
Im Bereich der modernen künstlichen Intelligenz (KI) ist Reinforcement Learning (RL) eines der coolsten Forschungsthemen. Entwickler von KI und maschinellem Lernen (ML) konzentrieren sich ebenfalls auf RL-Praktiken, um intelligente Apps oder von ihnen entwickelte Tools zu improvisieren.
Maschinelles Lernen ist das Prinzip hinter allen KI-Produkten. Menschliche Entwickler verwenden verschiedene ML-Methoden, um ihre intelligenten Apps, Spiele usw. zu trainieren. ML ist ein sehr vielfältiges Gebiet, und verschiedene Entwicklungsteams verfügen über neuartige Methoden zum Trainieren einer Maschine.
Eine dieser lukrativen ML-Methoden ist Deep Reinforcement Learning. Hier bestrafen Sie unerwünschtes Maschinenverhalten und belohnen gewünschte Aktionen der intelligenten Maschine. Experten sind der Ansicht, dass diese ML-Methode die KI zwangsläufig dazu bringen wird, aus ihren eigenen Erfahrungen zu lernen.
Lesen Sie diesen ultimativen Leitfaden zu Methoden des Verstärkungslernens für intelligente Apps und Maschinen weiter, wenn Sie eine Karriere in den Bereichen künstliche Intelligenz und maschinelles Lernen in Betracht ziehen.
Inhaltsverzeichnis
Was ist Reinforcement Learning beim maschinellen Lernen?
RL ist das Lehren von Modellen des maschinellen Lernens für Computerprogramme. Dann kann die Anwendung basierend auf den Lernmodellen eine Folge von Entscheidungen treffen. Die Software lernt, ein Ziel in einem potenziell komplexen und unsicheren Umfeld zu erreichen. In einem solchen maschinellen Lernmodell sieht sich eine KI einem spielähnlichen Szenario gegenüber.
Die KI-App nutzt Trial-and-Error, um eine kreative Lösung für das vorliegende Problem zu erfinden. Sobald die KI-App die richtigen ML-Modelle lernt, weist sie die von ihr gesteuerte Maschine an, einige Aufgaben zu erledigen, die der Programmierer wünscht.
Basierend auf der richtigen Entscheidung und Aufgabenerfüllung erhält die KI eine Belohnung. Wenn die KI jedoch falsche Entscheidungen trifft, muss sie mit Strafen wie dem Verlust von Belohnungspunkten rechnen. Das ultimative Ziel für die KI-Anwendung ist es, die maximale Anzahl an Belohnungspunkten zu sammeln, um das Spiel zu gewinnen.
Der Programmierer der KI-App legt die Spielregeln oder die Belohnungspolitik fest. Der Programmierer liefert auch das Problem, das die KI lösen muss. Im Gegensatz zu anderen ML-Modellen erhält das KI-Programm keinen Hinweis vom Softwareprogrammierer.
Die KI muss herausfinden, wie sie die Spielherausforderungen löst, um maximale Belohnungen zu erhalten. Die App kann Trial-and-Error, Zufallsversuche, Supercomputer-Fähigkeiten und ausgeklügelte Denkprozesstaktiken verwenden, um eine Lösung zu finden.
Sie müssen das KI-Programm mit einer leistungsstarken Computerinfrastruktur ausstatten und sein Denksystem mit verschiedenen parallelen und historischen Gameplays verbinden. Dann kann die KI eine kritische und hochrangige Kreativität demonstrieren, die sich Menschen nicht vorstellen können.
