oder mehrere Zeichen in den Zeichenfolgen abgeglichen werden,
-
‚a-z‘ : entspricht den Kleinbuchstabengruppen in den Textdatenwerten,
-
‚A-Z‘ oder ‚a-z‘ : Entspricht den Groß- und Kleinbuchstabengruppen der Zeichenfolge und
-
‚0-9‘ : entspricht den Zahlenwerten.
Reguläre Ausdrücke
Reguläre Ausdrucksmodule sind ein wichtiger Teil des Pandas-Pakets in der Python-Sprache, und ein falscher Ausdruck kann zu einem Fehler im Parse-Text x führen. Es ist eine winzige Sprache, die in Python eingebettet ist, um das Zeichenfolgenmuster im Ausdruck zu finden. Reguläre Ausdrücke oder Regex sind Zeichenketten mit spezieller Syntax. Es ermöglicht dem Benutzer, Muster in anderen Zeichenfolgen basierend auf den Werten in den Zeichenfolgen abzugleichen.
Die Regex wird basierend auf dem Datentyp und der Anforderung des Ausdrucks in der Zeichenfolge erstellt, z. B. „String = (.*)n. Die Regex wird in jedem Ausdruck vor dem Muster verwendet. Die in den regulären Ausdrücken verwendeten Symbole sind unten aufgeführt und helfen dabei, zu wissen, wie Text analysiert wird.
-
. : um ein beliebiges Zeichen aus den Daten abzurufen,
-
* : Verwenden Sie null oder mehr Daten aus dem vorherigen Ausdruck,
-
(.*) : um einen Teil des regulären Ausdrucks innerhalb der Klammern zu gruppieren,
-
n : Erstellen Sie ein neues Zeilenzeichen am Ende der Zeile im Code,
-
d : Erstellen Sie einen kurzen ganzzahligen Wert im Bereich von 0 bis 9,
-
+ : Verwenden Sie ein oder mehrere Daten aus dem vorherigen Ausdruck, und
-
| : Erstellen Sie eine logische Aussage; verwendet für oder Ausdrücke.
RegexObjects
Das RegexObject ist ein Rückgabewert für die Kompilierungsfunktion und wird verwendet, um ein MatchObject zurückzugeben, wenn der Ausdruck mit dem Übereinstimmungswert übereinstimmt.
1. MatchObject
Da der boolesche Wert des MatchObject immer True ist, können Sie eine if-Anweisung verwenden, um die positiven Übereinstimmungen im Objekt zu identifizieren. Bei Verwendung der if-Anweisung wird die Gruppe, auf die der Index verweist, verwendet, um die Übereinstimmung des Objekts im Ausdruck herauszufinden.
-
group() gibt eine oder mehrere Untergruppen der Übereinstimmung zurück,
-
group(0) gibt die gesamte Übereinstimmung zurück,
-
group(1) gibt die erste eingeklammerte Untergruppe zurück, und
- Während wir uns auf mehrere Gruppen beziehen, sollten wir eine Python-spezifische Erweiterung verwenden. Diese Erweiterung wird verwendet, um den Namen der Gruppe anzugeben, in der die Übereinstimmung gefunden werden muss. Die spezifische Erweiterung wird innerhalb der Gruppe in Klammern bereitgestellt. Der Ausdruck (?P
regex1) würde sich beispielsweise auf die spezifische Gruppe mit dem Namen group1 beziehen und auf Übereinstimmung im regulären Ausdruck regex1 prüfen. Um zu lernen, wie man Parsing-Fehler behebt, müssen Sie überprüfen, ob die Gruppe richtig ausgerichtet ist.
2. Methoden von MatchObject
Beim Analysieren von Text ist es wichtig zu wissen, dass das MatchObject zwei grundlegende Methoden hat, die unten aufgeführt sind. Wenn das MatchObject im angegebenen Ausdruck gefunden wird, würde es seine Instanz zurückgeben, andernfalls würde es None zurückgeben.
- Die match(string)-Methode wird verwendet, um die Übereinstimmungen der Zeichenfolge am Anfang des regulären Ausdrucks zu finden, und
- Die search(string)-Methode wird verwendet, um die Zeichenfolge zu durchsuchen, um die Position für eine Übereinstimmung im regulären Ausdruck zu finden.
