
Nun, Statistiken von Forbes besagen, dass bis zu 90 % der Organisationen weltweit Big Data-Analysen verwenden, um ihre Investitionsberichte zu erstellen.
Mit der zunehmenden Popularität von Big Data gibt es folglich einen Anstieg der Stellenangebote für Hadoop mehr als zuvor.
Um Ihnen dabei zu helfen, die Rolle eines Hadoop-Experten zu übernehmen, können Sie diese Interviewfragen und -antworten verwenden, die wir in diesem Artikel für Sie zusammengestellt haben, um Ihnen dabei zu helfen, Ihr Vorstellungsgespräch zu meistern.
Vielleicht motiviert Sie die Kenntnis der Fakten wie der Gehaltsspanne, die Hadoop- und Big-Data-Rollen lukrativ machen, dazu, dieses Vorstellungsgespräch zu bestehen, oder? 🤔
- Laut Indeed.com verdient ein in den USA ansässiger Big Data Hadoop-Entwickler ein Durchschnittsgehalt von 144.000 US-Dollar.
- Laut itjobswatch.co.uk beträgt das Durchschnittsgehalt eines Big Data Hadoop-Entwicklers 66.750 £.
- In Indien gibt die Quelle Indeed.com an, dass sie ein Durchschnittsgehalt von ₹ 16.00.000 verdienen würden.
Lukrativ, finden Sie nicht? Lassen Sie uns jetzt einsteigen, um mehr über Hadoop zu erfahren.
Inhaltsverzeichnis
Was ist Hadoop?
Hadoop ist ein beliebtes in Java geschriebenes Framework, das Programmiermodelle verwendet, um große Datenmengen zu verarbeiten, zu speichern und zu analysieren.
Standardmäßig ermöglicht sein Design die Skalierung von einzelnen Servern auf mehrere Computer, die lokale Berechnung und Speicherung bieten. Darüber hinaus macht seine Fähigkeit, Fehler auf Anwendungsebene zu erkennen und zu handhaben, was zu hochverfügbaren Diensten führt, Hadoop sehr zuverlässig.
Lassen Sie uns direkt zu den häufig gestellten Fragen zu Hadoop-Interviews und ihren richtigen Antworten springen.
Interviewfragen und -antworten von Hadoop
Was ist die Speichereinheit in Hadoop?
Antwort: Die Speichereinheit von Hadoop heißt Hadoop Distributed File System (HDFS).
Wie unterscheidet sich Network Attached Storage vom verteilten Hadoop-Dateisystem?
Antwort: HDFS, der primäre Speicher von Hadoop, ist ein verteiltes Dateisystem, das riesige Dateien mit handelsüblicher Hardware speichert. Auf der anderen Seite ist NAS ein Computer-Datenspeicherserver auf Dateiebene, der heterogenen Client-Gruppen Zugriff auf die Daten bietet.
Während sich die Datenspeicherung in NAS auf dedizierter Hardware befindet, verteilt HDFS die Datenblöcke auf alle Maschinen innerhalb des Hadoop-Clusters.
NAS verwendet High-End-Speichergeräte, was ziemlich kostspielig ist, während die in HDFS verwendete Standardhardware kostengünstig ist.
NAS speichert Daten separat von Berechnungen und ist daher für MapReduce ungeeignet. Im Gegenteil, das Design von HDFS erlaubt es, mit dem MapReduce-Framework zu arbeiten. Berechnungen werden in die Daten im MapReduce-Framework verschoben, statt Daten in Berechnungen.
Erklären Sie MapReduce in Hadoop und Shuffling
Antwort: MapReduce bezieht sich auf zwei unterschiedliche Aufgaben, die Hadoop-Programme ausführen, um eine große Skalierbarkeit über Hunderte bis Tausende von Servern innerhalb eines Hadoop-Clusters zu ermöglichen. Shuffling hingegen überträgt die Kartenausgabe von Mappern an den erforderlichen Reducer in MapReduce.
