
Wenn Sie Daten aus zwei Textdateien zusammenführen möchten, indem Sie ein gemeinsames Feld abgleichen, können Sie den Linux-Befehl Join verwenden. Es verleiht Ihren statischen Datendateien einen Hauch von Dynamik. Wir zeigen Ihnen, wie Sie es verwenden.
Inhaltsverzeichnis
Abgleichen von Daten in mehreren Dateien
Daten sind König. Konzerne, Unternehmen und Haushalte laufen gleichermaßen darauf. Aber Daten, die in verschiedenen Dateien gespeichert und von verschiedenen Personen zusammengestellt wurden, sind mühsam. Abgesehen davon, dass Sie wissen, welche Dateien geöffnet werden müssen, um die gewünschten Informationen zu finden, unterscheiden sich wahrscheinlich auch das Layout und das Format der Dateien.
Sie müssen sich auch mit administrativen Problemen auseinandersetzen, welche Dateien aktualisiert werden müssen, welche gesichert werden müssen, welche veraltet sind und welche archiviert werden können.
Wenn Sie Ihre Daten konsolidieren oder eine Analyse über einen gesamten Datensatz durchführen müssen, haben Sie außerdem ein zusätzliches Problem. Wie rationalisieren Sie die Daten in den verschiedenen Dateien, bevor Sie das Nötigste damit tun können? Wie gehen Sie die Datenaufbereitungsphase an?
Die gute Nachricht ist, dass der Linux-Befehl Join Sie aus dem Sumpf holen kann, wenn die Dateien mindestens ein gemeinsames Datenelement teilen.
Die Datendateien
Alle Daten, die wir verwenden, um die Verwendung des Join-Befehls zu demonstrieren, sind fiktiv, beginnend mit den folgenden beiden Dateien:
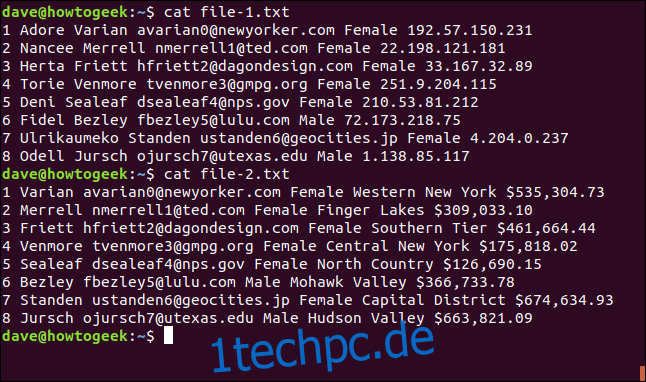
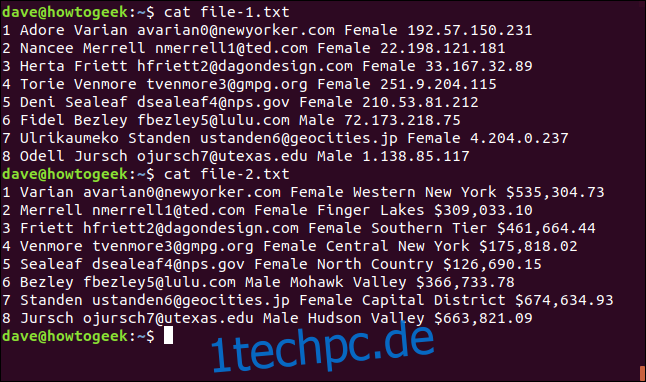
cat file-1.txt
cat file-2.txt
Das Folgende ist der Inhalt von file-1.txt:
1 Adore Varian [email protected] Female 192.57.150.231 2 Nancee Merrell [email protected] Female 22.198.121.181 3 Herta Friett [email protected] Female 33.167.32.89 4 Torie Venmore [email protected] Female 251.9.204.115 5 Deni Sealeaf [email protected] Female 210.53.81.212 6 Fidel Bezley [email protected] Male 72.173.218.75 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 8 Odell Jursch [email protected] Male 1.138.85.117
Wir haben eine Reihe von nummerierten Zeilen, und jede Zeile enthält alle folgenden Informationen:
Eine Zahl
Ein Vorname
Ein Familienname
Eine E-Mail Adresse
Das Geschlecht der Person
Eine IP-Adresse
Das Folgende ist der Inhalt von file-2.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93 8 Jursch [email protected] Male Hudson Valley $663,821.09
Jede Zeile in file-2.txt enthält die folgenden Informationen:
Eine Zahl
Ein Familienname
Eine E-Mail Adresse
Das Geschlecht der Person
Eine Region von New York
Ein Dollarwert
Der Join-Befehl arbeitet mit „Feldern“, was in diesem Zusammenhang einen von Leerzeichen umgebenen Textabschnitt, den Zeilenanfang oder das Zeilenende bedeutet. Damit Join Zeilen zwischen den beiden Dateien abgleicht, muss jede Zeile ein gemeinsames Feld enthalten.