Reguläre Ausdrucksfunktionen
Regex-Funktionen sind Codezeilen, die verwendet werden, um eine bestimmte Funktion auszuführen, die vom Benutzer aus der Menge der beschafften Datenwerte angegeben wird.
Hinweis: Um die Funktionen zu schreiben, werden Rohzeichenfolgen für die regulären Ausdrücke verwendet, um Fehler im Analysetext x zu vermeiden. Dies geschieht durch Hinzufügen des Index r vor jedem Muster im Ausdruck.
Die in den Ausdrücken verwendeten gemeinsamen Funktionen werden unten erklärt.
1. re.findall()
Diese Funktion gibt alle Muster in der Zeichenfolge zurück, wenn eine Übereinstimmung gefunden wird, und gibt eine leere Liste zurück, wenn keine Übereinstimmung gefunden wird. Zum Beispiel die Funktion string = re.findall(‚[aeiou]‘, regex_filename) wird verwendet, um das Vokalvorkommen im Dateinamen zu finden.
2. re.split()
Diese Funktion wird verwendet, um die Zeichenkette aufzuteilen, falls eine Übereinstimmung mit einem angegebenen Zeichen, wie z. B. einem Leerzeichen, gefunden wird. Falls keine Übereinstimmung gefunden wird, wird eine leere Zeichenfolge zurückgegeben.
3. re.sub()
Die Funktion ersetzt den übereinstimmenden Text durch den Inhalt der angegebenen Ersetzungsvariablen. Im Gegensatz zu anderen Funktionen wird, wenn kein Muster gefunden wird, der ursprüngliche String zurückgegeben.
4. re.search()
Eine der grundlegenden Funktionen, die beim Erlernen des Parsens von Text helfen, ist die Suchfunktion. Es hilft beim Suchen des Musters in der Zeichenfolge und beim Zurückgeben des Übereinstimmungsobjekts. Wenn die Suche die Übereinstimmung nicht identifiziert, wird kein Wert zurückgegeben.
5. neu kompilieren (Muster)
Diese Funktion wird verwendet, um reguläre Ausdrucksmuster in ein RegexObject zu kompilieren, das bereits besprochen wurde.
Andere Vorraussetzungen
Die aufgeführten Anforderungen sind ein zusätzliches Merkmal, das von fortgeschrittenen Programmierern bei der Datenanalyse verwendet wird.
- Zur Visualisierung des regulären Ausdrucks wird regexper verwendet, und
- Um den regulären Ausdruck zu testen, wird regex101 verwendet.
Prozess der Textanalyse
Die Methode zum Analysieren des Textes in dieser komplexen Option wird unten beschrieben.
- Der wichtigste Schritt besteht darin, das Eingabeformat zu verstehen, indem der Inhalt der Datei gelesen wird. Beispielsweise werden die Funktionen with open und read() verwendet, um den Inhalt der Datei namens sample zu öffnen und zu lesen. Die Beispieldatei hat den Inhalt aus der Datei file.txt; Um zu erfahren, wie der Parsing-Fehler behoben wird, muss die Datei vollständig gelesen werden.
- Der Inhalt der Datei wird gedruckt, um die Daten manuell zu analysieren und die Metadaten der Werte herauszufinden. Hier wird die Funktion print() verwendet, um den Inhalt der Beispieldatei zu drucken.
- Die erforderlichen Datenpakete zum Parsen des Textes werden in den Code importiert und der Klasse wird ein Name für die weitere Codierung gegeben. Hier werden die regulären Ausdrücke und Pandas importiert.
- Die für den Code erforderlichen regulären Ausdrücke werden in der Datei definiert, indem das Regex-Muster und die Regex-Funktion eingeschlossen werden. Dadurch kann das Textobjekt oder der Korpus den Code für die Datenanalyse übernehmen.
- Um zu erfahren, wie Text analysiert wird, können Sie sich auf den hier angegebenen Beispielcode beziehen. Die Funktion compile() wird verwendet, um den String aus der Gruppe stringname1 der Datei filename zu kompilieren. Die Funktion zum Prüfen auf Übereinstimmungen in der Regex wird vom Befehl ief_parse_line(line) verwendet.
