

Support Vector Machine gehört zu den beliebtesten Algorithmen für maschinelles Lernen. Es ist effizient und kann in begrenzten Datensätzen trainieren. Aber was ist es?
Inhaltsverzeichnis
Was ist eine Support Vector Machine (SVM)?
Support Vector Machine ist ein maschineller Lernalgorithmus, der überwachtes Lernen verwendet, um ein Modell für die binäre Klassifizierung zu erstellen. Das ist ein Schluck. Dieser Artikel erklärt SVM und wie es mit der Verarbeitung natürlicher Sprache zusammenhängt. Aber lassen Sie uns zuerst analysieren, wie eine Support-Vektor-Maschine funktioniert.
Wie funktioniert SVM?
Stellen Sie sich ein einfaches Klassifizierungsproblem vor, bei dem wir Daten haben, die zwei Merkmale, x und y, und eine Ausgabe haben – eine Klassifizierung, die entweder rot oder blau ist. Wir können einen imaginären Datensatz zeichnen, der so aussieht:
Angesichts solcher Daten bestünde die Aufgabe darin, eine Entscheidungsgrenze zu erstellen. Eine Entscheidungsgrenze ist eine Linie, die die beiden Klassen unserer Datenpunkte trennt. Dies ist derselbe Datensatz, jedoch mit einer Entscheidungsgrenze:
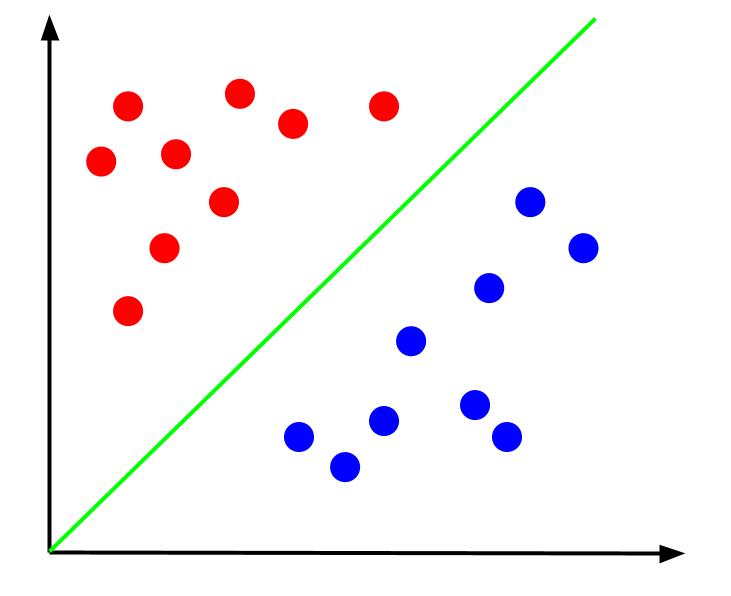
Mit dieser Entscheidungsgrenze können wir dann Vorhersagen treffen, zu welcher Klasse ein Datenpunkt gehört, wenn er relativ zur Entscheidungsgrenze liegt. Der Support Vector Machine-Algorithmus erstellt die beste Entscheidungsgrenze, die zum Klassifizieren von Punkten verwendet wird.
Aber was meinen wir mit der besten Entscheidungsgrenze?
Es kann argumentiert werden, dass die beste Entscheidungsgrenze diejenige ist, die ihren Abstand von einem der Unterstützungsvektoren maximiert. Unterstützungsvektoren sind Datenpunkte jeder Klasse, die der gegenüberliegenden Klasse am nächsten sind. Diese Datenpunkte bergen aufgrund ihrer Nähe zur anderen Klasse das größte Risiko einer Fehlklassifizierung.