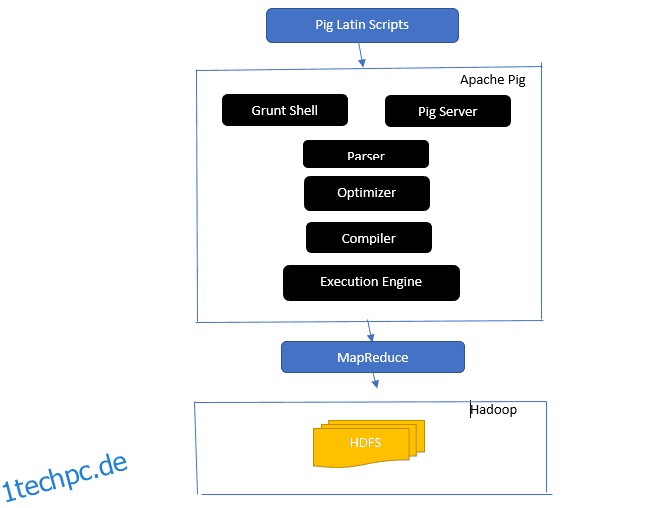
Geben Sie einen Einblick in die Architektur von Apache Pig
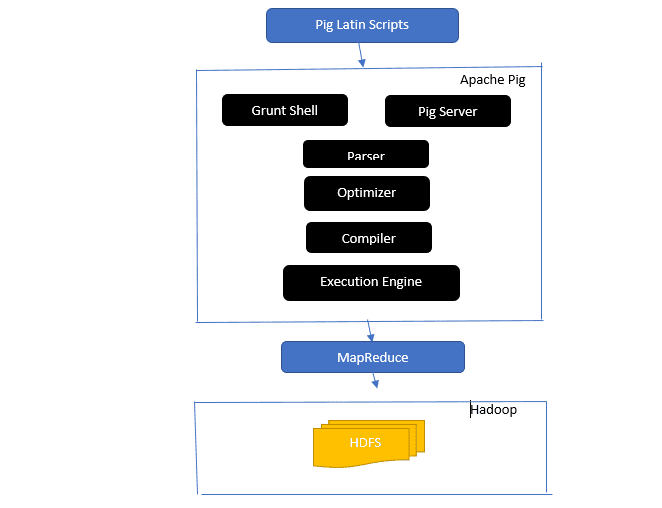 Die Apache-Pig-Architektur
Die Apache-Pig-Architektur
Antwort: Die Apache Pig-Architektur verfügt über einen Pig Latin-Interpreter, der große Datensätze mithilfe von Pig Latin-Skripten verarbeitet und analysiert.
Apache Pig besteht auch aus Sätzen von Datensätzen, auf denen Datenoperationen wie Verbinden, Laden, Filtern, Sortieren und Gruppieren ausgeführt werden.
Die Pig Latin-Sprache verwendet Ausführungsmechanismen wie Grant-Shells, UDFs und Embedded zum Schreiben von Pig-Skripten, die erforderliche Aufgaben ausführen.
Pig erleichtert Programmierern die Arbeit, indem es diese geschriebenen Skripte in Map-Reduce-Jobserien umwandelt.
Zu den Komponenten der Apache Pig-Architektur gehören:
- Parser – Er behandelt die Pig-Skripte, indem er die Syntax des Skripts überprüft und eine Typprüfung durchführt. Die Ausgabe des Parsers stellt die Anweisungen und logischen Operatoren von Pig Latin dar und wird DAG (gerichteter azyklischer Graph) genannt.
- Optimierer – Der Optimierer implementiert logische Optimierungen wie Projektion und Pushdown auf dem DAG.
- Compiler – Kompiliert den optimierten logischen Plan vom Optimierer in eine Reihe von MapReduce-Jobs.
- Execution Engine – Hier findet die endgültige Ausführung der MapReduce-Jobs in der gewünschten Ausgabe statt.
- Ausführungsmodus – Die Ausführungsmodi in Apache Pig umfassen hauptsächlich Local und Map Reduce.
Antwort: Der Metastore-Dienst in Local Metastore wird in derselben JVM wie Hive ausgeführt, stellt jedoch eine Verbindung zu einer Datenbank her, die in einem separaten Prozess auf demselben oder einem Remote-Computer ausgeführt wird. Andererseits wird Metastore im Remote-Metastore in seiner JVM getrennt von der Hive-Dienst-JVM ausgeführt.