- Der Zeilenparser für den Code wird unter Verwendung von def_parse_file(filepath) geschrieben, in dem die definierte Funktion nach allen Regex-Übereinstimmungen in der angegebenen Funktion sucht. Hier sucht die Methode regex search() nach dem Schlüssel rx in der Datei filename und gibt den Schlüssel und die Übereinstimmung der ersten passenden Regex zurück. Jedes Problem mit dem Schritt kann zu einem Fehler beim Analysieren von Text x führen.
- Der nächste Schritt besteht darin, einen Dateiparser mit der Dateiparserfunktion zu schreiben, die def_parse_file(filepath) ist. Eine leere Liste wird erstellt, um die Daten des Codes zu sammeln, als data = []wird die Übereinstimmung in jeder Zeile durch match = _parse_line(line) überprüft, und die genauen Wertdaten werden basierend auf dem Datentyp zurückgegeben.
- Um die Nummer und den Wert für die Tabelle zu extrahieren, wird der Befehl line.strip().split(‚,‘) verwendet. Der Befehl row{} wird verwendet, um ein Wörterbuch mit der Datenzeile zu erstellen. Der Befehl data.append(row) wird verwendet, um die Daten zu verstehen und in ein tabellarisches Format zu parsen.
Der Befehl data = pd.DataFrame(data) wird verwendet, um einen pandas DataFrame aus den dict-Werten zu erstellen. Alternativ können Sie die folgenden Befehle für den jeweiligen Zweck wie unten angegeben verwenden.
-
data.set_index([‘string’, ‘integer’]inplace=True), um den Index der Tabelle festzulegen.
-
data = data.groupby(level=data.index.names).first() zum Konsolidieren und Entfernen von nans.
-
data = data.apply(pd.to_numeric, errors=’ignore‘), um den Score von Float auf Integer-Wert zu aktualisieren.
Der letzte Schritt, um zu wissen, wie Text geparst wird, besteht darin, den Parser mit der if-Anweisung zu testen, indem die Werte einer Variablen data zugewiesen und mit dem Befehl print(data) gedruckt werden.
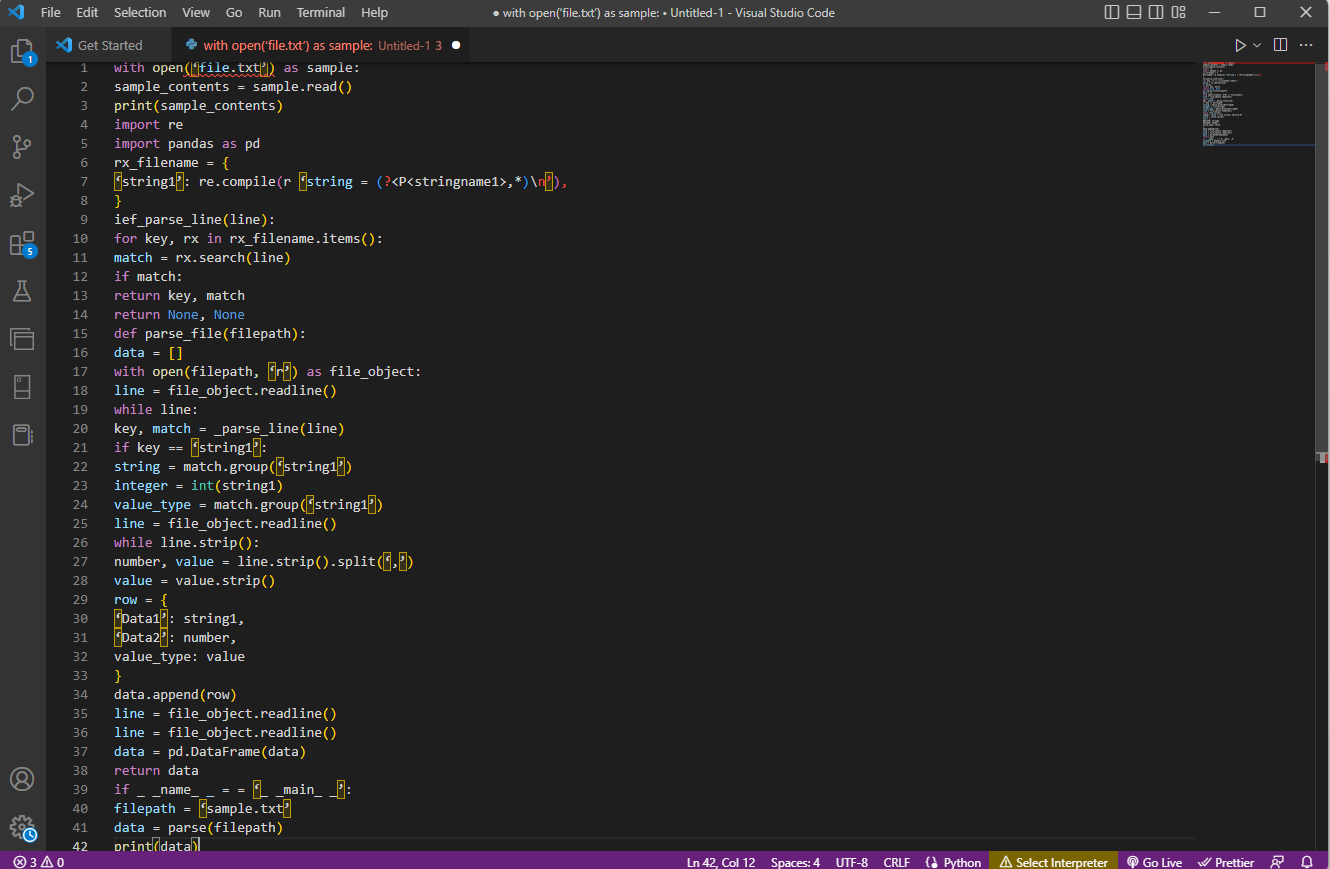
Der Beispielcode für die obige Erklärung ist hier angegeben.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Methode 2: Durch Wort-Tokenisierung
