
Apache Kafka ist ein Nachrichten-Streaming-Dienst, der es verschiedenen Anwendungen in einem verteilten System ermöglicht, über Nachrichten zu kommunizieren und Daten auszutauschen.
Es fungiert als Pub/Subsystem, in dem Producer-Anwendungen Nachrichten veröffentlichen und Consumer-Systeme diese abonnieren.
Mit Apache Kafka können Sie eine lose gekoppelte Architektur zwischen den Teilen Ihres Systems übernehmen, die Daten produzieren und verbrauchen. Dies vereinfacht das Entwerfen und Verwalten des Systems. Kafka verlässt sich auf Zookeeper für die Verwaltung von Metadaten und die Synchronisierung verschiedener Elemente des Clusters.
Inhaltsverzeichnis
Funktionen von Apache Kafka
Apache Kafka ist unter anderem deshalb populär geworden, weil es so ist
- Skalierbar durch Cluster und Partitionen
- Schnell in der Lage, 2 Millionen Schreibvorgänge pro Sekunde auszuführen
- Behält die Reihenfolge bei, in der Nachrichten gesendet werden
- Zuverlässig durch sein Replikatsystem
- Es kann ohne Ausfallzeit aufgerüstet werden
Sehen wir uns nun einige der häufigsten Anwendungsfälle von Kafka an.
Häufige Anwendungsfälle von Apache Kafka
Kafka wird häufig bei der Verarbeitung von Big Data, der Aufzeichnung und Zusammenfassung von Ereignissen wie Schaltflächenklicks für Analysen und der Kombination von Protokollen aus verschiedenen Teilen eines Systems an einem zentralen Ort verwendet.
Es hilft bei der Ermöglichung der Kommunikation zwischen verschiedenen Anwendungen in einem System und der Echtzeitverarbeitung von Daten von IoT-Geräten.
Sehen wir uns nun die detaillierten Schritte zur Installation von Kafka unter Windows und Linux an.
Kafka unter Windows installieren
Überprüfen Sie zunächst, ob Java auf Ihrem Computer installiert ist, um Apache Kafka unter Windows zu installieren. Öffnen Sie die Eingabeaufforderung im Administratormodus und geben Sie den Befehl ein:
java --version
Wenn Java installiert ist, sollten Sie die aktuell installierte JDK-Versionsnummer erhalten.
Wenn Sie eine Fehlermeldung erhalten, dass der Befehl nicht erkannt wurde, wurde Java nicht installiert und Sie müssen Java installieren. Um Java zu installieren, gehen Sie zu Adoptium.net und klicken Sie auf den Download-Button.
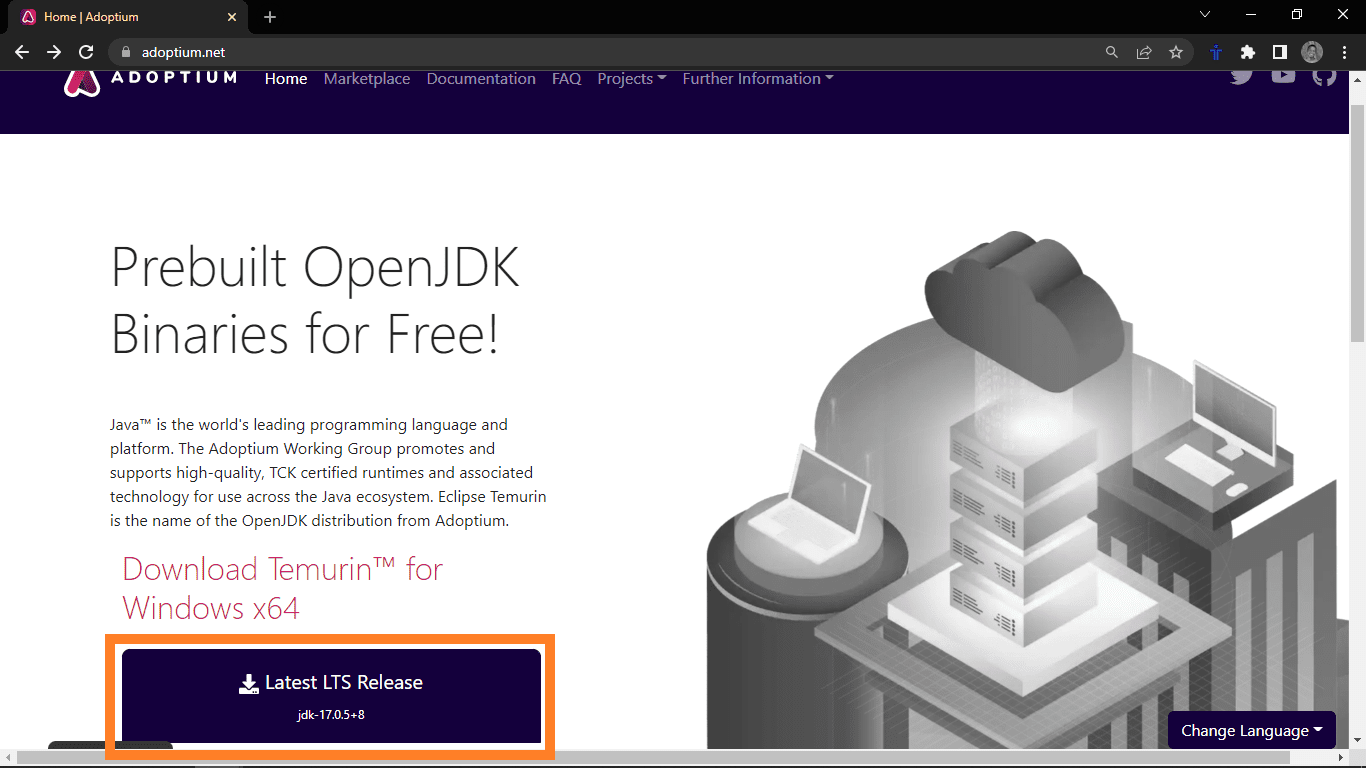
Dies sollte die Java-Installationsdatei herunterladen. Führen Sie nach Abschluss des Downloads das Installationsprogramm aus. Dies sollte die Installationsaufforderung öffnen.