Was sind die fünf Vs von Big Data?
Antwort: Diese fünf V stehen für die Hauptmerkmale von Big Data. Sie beinhalten:
- Wert: Big Data zielt darauf ab, einem Unternehmen, das Big Data in seinen Datenoperationen verwendet, erhebliche Vorteile durch einen hohen Return on Investment (ROI) zu bieten. Big Data bringt diesen Wert aus der Entdeckung von Erkenntnissen und der Mustererkennung, was unter anderem zu stärkeren Kundenbeziehungen und effektiveren Abläufen führt.
- Vielfalt: Dies repräsentiert die Heterogenität der Art der gesammelten Datentypen. Die verschiedenen Formate umfassen CSV, Videos, Audio usw.
- Volumen: Dies definiert die signifikante Menge und Größe der Daten, die von einer Organisation verwaltet und analysiert werden. Diese Daten zeigen ein exponentielles Wachstum.
- Geschwindigkeit: Dies ist die exponentielle Geschwindigkeitsrate für das Datenwachstum.
- Wahrheitsgehalt: Wahrheitsgehalt bezieht sich darauf, wie „unsicher“ oder „ungenau“ die verfügbaren Daten sind, weil die Daten unvollständig oder widersprüchlich sind.
Erklären Sie verschiedene Datentypen von Pig Latin.
Antwort: Die Datentypen in Pig Latin umfassen atomare Datentypen und komplexe Datentypen.
Die atomaren Datentypen sind die grundlegenden Datentypen, die in jeder anderen Sprache verwendet werden. Dazu gehören:
- Int – Dieser Datentyp definiert eine vorzeichenbehaftete 32-Bit-Ganzzahl. Beispiel: 13
- Long – Long definiert eine 64-Bit-Ganzzahl. Beispiel: 10L
- Float – Definiert ein vorzeichenbehaftetes 32-Bit-Gleitkomma. Beispiel: 2,5F
- Double – Definiert ein vorzeichenbehaftetes 64-Bit-Gleitkomma. Beispiel: 23.4
- Boolean – Definiert einen booleschen Wert. Es beinhaltet: Wahr/Falsch
- Datetime – Definiert einen Datum-Uhrzeit-Wert. Beispiel: 1980-01-01T00:00.00.000+00:00
Zu den komplexen Datentypen gehören:
- Map-Map bezieht sich auf einen Satz von Schlüssel-Wert-Paaren. Beispiel: [‘color’#’yellow’, ‘number’#3]
- Bag – Es ist eine Sammlung einer Menge von Tupeln und verwendet das Symbol „{}“. Beispiel: {(Henry, 32), (Kiti, 47)}
- Tupel – Ein Tupel definiert einen geordneten Satz von Feldern. Beispiel: (Alter, 33)
Was sind Apache Oozie und Apache ZooKeeper?
Antwort: Apache Oozie ist ein Hadoop-Scheduler, der für die Planung und Bindung von Hadoop-Jobs als eine einzige logische Arbeit zuständig ist.
Apache Zookeeper hingegen koordiniert sich mit verschiedenen Diensten in einer verteilten Umgebung. Es spart den Entwicklern Zeit, indem es einfach einfache Dienste wie Synchronisierung, Gruppierung, Konfigurationsverwaltung und Benennung verfügbar macht. Apache Zookeeper bietet auch standardmäßige Unterstützung für die Warteschlangen- und Leader-Wahl.
Welche Rolle spielen Combiner, RecordReader und Partitioner in einer MapReduce-Operation?
Antwort: Der Combiner wirkt wie ein Mini-Reduzierer. Es empfängt und verarbeitet Daten von Kartenaufgaben und leitet dann die Datenausgabe an die Reduziererphase weiter.
Der RecordHeader kommuniziert mit dem InputSplit und wandelt die Daten in Schlüssel-Wert-Paare um, die der Mapper entsprechend lesen kann.
Der Partitionierer ist dafür verantwortlich, die Anzahl der reduzierten Tasks zu bestimmen, die zum Zusammenfassen von Daten erforderlich sind, und zu bestätigen, wie die Kombiniererausgaben an den Reduzierer gesendet werden. Der Partitionierer steuert auch die Schlüsselpartitionierung der Zwischenabbildungsausgaben.