Der Prozess der Umwandlung eines Textes oder Korpus in Token oder kleinere Stücke basierend auf bestimmten Regeln wird als Tokenisierung bezeichnet. Um zu erfahren, wie Parsing-Fehler behoben werden können, ist es wichtig, die Wort-Tokenisierungsbefehle im Code zu analysieren. Ähnlich wie bei der Regex können bei dieser Methode eigene Regeln erstellt werden und sie hilft bei Textvorverarbeitungsaufgaben wie der Abbildung von Wortarten. Außerdem werden bei dieser Methode Aktivitäten wie das Finden und Abgleichen gebräuchlicher Wörter, das Bereinigen von Text und das Vorbereiten der Daten für fortgeschrittene Textanalysetechniken wie die Stimmungsanalyse durchgeführt. Wenn die Tokenisierung nicht korrekt ist, kann ein Fehler im Analysetext x auftreten.
Ntlk-Bibliothek
Der Prozess nutzt die Hilfe der beliebten Sprach-Toolkit-Bibliothek namens nltk, die über eine Vielzahl von Funktionen zum Ausführen vieler NLP-Jobs verfügt. Diese können über die Pip- oder Pip-Installationspakete heruntergeladen werden. Um zu wissen, wie man Text analysiert, können Sie das Basispaket der Anaconda-Distribution verwenden, das die Bibliothek standardmäßig enthält.
Formen der Tokenisierung
Die üblichen Formen dieser Methode sind Wort-Tokenisierung und Satz-Tokenisierung. Aufgrund des Tokens auf Wortebene druckt ersteres ein Wort nur einmal, während letzteres das Wort auf Satzebene druckt.
Prozess der Textanalyse
- Die ntlk-Toolkit-Bibliothek wird importiert und die Tokenisierungsformulare werden aus der Bibliothek importiert.
- Eine Zeichenfolge wird angegeben und die Befehle zum Ausführen der Tokenisierung werden angegeben.
- Während die Zeichenfolge gedruckt wird, lautet die Ausgabe Computer ist das Wort.
- Bei Wort-Tokenisierung oder word_tokenize() wird jedes Wort im Satz einzeln innerhalb des “ gedruckt und durch ein Komma getrennt. Die Ausgabe für den Befehl wäre ‚computer‘, ‚is‘, ‚the‘, ‚word‘, ‚.‘
- Bei der Satz-Tokenisierung oder sent_tokenize() werden die einzelnen Sätze innerhalb des “ gestellt und die Wortwiederholung erlaubt. Die Ausgabe für den Befehl wäre „Computer ist das Wort“.