Beliebte Beispiele für Reinforcement Learning
#1. Den besten menschlichen Go-Spieler besiegen
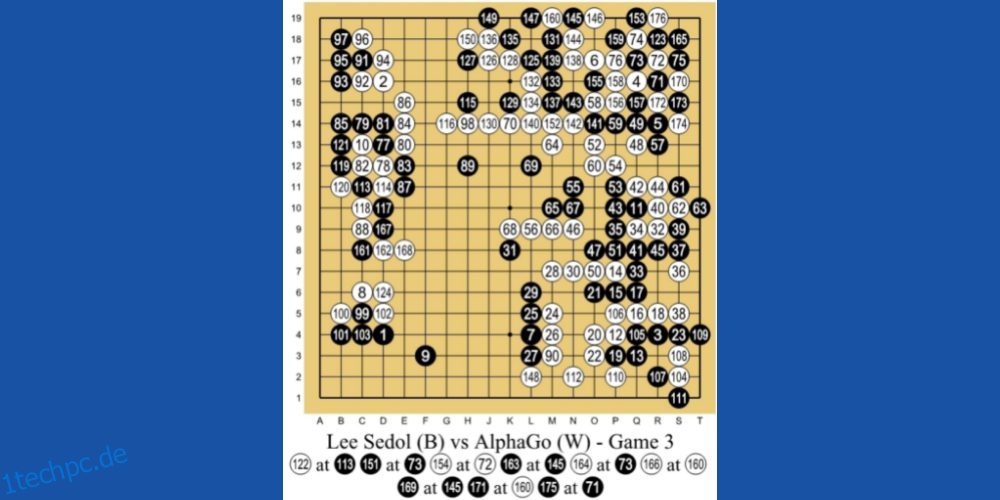
Die AlphaGo-KI von DeepMind Technologies, einer Tochtergesellschaft von Google, ist eines der führenden Beispiele für RL-basiertes maschinelles Lernen. Die KI spielt ein chinesisches Brettspiel namens Go. Es ist ein 3.000 Jahre altes Spiel, das sich auf Taktik und Strategie konzentriert.
Die Programmierer verwendeten die RL-Lehrmethode für AlphaGo. Es spielte Tausende von Go-Spielsitzungen mit Menschen und sich selbst. 2016 besiegte es dann den weltbesten Go-Spieler Lee Se-dol in einem Eins-gegen-Eins-Match.
#2. Robotik aus der realen Welt
Menschen setzen Robotik schon lange in Produktionslinien ein, in denen die Aufgaben vorgeplant und sich wiederholend sind. Aber wenn Sie einen Allzweckroboter für die reale Welt bauen müssen, in dem Aktionen nicht im Voraus geplant sind, dann ist das eine große Herausforderung.
Aber eine durch Verstärkungslernen aktivierte KI könnte eine reibungslose, navigierbare und kurze Route zwischen zwei Orten entdecken.
#3. Selbstfahrende Fahrzeuge
Forscher für autonome Fahrzeuge verwenden die RL-Methode häufig, um ihren KIs Folgendes beizubringen:
- Dynamisches Pathing
- Bahnoptimierung
- Bewegungsplanung wie Parken und Spurwechsel
- Optimierung von Controllern, (elektronischen Steuereinheiten) ECUs, (Mikrocontrollern) MCUs usw.
- Szenariobasiertes Lernen auf Autobahnen
#4. Automatisierte Kühlsysteme

RL-basierte KIs können dazu beitragen, den Energieverbrauch von Kühlsystemen in riesigen Bürogebäuden, Geschäftszentren, Einkaufszentren und vor allem Rechenzentren zu minimieren. Die KI sammelt Daten von Tausenden von Wärmesensoren.
Es sammelt auch Daten über menschliche und maschinelle Aktivitäten. Aus diesen Daten kann die KI das zukünftige Wärmeerzeugungspotenzial vorhersehen und Kühlsysteme entsprechend ein- und ausschalten, um Energie zu sparen.
So richten Sie ein Reinforcement-Learning-Modell ein
Sie können ein RL-Modell basierend auf den folgenden Methoden einrichten:
#1. Richtlinienbasiert
Dieser Ansatz ermöglicht es dem KI-Programmierer, die ideale Richtlinie für maximale Belohnungen zu finden. Hier verwendet der Programmierer nicht die Wertfunktion. Sobald Sie die richtlinienbasierte Methode festgelegt haben, versucht der Reinforcement Learning Agent, die Richtlinie anzuwenden, sodass die Aktionen, die er in jedem Schritt ausführt, es der KI ermöglichen, die Belohnungspunkte zu maximieren.
Es gibt hauptsächlich zwei Arten von Richtlinien:
#1. Deterministisch: Die Richtlinie kann in jedem beliebigen Zustand dieselben Aktionen ausführen.