Erwähnen Sie verschiedene herstellerspezifische Distributionen von Hadoop.
Antwort: Zu den verschiedenen Anbietern, die Hadoop-Funktionen erweitern, gehören:
- IBM Open-Plattform.
- Cloudera CDH Hadoop-Verteilung
- MapR Hadoop-Verteilung
- Amazon Elastic MapReduce
- Hortonworks-Datenplattform (HDP)
- Zentrale Big-Data-Suite
- Datastax Enterprise Analytics
- HDInsight von Microsoft Azure – Cloudbasierte Hadoop-Verteilung.
Warum ist HDFS fehlertolerant?
Antwort: HDFS repliziert Daten auf verschiedenen DataNodes und ist dadurch fehlertolerant. Das Speichern der Daten in verschiedenen Knoten ermöglicht das Abrufen von anderen Knoten, wenn ein Modus abstürzt.
Unterscheiden Sie zwischen einem Verbund und hoher Verfügbarkeit.
Antwort: HDFS Federation bietet Fehlertoleranz, die einen kontinuierlichen Datenfluss in einem Knoten ermöglicht, wenn ein anderer abstürzt. Andererseits erfordert Hochverfügbarkeit zwei separate Computer, die den aktiven NameNode und den sekundären NameNode auf dem ersten und dem zweiten Computer separat konfigurieren.
Federation kann eine unbegrenzte Anzahl unabhängiger NameNodes haben, während bei Hochverfügbarkeit nur zwei verwandte NameNodes, aktiv und Standby, verfügbar sind, die kontinuierlich arbeiten.
NameNodes im Verbund teilen sich einen Metadatenpool, wobei jeder NameNode seinen dedizierten Pool hat. Bei Hochverfügbarkeit werden die aktiven NameNodes jedoch einzeln ausgeführt, während die Standby-NameNodes im Leerlauf bleiben und ihre Metadaten nur gelegentlich aktualisieren.
Wie finde ich den Status von Blöcken und den Zustand des Dateisystems?
Antwort: Sie verwenden den Befehl hdfs fsck / sowohl auf der Root-Benutzerebene als auch in einem einzelnen Verzeichnis, um den Integritätsstatus des HDFS-Dateisystems zu überprüfen.
Verwendeter HDFS fsck-Befehl:
hdfs fsck / -files --blocks –locations> dfs-fsck.log
Die Beschreibung des Befehls:
- -files: Druckt die Dateien, die Sie überprüfen.
- –locations: Druckt die Positionen aller Blöcke während der Überprüfung.
Befehl zum Überprüfen des Status der Blöcke:
hdfs fsck <path> -files -blocks
: Beginnt die Prüfungen ab dem hier übergebenen Pfad. - – Blöcke: Druckt die Dateiblöcke während der Prüfung
Wann verwenden Sie die Befehle rmadmin-refreshNodes und dfsadmin-refreshNodes?
Antwort: Diese beiden Befehle sind hilfreich beim Aktualisieren der Knoteninformationen entweder während der Inbetriebnahme oder nach Abschluss der Knoteninbetriebnahme.
Der Befehl dfsadmin-refreshNodes führt den HDFS-Client aus und aktualisiert die Knotenkonfiguration von NameNode. Der Befehl rmadmin-refreshNodes hingegen führt die administrativen Aufgaben des ResourceManagers aus.
Was ist ein Kontrollpunkt?
Antwort: Checkpoint ist eine Operation, die die letzten Änderungen des Dateisystems mit dem neuesten FSImage zusammenführt, sodass die Bearbeitungsprotokolldateien klein genug bleiben, um den Prozess zum Starten eines NameNode zu beschleunigen. Checkpoint tritt im sekundären NameNode auf.
Warum verwenden wir HDFS für Anwendungen mit großen Datensätzen?
Antwort: HDFS bietet eine DataNode- und NameNode-Architektur, die ein verteiltes Dateisystem implementiert.