Daher können wir ein Feld nur dann abgleichen, wenn es in beiden Dateien vorkommt. Die IP-Adresse kommt nur in einer Datei vor, das nützt also nichts. Der Vorname kommt nur in einer Datei vor, also können wir ihn auch nicht verwenden. Der Nachname ist in beiden Dateien enthalten, aber es wäre eine schlechte Wahl, da verschiedene Personen denselben Nachnamen haben.
Sie können die Daten auch nicht mit den männlichen und weiblichen Einträgen verknüpfen, da sie zu vage sind. Auch die Regionen New York und die Dollarwerte erscheinen nur in einer Datei.
Wir können die E-Mail-Adresse jedoch verwenden, da sie in beiden Dateien vorhanden ist und jede für eine Person einzigartig ist. Ein kurzer Blick durch die Dateien bestätigt auch, dass die Zeilen in jeder derselben Person entsprechen, sodass wir die Zeilennummern als unser Feld zum Abgleich verwenden können (wir werden später ein anderes Feld verwenden).
Beachten Sie, dass in den beiden Dateien eine unterschiedliche Anzahl von Feldern vorhanden ist, was in Ordnung ist – wir können Join aus jeder Datei mitteilen, welches Feld verwendet werden soll.
Achten Sie jedoch auf Felder wie die Regionen von New York; in einer durch Leerzeichen getrennten Datei sieht jedes Wort im Namen einer Region wie ein Feld aus. Da einige Regionen Namen aus zwei oder drei Wörtern haben, haben Sie tatsächlich eine unterschiedliche Anzahl von Feldern in derselben Datei. Dies ist in Ordnung, solange Sie bei Feldern übereinstimmen, die in der Zeile vor den New Yorker Regionen erscheinen.
Das Join-Kommando
Zuerst muss das zuzuordnende Feld sortiert werden. Wir haben in beiden Dateien aufsteigende Nummern, also erfüllen wir diese Kriterien. Standardmäßig verwendet Join das erste Feld in einer Datei, was wir wollen. Eine andere sinnvolle Vorgabe ist, dass Join erwartet, dass die Feldtrennzeichen Leerzeichen sind. Auch das haben wir, also können wir weitermachen und mitmachen.
Da wir alle Standardeinstellungen verwenden, ist unser Befehl einfach:
join file-1.txt file-2.txt
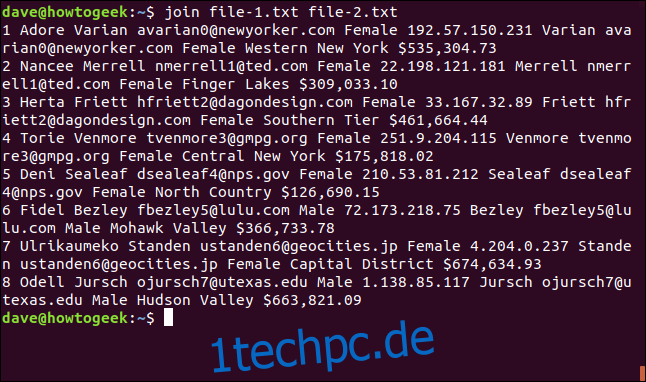
Join betrachtet die Dateien als „Datei eins“ und „Datei zwei“ entsprechend der Reihenfolge, in der sie in der Befehlszeile aufgelistet sind.