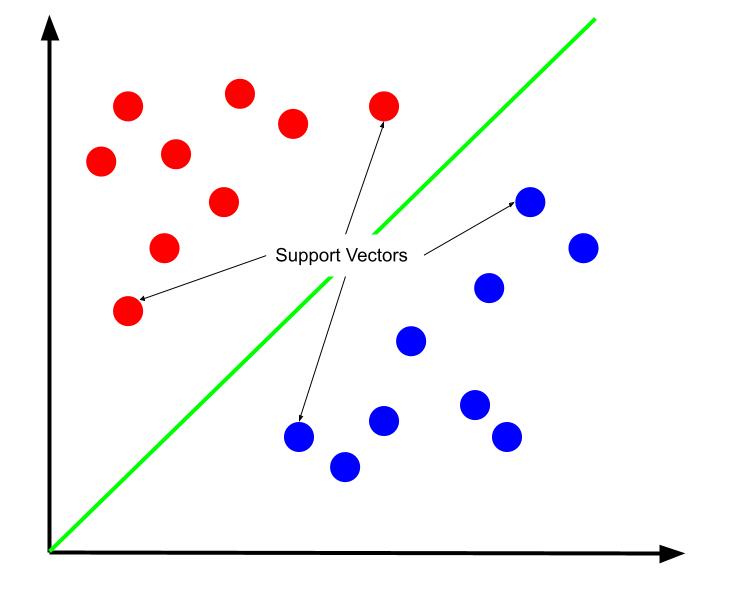
Das Training einer Support-Vektor-Maschine beinhaltet daher den Versuch, eine Linie zu finden, die den Spielraum zwischen Support-Vektoren maximiert.
Es ist auch wichtig zu beachten, dass, weil die Entscheidungsgrenze relativ zu den Unterstützungsvektoren positioniert ist, sie die einzigen Determinanten der Position der Entscheidungsgrenze sind. Die anderen Datenpunkte sind daher redundant. Und so erfordert das Training nur die Unterstützungsvektoren.
In diesem Beispiel ist die gebildete Entscheidungsgrenze eine gerade Linie. Dies liegt nur daran, dass der Datensatz nur zwei Merkmale aufweist. Wenn der Datensatz drei Merkmale aufweist, ist die gebildete Entscheidungsgrenze eher eine Ebene als eine Linie. Und wenn sie vier oder mehr Merkmale aufweist, wird die Entscheidungsgrenze als Hyperebene bezeichnet.
Nicht linear trennbare Daten
Das obige Beispiel betrachtete sehr einfache Daten, die, wenn sie gezeichnet werden, durch eine lineare Entscheidungsgrenze getrennt werden können. Stellen Sie sich einen anderen Fall vor, in dem Daten wie folgt dargestellt werden:
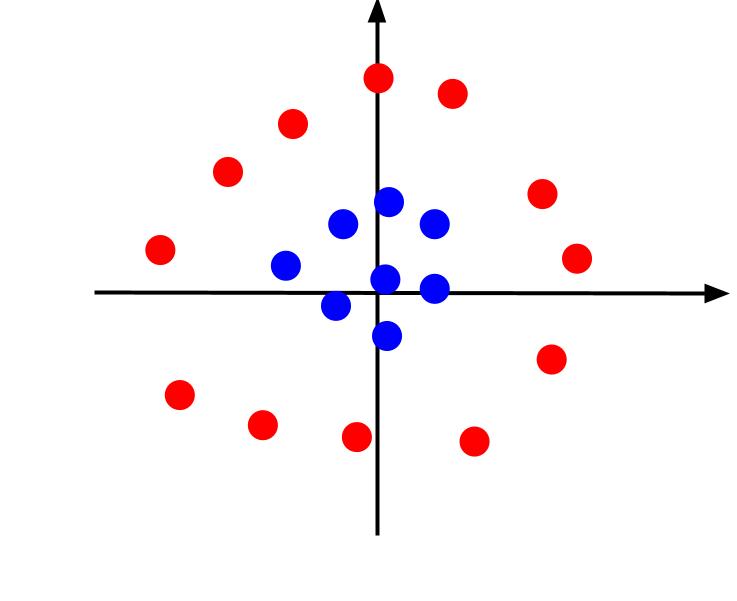
In diesem Fall ist eine Trennung der Daten durch eine Linie nicht möglich. Aber wir können ein anderes Feature erstellen, z. Und dieses Merkmal kann durch die Gleichung definiert werden: z = x^2 + y^2. Wir können der Ebene z als dritte Achse hinzufügen, um sie dreidimensional zu machen.