Diese beiden Architekturen bieten einen Hochleistungszugriff auf Daten über hochgradig skalierbare Hadoop-Cluster. Sein NameNode speichert die Metadaten des Dateisystems im RAM, was dazu führt, dass die Speichermenge die Anzahl der HDFS-Dateisystemdateien begrenzt.
Was bewirkt der Befehl „jps“?
Antwort: Der JPS-Befehl (Java Virtual Machine Process Status) überprüft, ob bestimmte Hadoop-Daemons, einschließlich NodeManager, DataNode, NameNode und ResourceManager, ausgeführt werden oder nicht. Dieser Befehl muss vom Root aus ausgeführt werden, um die Betriebsknoten im Host zu überprüfen.
Was ist „spekulative Ausführung“ in Hadoop?
Antwort: Dies ist ein Prozess, bei dem der Master-Knoten in Hadoop, anstatt erkannte langsame Aufgaben zu beheben, eine andere Instanz derselben Aufgabe als Sicherungsaufgabe (spekulative Aufgabe) auf einem anderen Knoten startet. Die spekulative Ausführung spart viel Zeit, insbesondere in einer intensiven Workload-Umgebung.
Nennen Sie die drei Modi, in denen Hadoop ausgeführt werden kann.
Antwort: Zu den drei primären Knoten, auf denen Hadoop ausgeführt wird, gehören:
- Eigenständiger Knoten ist der Standardmodus, der die Hadoop-Dienste unter Verwendung des lokalen Dateisystems und eines einzelnen Java-Prozesses ausführt.
- Pseudo-verteilter Knoten führt alle Hadoop-Dienste unter Verwendung einer einzelnen Hadoop-Bereitstellung aus.
- Vollständig verteilter Knoten führt Hadoop-Master- und -Slave-Dienste unter Verwendung separater Knoten aus.
Was ist eine UDF?
Antwort: Mit UDF (User Defined Functions) können Sie Ihre benutzerdefinierten Funktionen codieren, die Sie verwenden können, um Spaltenwerte während einer Impala-Abfrage zu verarbeiten.
Was ist DistCp?
Antwort: DistCp oder Distributed Copy, kurz gesagt, ist ein nützliches Tool zum Kopieren großer Datenmengen zwischen oder innerhalb von Clustern. Mit MapReduce implementiert DistCp neben anderen Aufgaben wie Fehlerbehandlung, Wiederherstellung und Berichterstellung effektiv die verteilte Kopie einer großen Datenmenge.
Antwort: Hive Metastore ist ein Dienst, der Apache Hive-Metadaten für die Hive-Tabellen in einer relationalen Datenbank wie MySQL speichert. Es stellt die Metastore-Service-API bereit, die Cent-Zugriff auf die Metadaten ermöglicht.
RDD definieren.
Antwort: RDD steht für Resilient Distributed Datasets und ist die Datenstruktur von Spark und eine unveränderliche verteilte Sammlung Ihrer Datenelemente, die auf den verschiedenen Cluster-Knoten berechnet wird.
Wie können native Bibliotheken in YARN-Jobs eingebunden werden?
Antwort: Sie können dies implementieren, indem Sie entweder -Djava.library verwenden. path-Option im Befehl oder durch Festlegen von LD+LIBRARY_PATH in der .bashrc-Datei im folgenden Format:
<property> <name>mapreduce.map.env</name> <value>LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/path/to/my/libs</value> </property>
Erklären Sie „WAL“ in HBase.
Antwort: Das Write Ahead Log (WAL) ist ein Wiederherstellungsprotokoll, das MemStore-Datenänderungen in HBase im dateibasierten Speicher aufzeichnet. WAL stellt diese Daten wieder her, wenn der RegionalServer abstürzt oder bevor der MemStore geleert wird.
Ist YARN ein Ersatz für Hadoop MapReduce?
Antwort: Nein, YARN ist kein Ersatz für Hadoop MapReduce. Stattdessen unterstützt eine leistungsstarke Technologie namens Hadoop 2.0 oder MapReduce 2 MapReduce.
Was ist der Unterschied zwischen ORDER BY und SORT BY in HIVE?
Antwort: Während beide Befehle Daten in Hive sortiert abrufen, können Ergebnisse bei der Verwendung von SORT BY nur teilweise geordnet sein.