Die Ausgabe ist wie folgt:
1 Adore Varian [email protected] Female 192.57.150.231 Varian [email protected] Female Western New York $535,304.73 2 Nancee Merrell [email protected] Female 22.198.121.181 Merrell [email protected] Female Finger Lakes $309,033.10 3 Herta Friett [email protected] Female 33.167.32.89 Friett [email protected] Female Southern Tier $461,664.44 4 Torie Venmore [email protected] Female 251.9.204.115 Venmore [email protected] Female Central New York $175,818.02 5 Deni Sealeaf [email protected] Female 210.53.81.212 Sealeaf [email protected] Female North Country $126,690.15 6 Fidel Bezley [email protected] Male 72.173.218.75 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Ulrikaumeko Standen [email protected] Female 4.204.0.237 Standen [email protected] Female Capital District $674,634.93 8 Odell Jursch [email protected] Male 1.138.85.117 Jursch [email protected] Male Hudson Valley $663,821.09
Die Ausgabe wird folgendermaßen formatiert: Das Feld, auf das die Zeilen abgeglichen wurden, wird zuerst gedruckt, gefolgt von den anderen Feldern aus Datei eins und dann die Felder aus Datei zwei ohne das Match-Feld.
Unsortierte Felder
Versuchen wir etwas, von dem wir wissen, dass es nicht funktioniert. Wir werden die Zeilen in einer Datei nicht in der richtigen Reihenfolge platzieren, sodass Join die Datei nicht richtig verarbeiten kann. Der Inhalt von file-3.txt ist der gleiche wie file-2.txt, aber Zeile acht liegt zwischen den Zeilen fünf und sechs.
Das Folgende ist der Inhalt von file-3.txt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 8 Jursch [email protected] Male Hudson Valley $663,821.09 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Wir geben den folgenden Befehl ein, um zu versuchen, file-3.txtto file-1.txt zu verbinden:
join file-1.txt file-3.txt
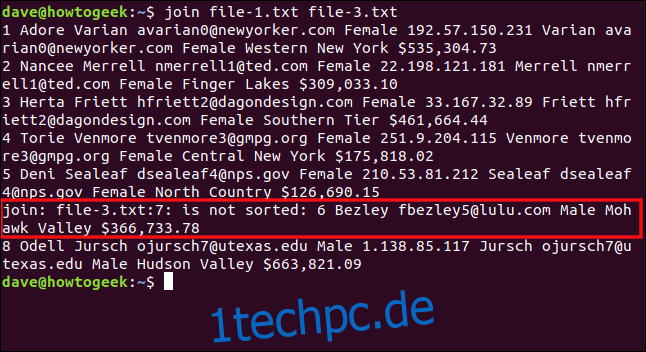
Join meldet, dass die siebte Zeile in file-3.txt nicht in Ordnung ist und daher nicht verarbeitet wird. Zeile sieben ist die, die mit der Zahl sechs beginnt, die in einer richtig sortierten Liste vor acht kommen sollte. Die sechste Zeile in der Datei (die mit „8 Odell“ beginnt) wurde zuletzt verarbeitet, daher sehen wir die Ausgabe dafür.
Sie können die Option –check-order verwenden, wenn Sie sehen möchten, ob Join mit der Sortierreihenfolge einer Datei zufrieden ist – es wird keine Zusammenführung versucht.