Wenn wir das 3D-Diagramm aus einem Winkel betrachten, bei dem die x-Achse horizontal und die z-Achse vertikal verläuft, erhalten wir diese Ansicht, die so aussieht:
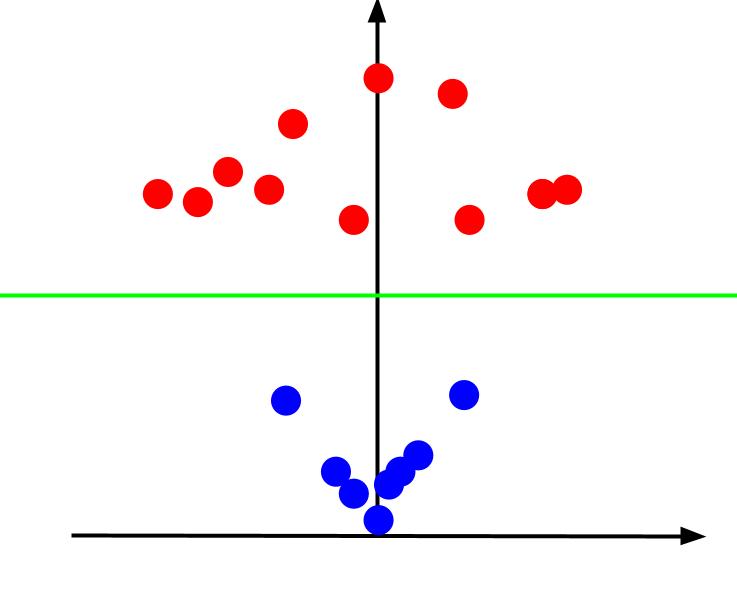
Der z-Wert gibt an, wie weit ein Punkt relativ zu den anderen Punkten in der alten XY-Ebene vom Ursprung entfernt ist. Infolgedessen haben die näher am Ursprung liegenden blauen Punkte niedrige Z-Werte.
Während die roten Punkte, die weiter vom Ursprung entfernt sind, höhere Z-Werte hatten, erhalten wir durch Auftragen gegen ihre Z-Werte eine klare Klassifizierung, die wie dargestellt durch eine lineare Entscheidungsgrenze abgegrenzt werden kann.
Dies ist eine leistungsstarke Idee, die in Support Vector Machines verwendet wird. Allgemeiner gesagt ist es die Idee, die Dimensionen in eine größere Anzahl von Dimensionen abzubilden, sodass Datenpunkte durch eine lineare Grenze getrennt werden können. Funktionen, die dafür zuständig sind, sind Kernel-Funktionen. Es gibt viele Kernel-Funktionen wie Sigmoid, Linear, Non-Linear und RBF.
Um die Zuordnung dieser Funktionen effizienter zu gestalten, verwendet SVM einen Kernel-Trick.
SVM im maschinellen Lernen
Support Vector Machine ist neben populären wie Entscheidungsbäumen und neuronalen Netzen einer der vielen Algorithmen, die beim maschinellen Lernen verwendet werden. Es wird bevorzugt, weil es mit weniger Daten als andere Algorithmen gut funktioniert. Es wird häufig verwendet, um Folgendes zu tun:
- Textklassifizierung: Klassifizierung von Textdaten wie Kommentaren und Rezensionen in eine oder mehrere Kategorien
- Gesichtserkennung: Analysieren von Bildern, um Gesichter zu erkennen, um beispielsweise Filter für Augmented Reality hinzuzufügen
- Bildklassifizierung: Support Vector Machines können Bilder im Vergleich zu anderen Ansätzen effizient klassifizieren.
Das Textklassifikationsproblem
Das Internet ist mit Unmengen von Textdaten gefüllt. Viele dieser Daten sind jedoch unstrukturiert und unbeschriftet. Um diese Textdaten besser nutzen und besser verstehen zu können, ist eine Klassifizierung erforderlich. Beispiele für Zeiten, in denen Text klassifiziert wird, sind:
- Wenn Tweets in Themen kategorisiert werden, damit die Leute den gewünschten Themen folgen können
- Wenn eine E-Mail entweder als Social, Promotions oder Spam kategorisiert wird
- Wenn Kommentare in öffentlichen Foren als hasserfüllt oder obszön eingestuft werden
Funktionsweise von SVM mit Natural Language Classification
Die Support Vector Machine wird verwendet, um Text in Text zu klassifizieren, der zu einem bestimmten Thema gehört, und Text, der nicht zu dem Thema gehört. Dies wird erreicht, indem die Textdaten zunächst in einen Datensatz mit mehreren Merkmalen konvertiert und dargestellt werden.