Außerdem benötigt SORT BY einen Reducer, um die Zeilen zu ordnen. Diese für die endgültige Ausgabe erforderlichen Reduzierstücke können auch mehrere sein. In diesem Fall kann die endgültige Ausgabe teilweise bestellt werden.
Andererseits erfordert ORDER BY nur einen Reduzierer für einen Gesamtauftrag in der Ausgabe. Sie können auch das Schlüsselwort LIMIT verwenden, das die Gesamtsortierzeit reduziert.
Was ist der Unterschied zwischen Spark und Hadoop?
Antwort: Während sowohl Hadoop als auch Spark verteilte Verarbeitungsframeworks sind, besteht ihr Hauptunterschied in ihrer Verarbeitung. Wo Hadoop für die Stapelverarbeitung effizient ist, ist Spark für die Datenverarbeitung in Echtzeit effizient.
Darüber hinaus liest und schreibt Hadoop hauptsächlich Dateien in HDFS, während Spark das Resilient Distributed Dataset-Konzept verwendet, um Daten im RAM zu verarbeiten.
Basierend auf ihrer Latenz ist Hadoop ein Computing-Framework mit hoher Latenz ohne interaktiven Modus zur Datenverarbeitung, während Spark ein Computing-Framework mit niedriger Latenz ist, das Daten interaktiv verarbeitet.
Vergleichen Sie Sqoop und Flume.
Antwort: Sqoop und Flume sind Hadoop-Tools, die Daten sammeln, die aus verschiedenen Quellen gesammelt wurden, und die Daten in HDFS laden.
- Sqoop (SQL-to-Hadoop) extrahiert strukturierte Daten aus Datenbanken, einschließlich Teradata, MySQL, Oracle usw., während Flume nützlich ist, um unstrukturierte Daten aus Datenbankquellen zu extrahieren und sie in HDFS zu laden.
- In Bezug auf gesteuerte Ereignisse ist Flume ereignisgesteuert, während Sqoop nicht von Ereignissen gesteuert wird.
- Sqoop verwendet eine konnektorbasierte Architektur, bei der Konnektoren wissen, wie sie eine Verbindung zu einer anderen Datenquelle herstellen. Flume verwendet eine agentenbasierte Architektur, wobei der darin geschriebene Code der Agent ist, der für das Abrufen der Daten verantwortlich ist.
- Aufgrund der verteilten Natur von Flume können Daten einfach gesammelt und aggregiert werden. Sqoop ist nützlich für die parallele Datenübertragung, was dazu führt, dass die Ausgabe in mehreren Dateien erfolgt.
Erklären Sie die BloomMapFile.
Antwort: BloomMapFile ist eine Klasse, die die MapFile-Klasse erweitert und dynamische Bloom-Filter verwendet, die einen schnellen Mitgliedschaftstest für Schlüssel bieten.
Listen Sie den Unterschied zwischen HiveQL und PigLatin auf.
Antwort: Während HiveQL eine SQL ähnliche deklarative Sprache ist, ist PigLatin eine prozedurale Datenflusssprache auf hoher Ebene.
Was ist Datenbereinigung?
Antwort: Die Datenbereinigung ist ein entscheidender Prozess, um identifizierte Datenfehler zu beseitigen oder zu beheben, zu denen falsche, unvollständige, beschädigte, doppelte und falsch formatierte Daten innerhalb eines Datensatzes gehören.
Dieser Prozess zielt darauf ab, die Qualität der Daten zu verbessern und genauere, konsistentere und zuverlässigere Informationen bereitzustellen, die für eine effiziente Entscheidungsfindung innerhalb einer Organisation erforderlich sind.
Fazit💃
Angesichts des aktuellen Anstiegs der Stellenangebote für Big Data und Hadoop möchten Sie vielleicht Ihre Chancen auf einen Einstieg verbessern. Die Fragen und Antworten zu Hadoop-Interviews in diesem Artikel werden Ihnen dabei helfen, das bevorstehende Vorstellungsgespräch zu meistern.
Als Nächstes können Sie sich gute Ressourcen zum Erlernen von Big Data und Hadoop ansehen.
Viel Glück! 👍