Dazu geben wir Folgendes ein:
join --check-order file-1.txt file-3.txt
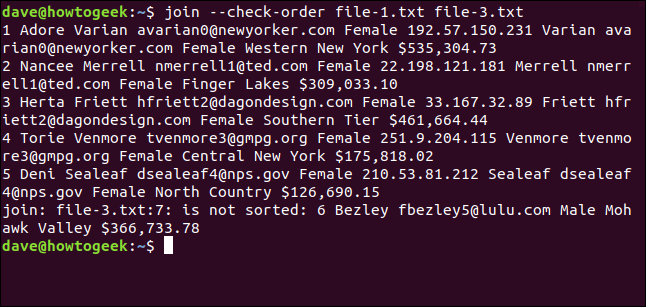
join sagt Ihnen im Voraus, dass es ein Problem mit Zeile sieben der Datei file-3.txt geben wird.
Dateien mit fehlenden Zeilen
In file-4.txt wurde die letzte Zeile entfernt, daher gibt es keine Zeile acht. Die Inhalte sind wie folgt:
1 Varian [email protected] Female Western New York $535,304.73 2 Merrell [email protected] Female Finger Lakes $309,033.10 3 Friett [email protected] Female Southern Tier $461,664.44 4 Venmore [email protected] Female Central New York $175,818.02 5 Sealeaf [email protected] Female North Country $126,690.15 6 Bezley [email protected] Male Mohawk Valley $366,733.78 7 Standen [email protected] Female Capital District $674,634.93
Wir geben Folgendes ein und überraschenderweise beschwert sich join nicht und verarbeitet alle Zeilen, die es kann:
join file-1.txt file-4.txt
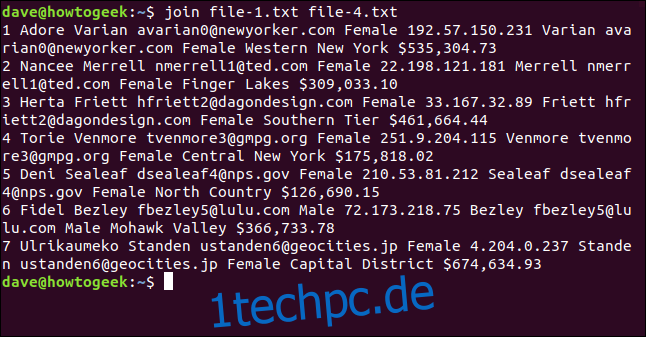
Die Ausgabe listet sieben zusammengeführte Zeilen auf.
Die Option -a (print unpairable) weist Join an, auch die Zeilen zu drucken, die nicht übereinstimmen konnten.
Hier geben wir den folgenden Befehl ein, um Join anzuweisen, die Zeilen aus Datei eins zu drucken, die nicht mit Zeilen in Datei zwei abgeglichen werden können:
join -a 1 file-1.txt file-4.txt
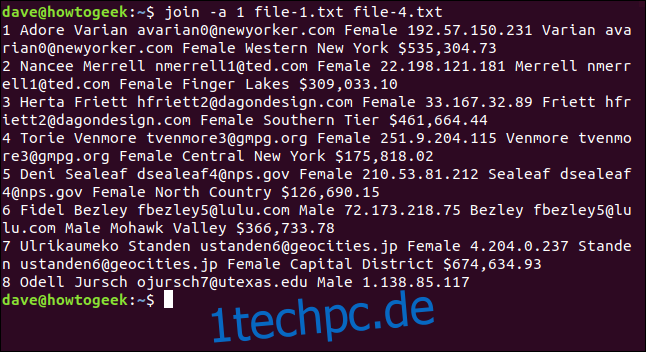
Sieben Zeilen werden abgeglichen und Zeile 8 von Datei 1 wird ohne Abgleich gedruckt. Es gibt keine zusammengeführten Informationen, da die Datei-4.txt keine Zeile 8 enthielt, mit der sie abgeglichen werden konnte. Es erscheint jedoch immer noch in der Ausgabe, sodass Sie wissen, dass es keine Übereinstimmung in file-4.txt gibt.