#2. Stochastik: Die erzeugten Aktionen werden durch die Eintrittswahrscheinlichkeit bestimmt.
#2. Wertbasiert
Im Gegensatz dazu hilft der wertbasierte Ansatz dem Programmierer, die optimale Wertfunktion zu finden, die der maximale Wert unter einer Richtlinie in einem beliebigen gegebenen Zustand ist. Nach der Anwendung erwartet der RL-Agent die langfristige Rendite in einem oder mehreren Staaten im Rahmen der genannten Richtlinie.
#3. Modellbasiert
Beim modellbasierten RL-Ansatz erstellt der KI-Programmierer ein virtuelles Modell für die Umgebung. Dann bewegt sich der RL-Agent in der Umgebung und lernt daraus.
Arten von Reinforcement Learning
#1. Positives Verstärkungslernen (PRL)
Positives Lernen bedeutet, einige Elemente hinzuzufügen, um die Wahrscheinlichkeit zu erhöhen, dass das erwartete Verhalten erneut auftritt. Diese Lernmethode beeinflusst das Verhalten des RL-Agenten positiv. PRL verbessert auch die Stärke bestimmter Verhaltensweisen Ihrer KI.
PRL-Art der Lernverstärkung sollte die KI darauf vorbereiten, sich für lange Zeit an Veränderungen anzupassen. Aber das Einbringen von zu viel positivem Lernen kann zu einer Überlastung der Zustände führen, die die Effizienz der KI verringern kann.

#2. Negatives Verstärkungslernen (NRL)
Wenn der RL-Algorithmus der KI hilft, ein negatives Verhalten zu vermeiden oder zu stoppen, lernt sie daraus und verbessert ihre zukünftigen Handlungen. Dies wird als negatives Lernen bezeichnet. Es stellt der KI nur eine begrenzte Intelligenz zur Verfügung, um bestimmte Verhaltensanforderungen zu erfüllen.
Reale Anwendungsfälle von Reinforcement Learning
#1. Entwickler von E-Commerce-Lösungen haben personalisierte Tools zum Vorschlagen von Produkten oder Dienstleistungen entwickelt. Sie können die API des Tools mit Ihrer Online-Shopping-Site verbinden. Dann lernt die KI von einzelnen Benutzern und schlägt kundenspezifische Waren und Dienstleistungen vor.
#2. Open-World-Videospiele bieten grenzenlose Möglichkeiten. Hinter dem Spielprogramm steckt jedoch ein KI-Programm, das aus den Eingaben der Spieler lernt und den Videospielcode modifiziert, um sich an eine unbekannte Situation anzupassen.
#3. KI-basierte Aktienhandels- und Anlageplattformen nutzen das RL-Modell, um aus der Bewegung von Aktien und globalen Indizes zu lernen. Dementsprechend formulieren sie ein Wahrscheinlichkeitsmodell, um Aktien für Investitionen oder den Handel vorzuschlagen.
#4. Online-Videobibliotheken wie YouTube, Metacafe, Dailymotion usw. verwenden KI-Bots, die nach dem RL-Modell trainiert wurden, um ihren Benutzern personalisierte Videos vorzuschlagen.
Verstärkungslernen vs. Überwachtes Lernen
Reinforcement Learning zielt darauf ab, den KI-Agenten zu trainieren, Entscheidungen sequentiell zu treffen. Kurz gesagt, Sie können davon ausgehen, dass die Ausgabe der KI vom Zustand der aktuellen Eingabe abhängt. In ähnlicher Weise hängt die nächste Eingabe in den RL-Algorithmus von der Ausgabe der vergangenen Eingaben ab.

Eine KI-basierte Robotermaschine, die eine Partie Schach gegen einen menschlichen Schachspieler spielt, ist ein Beispiel für das RL-Maschinenlernmodell.
Im Gegensatz dazu trainiert der Programmierer beim überwachten Lernen den KI-Agenten, Entscheidungen auf der Grundlage der zu Beginn gegebenen Eingaben oder anderer anfänglicher Eingaben zu treffen. Autonom fahrende KIs, die Umgebungsobjekte erkennen, sind ein hervorragendes Beispiel für überwachtes Lernen.