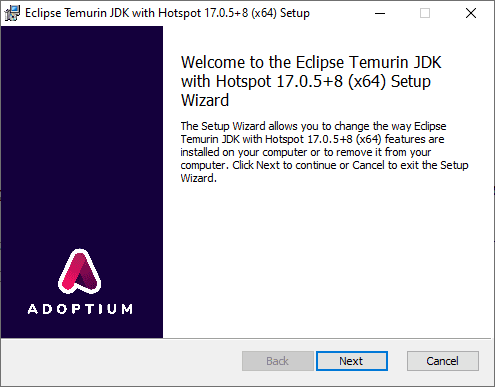
Drücken Sie wiederholt Weiter, um die Standardoptionen auszuwählen. Anschließend sollte die Installation beginnen. Überprüfen Sie die Installation, indem Sie die Eingabeaufforderung schließen, eine andere Eingabeaufforderung im Administratormodus erneut öffnen und den folgenden Befehl eingeben:
java --version
Dieses Mal sollten Sie die JDK-Version erhalten, die Sie gerade installiert haben. Nachdem die Installation abgeschlossen ist, können wir mit der Installation von Kafka beginnen.
Um Kafka zu installieren, gehen Sie zuerst auf die Kafka-Website.

Klicken Sie auf den Link und Sie sollten zur Download-Seite gelangen. Laden Sie die neuesten verfügbaren Binärdateien herunter.
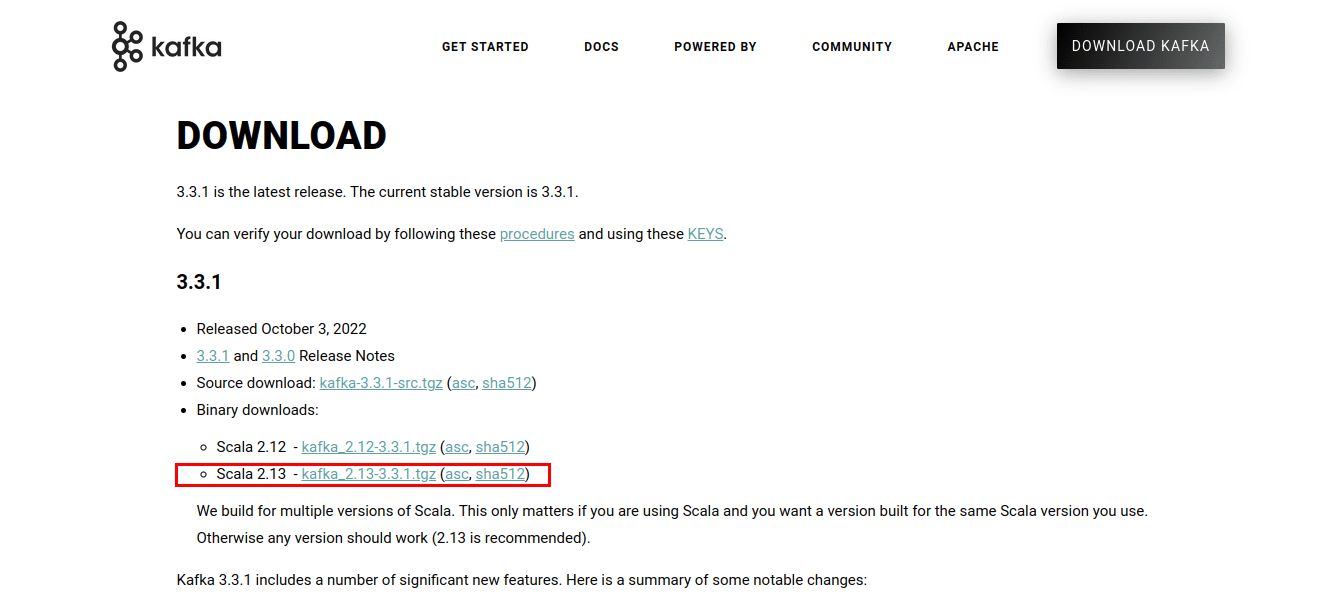
Dadurch werden Kafka-Skripte und Binärdateien heruntergeladen, die in einer .tgz-Datei verpackt sind. Nach dem Download müssen Sie die Dateien aus dem .tgz-Archiv extrahieren. Zum Extrahieren verwende ich WinZip, das von der WinZip-Website heruntergeladen werden kann.