Eine Möglichkeit, dies zu tun, besteht darin, Merkmale für jedes Wort im Datensatz zu erstellen. Dann notieren Sie für jeden Textdatenpunkt, wie oft jedes Wort vorkommt. Nehmen wir also an, dass im Datensatz eindeutige Wörter vorkommen; Sie werden Features im Datensatz haben.
Außerdem stellen Sie Klassifizierungen für diese Datenpunkte bereit. Während diese Klassifikationen durch Text beschriftet sind, erwarten die meisten SVM-Implementierungen numerische Beschriftungen.
Daher müssen Sie diese Beschriftungen vor dem Training in Zahlen umwandeln. Nachdem der Datensatz vorbereitet wurde, indem Sie diese Features als Koordinaten verwenden, können Sie den Text mithilfe eines SVM-Modells klassifizieren.
Erstellen einer SVM in Python
Um eine Support Vector Machine (SVM) in Python zu erstellen, können Sie die SVC-Klasse aus der sklearn.svm-Bibliothek verwenden. Hier ist ein Beispiel dafür, wie Sie die SVC-Klasse verwenden können, um ein SVM-Modell in Python zu erstellen:
from sklearn.svm import SVC
# Load the dataset
X = ... y = ...
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Create an SVM model
model = SVC(kernel="linear")
# Train the model on the training data
model.fit(X_train, y_train)
# Evaluate the model on the test data
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
In diesem Beispiel importieren wir zuerst die SVC-Klasse aus der Bibliothek sklearn.svm. Dann laden wir das Dataset und teilen es in Trainings- und Testsets auf.
Als nächstes erstellen wir ein SVM-Modell, indem wir ein SVC-Objekt instanziieren und den Kernel-Parameter als „linear“ angeben. Anschließend trainieren wir das Modell auf den Trainingsdaten mit der Fit-Methode und evaluieren das Modell auf den Testdaten mit der Score-Methode. Die Score-Methode gibt die Genauigkeit des Modells zurück, die wir auf der Konsole ausgeben.
Sie können auch andere Parameter für das SVC-Objekt angeben, z. B. den C-Parameter, der die Stärke der Regularisierung steuert, und den Gamma-Parameter, der den Kernel-Koeffizienten für bestimmte Kernel steuert.
Vorteile von SVM
Hier ist eine Liste einiger Vorteile der Verwendung von Support Vector Machines (SVMs):
- Effizient: SVMs sind im Allgemeinen effizient zu trainieren, insbesondere wenn die Anzahl der Proben groß ist.
- Robust gegenüber Rauschen: SVMs sind relativ robust gegenüber Rauschen in den Trainingsdaten, da sie versuchen, den Klassifikator mit maximalem Spielraum zu finden, der weniger empfindlich gegenüber Rauschen ist als andere Klassifikatoren.
- Speichereffizient: SVMs benötigen zu jedem Zeitpunkt nur eine Teilmenge der Trainingsdaten im Speicher, wodurch sie speichereffizienter sind als andere Algorithmen.
- Effektiv in hochdimensionalen Räumen: SVMs können auch dann noch gut funktionieren, wenn die Anzahl der Features die Anzahl der Samples übersteigt.
- Vielseitigkeit: SVMs können für Klassifizierungs- und Regressionsaufgaben verwendet werden und können verschiedene Datentypen verarbeiten, einschließlich linearer und nichtlinearer Daten.
Sehen wir uns nun einige der besten Ressourcen zum Erlernen von Support Vector Machine (SVM) an.
Lernmittel
Eine Einführung in Support Vector Machines
Dieses Buch zur Einführung in Support Vector Machines führt Sie umfassend und schrittweise in Kernel-basierte Lernmethoden ein.