Verstärkungslernen vs. Unbeaufsichtigtes Lernen
Bisher haben Sie verstanden, dass die RL-Methode den KI-Agenten dazu bringt, von den Modellrichtlinien für maschinelles Lernen zu lernen. Hauptsächlich macht die KI nur die Schritte, für die sie maximale Belohnungspunkte erhält. RL hilft einer KI, sich durch Versuch und Irrtum zu improvisieren.
Andererseits führt der KI-Programmierer beim unüberwachten Lernen die KI-Software mit unbeschrifteten Daten ein. Außerdem sagt der ML-Lehrer der KI nichts über die Datenstruktur oder was in den Daten zu suchen ist. Der Algorithmus lernt verschiedene Entscheidungen, indem er seine eigenen Beobachtungen an den gegebenen unbekannten Datensätzen katalogisiert.
Kurse zur Verstärkung des Lernens
Nachdem Sie nun die Grundlagen gelernt haben, finden Sie hier einige Online-Kurse zum Erlernen des fortgeschrittenen Verstärkungslernens. Sie erhalten auch ein Zertifikat, das Sie auf LinkedIn oder anderen sozialen Plattformen präsentieren können:
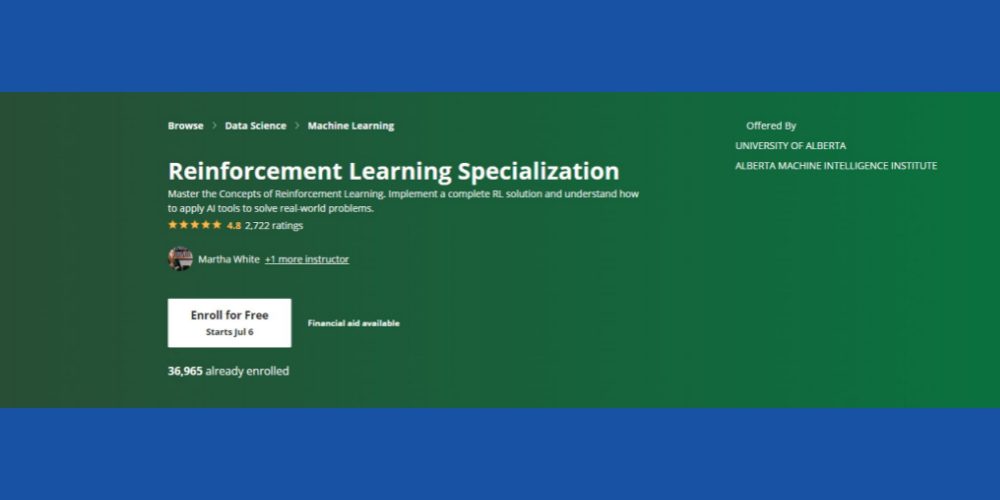
Spezialisierung auf verstärkendes Lernen: Coursera
Möchten Sie die Kernkonzepte des Reinforcement Learning mit ML-Kontext beherrschen? Sie können dies versuchen Coursera RL-Kurs das online verfügbar ist und eine Option zum selbstgesteuerten Lernen und zur Zertifizierung bietet. Der Kurs ist für Sie geeignet, wenn Sie folgende Vorkenntnisse mitbringen:
- Programmierkenntnisse in Python
- Statistische Grundbegriffe
- Sie können Pseudocodes und Algorithmen in Python-Codes umwandeln
- Softwareentwicklungserfahrung von zwei bis drei Jahren
- Auch Studierende im zweiten Studienjahr der Informatik sind förderfähig
Der Kurs hat eine Bewertung von 4,8 Sternen und über 36.000 Studenten haben sich bereits in verschiedenen Kursen für den Kurs eingeschrieben. Darüber hinaus wird der Kurs finanziell unterstützt, sofern der Kandidat bestimmte Zulassungskriterien von Coursera erfüllt.