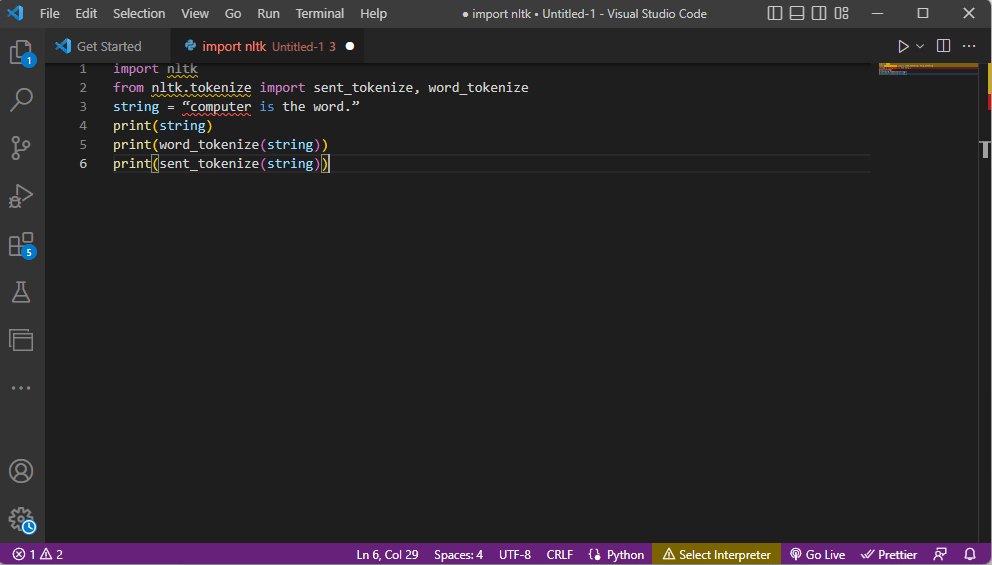
Der Code, der die obigen Schritte zur Tokenisierung erklärt, ist hier angegeben.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Methode 3: Durch die DocParser-Klasse
Ähnlich wie die DataFrame-Klasse kann die Klasse DocParser verwendet werden, um den Text im Code zu analysieren. Die Klasse ermöglicht es Ihnen, die Parse-Funktion mit dem Dateipfad aufzurufen.
Prozess der Textanalyse
Um zu erfahren, wie Text mit der DocParser-Klasse analysiert wird, befolgen Sie die nachstehenden Anweisungen.
- Die Funktion get_format(filename) wird verwendet, um die Dateierweiterung zu extrahieren, sie an eine festgelegte Variable für die Funktion zurückzugeben und sie an die nächste Funktion zu übergeben. Beispielsweise würde p1 = get_format(filename) die Dateierweiterung von filename extrahieren, auf die Variable p1 setzen und an die nächste Funktion übergeben.
- Eine logische Struktur mit anderen Funktionen wird unter Verwendung der if-elif-else-Anweisungen und -Funktionen aufgebaut.
- Wenn die Dateierweiterung gültig und die Struktur logisch ist, wird die get_parser-Funktion verwendet, um die Daten im Dateipfad zu parsen und das Zeichenfolgenobjekt an den Benutzer zurückzugeben.
Hinweis: Um zu wissen, wie Parsing-Fehler behoben werden können, muss diese Funktion korrekt implementiert werden.
- Das Parsen der Datenwerte erfolgt mit der Dateiendung der Datei. Die konkrete Implementierung der Klasse, nämlich parse_txt oder parse_docx, wird verwendet, um String-Objekte aus den Teilen des angegebenen Dateityps zu generieren.
- Das Parsen kann für Dateien mit anderen lesbaren Erweiterungen wie parse_pdf, parse_html und parse_pptx durchgeführt werden.
- Die Datenwerte und die Schnittstelle können mit Importanweisungen in Anwendungen importiert werden und ein DocParser-Objekt instanziieren. Dies kann durch Analysieren von Dateien in der Python-Sprache erfolgen, z. B. parse_file.py. Diese Operation muss sorgfältig durchgeführt werden, um Fehler beim Analysieren von Text x zu vermeiden.
Methode 4: Durch das Textanalyse-Tool
Das Werkzeug „Text analysieren“ wird verwendet, um bestimmte Daten aus Variablen zu extrahieren und sie anderen Variablen zuzuordnen. Dies ist unabhängig von anderen Tools, die in einer Aufgabe verwendet werden, und das BPA-Plattform-Tool wird verwendet, um Variablen zu konsumieren und auszugeben. Verwenden Sie den hier angegebenen Link, um darauf zuzugreifen Textanalyse-Tool online und verwenden Sie die zuvor gegebenen Antworten zum Analysieren von Text.