Verschieben Sie die Datei nach dem Extrahieren nach C:, sodass der Dateipfad zu C:kafka wird
Öffnen Sie dann die Eingabeaufforderung im Administratormodus und starten Sie Zookeeper, indem Sie zuerst in das Kafka-Verzeichnis navigieren. Und führen Sie die Datei zookeeper-server-start.bat mit zookeeper.properties als Konfigurationsdatei aus
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
Wenn Zookeeper läuft, müssen wir die ausführbare wmic-Datei hinzufügen, die Kafka in unserem System PATH verwendet,
set PATH=C:WindowsSystem32wbem;%PATH%;
Starten Sie danach den Apache Kafka-Server, indem Sie eine weitere Eingabeaufforderungssitzung im Administratormodus öffnen und zum Ordner C:kafka navigieren
cd C:kafka
Starten Sie dann Kafka durch Ausführen
binwindowskafka-server-start.bat configserver.properties
Damit sollte Kafka laufen. Sie können Servereigenschaften anpassen, z. B. wo die Protokolle in die Datei server.properties geschrieben werden.
Kafka unter Linux installieren
Stellen Sie zunächst sicher, dass Ihr System auf dem neuesten Stand ist, indem Sie alle Pakete aktualisieren
sudo apt update && sudo apt upgrade
Überprüfen Sie als Nächstes, ob Java auf Ihrem Computer installiert ist, indem Sie es ausführen
java --version
Wenn Java installiert ist, sehen Sie die Versionsnummer. Ist dies jedoch nicht der Fall, können Sie es mit apt installieren.
sudo apt install default-jdk
Danach können wir Apache Kafka installieren, indem wir die Binärdateien von der Website herunterladen.
Öffnen Sie Ihr Terminal und navigieren Sie zu dem Ordner, in dem der Download gespeichert wurde. In meinem Fall muss ich zum Download-Ordner navigieren.
cd Downloads
Sobald Sie sich im Download-Ordner befinden, extrahieren Sie die heruntergeladenen Dateien mit tar:
tar -xvzf kafka_2.13-3.3.1.tgz
Navigieren Sie zum extrahierten Ordner
cd kafka_2.13-3.3.1.tgz
Listen Sie die Verzeichnisse und Dateien auf.
Sobald Sie sich im Ordner befinden, starten Sie einen Zookeeper-Server, indem Sie das Skript zookeeper-server-start.sh ausführen, das sich im bin-Verzeichnis des extrahierten Ordners befindet.
Das Skript erfordert eine Zookeeper-Konfigurationsdatei. Die Standarddatei heißt zookeeper.properties und befindet sich im Unterverzeichnis config.
Um den Server zu starten, verwenden Sie also den Befehl:
bin/zookeeper-server-start.sh config/zookeeper.properties
Wenn Zookeeper läuft, können wir den Apache Kafka-Server starten. Das Skript kafka-server-start.sh befindet sich ebenfalls im Verzeichnis bin. Der Befehl erwartet außerdem eine Konfigurationsdatei. Die Standardeinstellung ist server.properties, die in der Konfigurationsdatei gespeichert ist.
bin/kafka-server-start.sh config/server.properties
Dies sollte Apache Kafka zum Laufen bringen. Im bin-Verzeichnis finden Sie viele Skripte, mit denen Sie beispielsweise Themen erstellen, Producer verwalten und Consumer verwalten können. Sie können Servereigenschaften auch in der Datei server.properties anpassen.
Letzte Worte
In diesem Handbuch haben wir die Installation von Java und Apache Kafka beschrieben. Während Sie Kafka-Cluster manuell installieren und verwalten können, können Sie auch verwaltete Optionen wie Amazon Web Services und Confluent verwenden.
Als nächstes können Sie die Datenverarbeitung mit Kafka und Spark lernen.