Schließlich bietet das Alberta Machine Intelligence Institute der University of Alberta diesen Kurs an (keine Kreditvergabe). Renommierte Professoren der Informatik fungieren als Ihre Kursleiter. Nach Abschluss des Kurses erhalten Sie ein Coursera-Zertifikat.
KI-Verstärkungslernen in Python: Udemy
Wenn Sie sich mit Finanzmarkt oder digitalem Marketing beschäftigen und intelligente Softwarepakete für die genannten Bereiche entwickeln möchten, müssen Sie sich das ansehen Udemy-Kurs auf RL. Neben den Kernprinzipien von RL werden Sie in den Schulungsinhalten auch darin geschult, RL-Lösungen für Online-Werbung und Aktienhandel zu entwickeln.

Einige bemerkenswerte Themen, die der Kurs abdeckt, sind:
- Eine allgemeine Übersicht über RL
- Dynamische Programmierung
- Monet Carlo
- Näherungsverfahren
- Aktienhandelsprojekt mit RL
Bisher haben über 42.000 Studenten an dem Kurs teilgenommen. Die Online-Lernressource hat derzeit eine Bewertung von 4,6 Sternen, was ziemlich beeindruckend ist. Darüber hinaus zielt der Kurs darauf ab, eine globale Studentengemeinschaft anzusprechen, da die Lerninhalte in Französisch, Englisch, Spanisch, Deutsch, Italienisch und Portugiesisch verfügbar sind.
Deep Reinforcement Learning in Python: Udemy
Wenn Sie neugierig sind und Grundkenntnisse in Deep Learning und künstlicher Intelligenz haben, können Sie dies für Fortgeschrittene ausprobieren RL-Kurs in Python von Udemy. Mit einer 4,6-Sterne-Bewertung von Studenten ist es ein weiterer beliebter Kurs, um RL im Kontext von AI/ML zu lernen.

Der Kurs besteht aus 12 Abschnitten und behandelt die folgenden wichtigen Themen:
- OpenAI Gym und grundlegende RL-Techniken
- TD Lambda
- A3C
- Theano-Grundlagen
- Tensorflow-Grundlagen
- Python-Codierung für den Anfang
Der gesamte Kurs erfordert eine engagierte Investition von 10 Stunden und 40 Minuten. Neben Texten enthält es auch 79 Expertenvorträge.
Experte für Deep Reinforcement Learning: Udacity
Möchten Sie fortgeschrittenes maschinelles Lernen von den weltweit führenden Anbietern von KI/ML wie dem Nvidia Deep Learning Institute und Unity lernen? Mit Udacity können Sie sich Ihren Traum erfüllen. Schau dir das an Tiefes Verstärkungslernen Kurs zum ML-Experten.

Sie müssen jedoch über einen Hintergrund in fortgeschrittenem Python, fortgeschrittener Statistik, Wahrscheinlichkeitstheorie, TensorFlow, PyTorch und Keras verfügen.
Es wird fleißiges Lernen von bis zu 4 Monaten erfordern, um den Kurs abzuschließen. Während des gesamten Kurses lernen Sie wichtige RL-Algorithmen wie Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) usw.
Letzte Worte
Reinforcement Learning ist der nächste Schritt in der KI-Entwicklung. KI-Entwicklungsagenturen und IT-Unternehmen investieren in diesen Sektor, um zuverlässige und vertrauenswürdige KI-Trainingsmethoden zu entwickeln.
Obwohl RL sehr weit fortgeschritten ist, gibt es mehr Entwicklungsspielräume. Zum Beispiel teilen getrennte RL-Agenten ihr Wissen nicht untereinander. Wenn Sie also einer App das Autofahren beibringen, wird der Lernprozess langsam. Weil RL-Agenten wie Objekterkennung, Straßenreferenzen usw. keine Daten teilen.
Es gibt Möglichkeiten, Ihre Kreativität und ML-Expertise in solche Herausforderungen zu investieren. Wenn Sie sich für Online-Kurse anmelden, können Sie Ihr Wissen über fortgeschrittene RL-Methoden und deren Anwendungen in realen Projekten erweitern.
Ein weiteres verwandtes Lernen für Sie sind die Unterschiede zwischen KI, maschinellem Lernen und Deep Learning.