Wir geben den folgenden Befehl -v (verknüpfte Zeilen unterdrücken) ein, um alle Zeilen anzuzeigen, die keine Übereinstimmung aufweisen:
join -v file-1.txt file-4.txt

Wir sehen, dass Zeile acht die einzige ist, die keine Übereinstimmung in Datei zwei hat.
Abgleich mit anderen Feldern
Lassen Sie uns zwei neue Dateien in einem Feld zuordnen, das nicht das Standardfeld ist (Feld eins). Das Folgende ist der Inhalt der Datei-7.txt:
[email protected] Female 192.57.150.231 [email protected] Female 210.53.81.212 [email protected] Male 72.173.218.75 [email protected] Female 33.167.32.89 [email protected] Female 22.198.121.181 [email protected] Male 1.138.85.117 [email protected] Female 251.9.204.115 [email protected] Female 4.204.0.237
Und das Folgende ist der Inhalt von file-8.txt:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Das einzig sinnvolle Feld für den Beitritt ist die E-Mail-Adresse, das Feld eins in der ersten Datei und Feld zwei in der zweiten. Um dies zu berücksichtigen, können wir die Optionen -1 (Datei ein Feld) und -2 (Datei zwei Feld) verwenden. Wir folgen diesen mit einer Zahl, die angibt, welches Feld in jeder Datei zum Verbinden verwendet werden soll.
Wir geben Folgendes ein, um Join anzuweisen, das erste Feld in Datei eins und das zweite in Datei zwei zu verwenden:
join -1 1 -2 2 file-7.txt file-8.txt
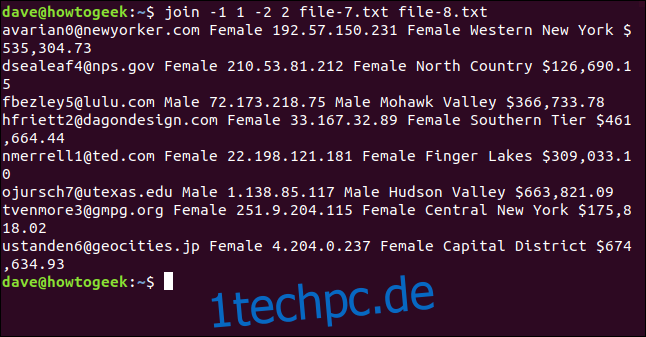
Die Dateien werden über die E-Mail-Adresse verbunden, die als erstes Feld jeder Zeile in der Ausgabe angezeigt wird.
Verwenden verschiedener Halbbildtrennzeichen
Was ist, wenn Sie Dateien mit Feldern haben, die durch etwas anderes als Leerzeichen getrennt sind?
Die folgenden beiden Dateien sind durch Kommas getrennt – der einzige Leerraum befindet sich zwischen den Ortsnamen, die aus mehreren Wörtern bestehen:
cat file-5.txt
cat file-6.txt
Wir können das -t (Trennzeichen) verwenden, um Join anzugeben, welches Zeichen als Feldtrennzeichen verwendet werden soll. In diesem Fall ist es das Komma, also geben wir den folgenden Befehl ein:
join -t, file-5.txt file-6.txt
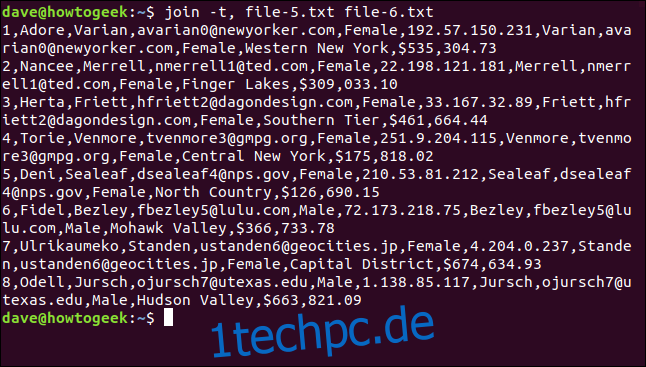
Alle Zeilen werden abgeglichen und die Leerzeichen in den Ortsnamen bleiben erhalten.