Methode 5: Durch TextFieldParser (Visual Basic)
Der TextFieldParser verwendete Objekte zum Analysieren und Verarbeiten sehr großer Dateien, die strukturiert und getrennt sind. Bei dieser Methode können die Breite und Spalte von Text wie Protokolldateien oder ältere Datenbankinformationen verwendet werden. Die Parsing-Methode ähnelt der Iteration des Codes über eine Textdatei und wird hauptsächlich zum Extrahieren von Textfeldern verwendet, die den Verfahren zur Bearbeitung von Zeichenfolgen ähneln. Dies geschieht, um begrenzte Zeichenfolgen und Felder unterschiedlicher Breite unter Verwendung des definierten Trennzeichens wie Komma oder Tabulatorzeichen zu tokenisieren.
Funktionen zum Analysieren von Text
Die folgenden Funktionen können verwendet werden, um den Text in dieser Methode zu analysieren.
- Um ein Trennzeichen zu definieren, wird SetDelimiters verwendet. Beispielsweise wird der Befehl testReader.SetDelimiters (vbTab) verwendet, um den Tabulator als Trennzeichen festzulegen.
- Um eine Feldbreite auf einen positiven ganzzahligen Wert auf eine feste Feldbreite von Textdateien festzulegen, können Sie den Befehl testReader.SetFieldWidths (Integer) verwenden.
- Um den Feldtyp des Textes zu testen, können Sie den folgenden Befehl testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth verwenden.
Methoden zum Finden von MatchObject
Es gibt zwei grundlegende Methoden, um das MatchObject im Code oder im geparsten Text zu finden.
- Die erste Methode besteht darin, das Format zu definieren und die Datei mit der ReadFields-Methode zu durchlaufen. Diese Methode würde bei der Verarbeitung jeder Codezeile helfen.
- Mit der PeekChars-Methode wird jedes Feld vor dem Lesen einzeln geprüft, mehrere Formate definiert und reagiert.
In beiden Fällen wird eine MalformedLineException-Ausnahme zurückgegeben, wenn ein Feld nicht mit dem angegebenen Format übereinstimmt, während die Analyse durchgeführt wird oder ermittelt wird, wie Text analysiert wird.
Profi-Tipp: So analysieren Sie Text in MS Excel
Als letzte und einfache Methode zum Analysieren des Textes können Sie die verwenden MS-Excel app als Parser zum Erstellen von tabulatorgetrennten und kommagetrennten Dateien. Dies würde bei der Gegenprüfung mit Ihrem geparsten Ergebnis helfen und dabei helfen, herauszufinden, wie der Parsing-Fehler behoben werden kann.
1. Wählen Sie die Datenwerte in der Quelldatei aus und drücken Sie gleichzeitig die Tasten Strg + C, um die Datei zu kopieren.
2. Öffnen Sie die Excel-App über die Windows-Suchleiste.
3. Klicken Sie auf die Zelle A1 und drücken Sie gleichzeitig die Tasten Strg + V, um den kopierten Text einzufügen.
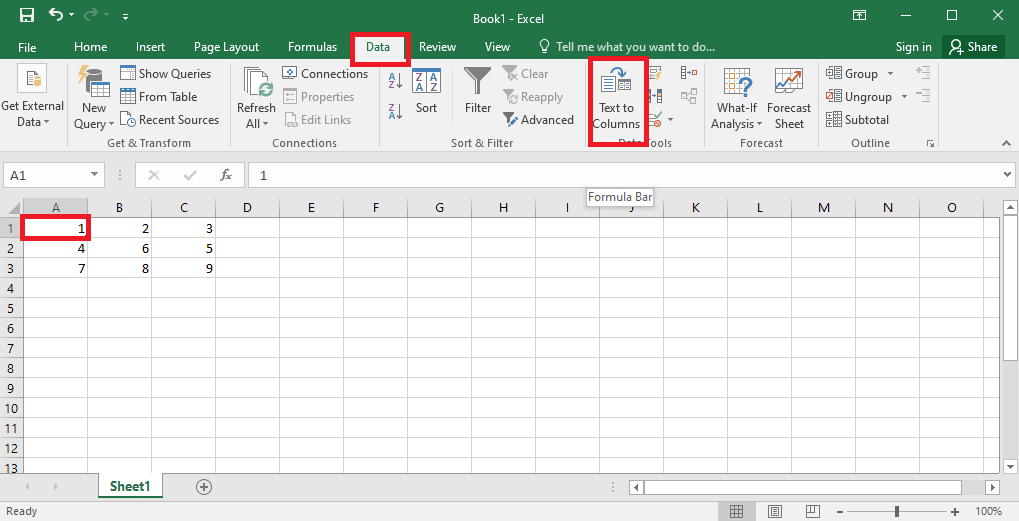
4. Wählen Sie die Zelle A1 aus, navigieren Sie zur Registerkarte Daten und klicken Sie im Abschnitt Datentools auf die Option Text in Spalten.