Es gibt Ihnen eine solide Grundlage für die Theorie der Support Vector Machines.
Unterstützung von Vector Machines-Anwendungen
Während sich das erste Buch auf die Theorie von Support Vector Machines konzentrierte, konzentriert sich dieses Buch über Support Vector Machines Applications auf ihre praktischen Anwendungen.
Es untersucht, wie SVMs in der Bildverarbeitung, Mustererkennung und Computer Vision verwendet werden.
Support Vector Machines (Informationswissenschaft und Statistik)
Der Zweck dieses Buches über Support Vector Machines (Informationswissenschaft und Statistik) besteht darin, einen Überblick über die Prinzipien zu geben, die hinter der Effektivität von Support Vector Machines (SVMs) in verschiedenen Anwendungen stehen.
Die Autoren heben mehrere Faktoren hervor, die zum Erfolg von SVMs beitragen, darunter ihre Fähigkeit, mit einer begrenzten Anzahl einstellbarer Parameter eine gute Leistung zu erbringen, ihre Widerstandsfähigkeit gegenüber verschiedenen Arten von Fehlern und Anomalien und ihre effiziente Rechenleistung im Vergleich zu anderen Methoden.
Lernen mit Kerneln
„Learning with Kernels“ ist ein Buch, das Leser in Support Vector Machines (SVMs) und verwandte Kernel-Techniken einführt.
Es wurde entwickelt, um den Lesern ein grundlegendes Verständnis der Mathematik und das Wissen zu vermitteln, das sie benötigen, um mit der Verwendung von Kernalgorithmen beim maschinellen Lernen zu beginnen. Das Buch zielt darauf ab, eine gründliche und dennoch zugängliche Einführung in SVMs und Kernel-Methoden zu bieten.
Unterstützung von Vektormaschinen mit Sci-kit Learn
Dieser Online-Kurs „Support Vector Machines with Sci-kit Learn“ des Coursera-Projektnetzwerks lehrt, wie ein SVM-Modell mithilfe der beliebten Bibliothek für maschinelles Lernen, Sci-Kit Learn, implementiert wird.

Darüber hinaus lernen Sie die Theorie hinter SVMs kennen und ermitteln ihre Stärken und Grenzen. Der Kurs ist Anfänger-Niveau und dauert ca. 2,5 Stunden.
Unterstützung von Vektormaschinen in Python: Konzepte und Code
Dieser kostenpflichtige Online-Kurs zu Support Vector Machines in Python von Udemy umfasst bis zu 6 Stunden videobasierte Anleitung und wird mit einer Zertifizierung geliefert.

Es behandelt SVMs und wie sie solide in Python implementiert werden können. Darüber hinaus werden Geschäftsanwendungen von Support Vector Machines behandelt.
Maschinelles Lernen und KI: Unterstützung von Vektormaschinen in Python
In diesem Kurs zu maschinellem Lernen und KI lernen Sie, wie Sie Support-Vektor-Maschinen (SVMs) für verschiedene praktische Anwendungen verwenden, darunter Bilderkennung, Spam-Erkennung, medizinische Diagnose und Regressionsanalyse.

Sie verwenden die Programmiersprache Python, um ML-Modelle für diese Anwendungen zu implementieren.
Letzte Worte
In diesem Artikel haben wir kurz etwas über die Theorie hinter Support Vector Machines gelernt. Wir haben etwas über ihre Anwendung im maschinellen Lernen und in der Verarbeitung natürlicher Sprache erfahren.
Wir haben auch gesehen, wie die Implementierung mit scikit-learn aussieht. Darüber hinaus sprachen wir über die praktischen Anwendungen und Vorteile von Support Vector Machines.
Während dieser Artikel nur eine Einführung war, empfahlen die zusätzlichen Ressourcen, mehr ins Detail zu gehen und mehr über Support Vector Machines zu erklären. Angesichts ihrer Vielseitigkeit und Effizienz lohnt es sich, SVMs zu verstehen, um als Datenwissenschaftler und ML-Ingenieur zu wachsen.
Als Nächstes können Sie sich die besten Modelle für maschinelles Lernen ansehen.