Groß-/Kleinschreibung ignorieren
Eine andere Datei, file-9.txt, ist fast identisch mit file-8.txt. Der einzige Unterschied besteht darin, dass einige der E-Mail-Adressen einen Großbuchstaben haben, wie unten gezeigt:
Female [email protected] Western New York $535,304.73 Female [email protected] North Country $126,690.15 Male [email protected] Mohawk Valley $366,733.78 Female [email protected] Southern Tier $461,664.44 Female [email protected] Finger Lakes $309,033.10 Male [email protected] Hudson Valley $663,821.09 Female [email protected] Central New York $175,818.02 Female [email protected] Capital District $674,634.93
Als wir file-7.txt und file-8.txt zusammengeführt haben, hat es perfekt funktioniert. Sehen wir uns an, was mit file-7.txt und file-9.txt passiert.
Wir geben folgenden Befehl ein:
join -1 1 -2 2 file-7.txt file-9.txt
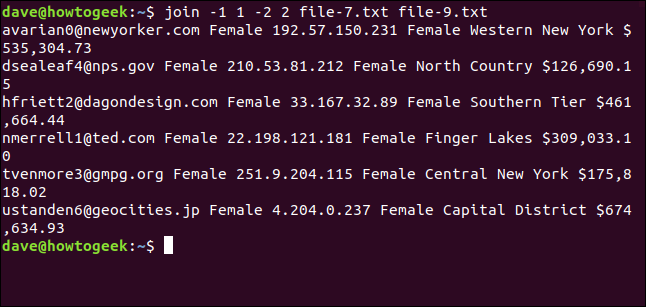
Wir haben nur sechs Zeilen gematcht. Die Unterschiede in Groß- und Kleinschreibung verhinderten, dass die beiden anderen E-Mail-Adressen zusammengeführt wurden.
Wir können jedoch die Option -i (Groß-/Kleinschreibung ignorieren) verwenden, um zu erzwingen, dass der Join diese Unterschiede ignoriert und Felder abgleicht, die denselben Text enthalten, unabhängig von der Groß-/Kleinschreibung.
Wir geben folgenden Befehl ein:
join -1 1 -2 2 -i file-7.txt file-9.txt
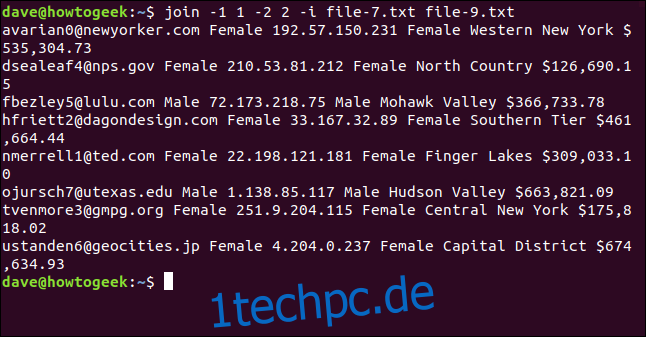
Alle acht Zeilen werden abgeglichen und erfolgreich verbunden.
Mischen und Anpassen
In Join haben Sie einen mächtigen Verbündeten, wenn Sie mit umständlicher Datenaufbereitung kämpfen. Vielleicht müssen Sie die Daten analysieren oder versuchen, sie in Form zu bringen, um einen Import in ein anderes System durchzuführen.
Egal wie die Situation ist, Sie werden froh sein, in Ihrer Ecke mitzumachen!