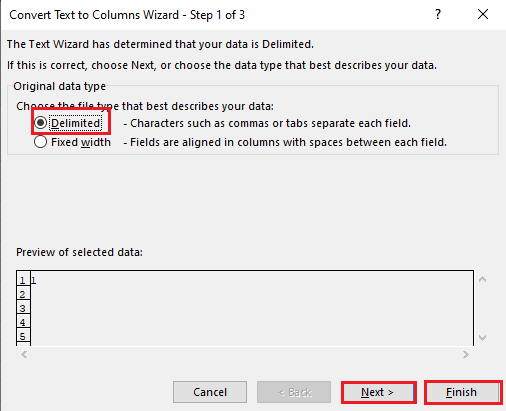
5A. Wählen Sie die Option „Getrennt“, wenn als Trennzeichen ein Komma oder Tabulatorzeichen verwendet wird, und klicken Sie auf die Schaltflächen „Weiter“ und „Fertig stellen“.
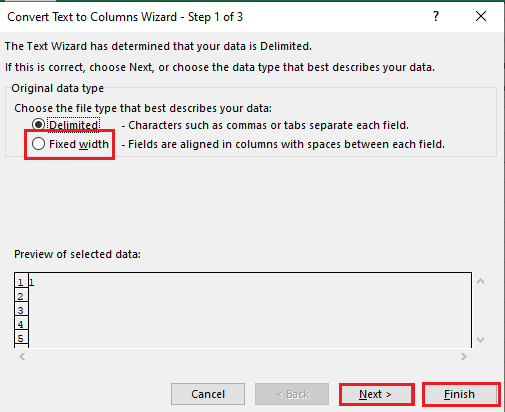
5B. Wählen Sie die Option Feste Breite, weisen Sie einen Wert für das Trennzeichen zu und klicken Sie auf die Schaltflächen Weiter und Fertig stellen.
So beheben Sie einen Parsing-Fehler
Fehler beim Analysieren von Text x kann auf Android-Geräten wie folgt auftreten: Parsing Error: Beim Parsing des Pakets ist ein Problem aufgetreten. Dies tritt normalerweise auf, wenn die App nicht aus dem Google Play Store installiert werden kann oder während eine Drittanbieter-App ausgeführt wird.
Der Fehlertext x kann auftreten, wenn die Liste der Zeichenvektoren geloopt wird und andere Funktionen ein lineares Modell zur Berechnung der Datenwerte bilden. Die Fehlermeldung lautet Error in parse(text = x, keep.source = FALSE):
Sie können den Artikel zur Behebung von Parsing-Fehlern auf Android lesen, um die Ursachen und Methoden zur Behebung des Fehlers zu erfahren.
Abgesehen von den Lösungen im Handbuch können Sie die folgenden Korrekturen ausprobieren.
- Erneutes Herunterladen der .apk-Datei oder Wiederherstellen des Namens der Datei.
- Wiederherstellen von Änderungen in der Datei Androidmanifest.xml, wenn Sie über Programmierkenntnisse auf Expertenebene verfügen.
***
Der Artikel hilft beim Lehren, wie man Text parst und wie man Parsing-Fehler behebt. Teilen Sie uns mit, welche Methode zur Behebung des Fehlers in Parsing-Text x beigetragen hat und welche Parsing-Methode bevorzugt wird. Bitte teilen Sie Ihre Vorschläge und Fragen im Kommentarbereich unten mit.