

Data Science ist für alle, die es lieben, verworrene Dinge zu entwirren und versteckte Wunder in einem scheinbaren Durcheinander zu entdecken.
Es ist wie die Suche nach Nadeln im Heuhaufen; nur dass Data Scientists sich überhaupt nicht die Hände schmutzig machen müssen. Mit ausgefallenen Tools mit farbenfrohen Diagrammen und einem Blick auf Haufen von Zahlen tauchen sie einfach in Datenheuhaufen ein und finden wertvolle Nadeln in Form von Erkenntnissen mit hohem Geschäftswert.
Ein typisches Datenwissenschaftler Die Toolbox sollte mindestens ein Element aus jeder dieser Kategorien enthalten: relationale Datenbanken, NoSQL-Datenbanken, Big-Data-Frameworks, Visualisierungstools, Scraping-Tools, Programmiersprachen, IDEs und Deep-Learning-Tools.
Inhaltsverzeichnis
Relationale Datenbanken
Eine relationale Datenbank ist eine Sammlung von Daten, die in Tabellen mit Attributen strukturiert sind. Die Tabellen können miteinander verknüpft werden, Beziehungen und Einschränkungen definieren und ein sogenanntes Datenmodell erstellen. Um mit relationalen Datenbanken zu arbeiten, verwenden Sie üblicherweise eine Sprache namens SQL (Structured Query Language).
Die Anwendungen, die die Struktur und Daten in relationalen Datenbanken verwalten, heißen RDBMS (Relational DataBase Management Systems). Es gibt viele solcher Anwendungen, und die relevantesten haben kürzlich damit begonnen, ihren Schwerpunkt auf den Bereich der Datenwissenschaft zu legen, indem sie Funktionen für die Arbeit mit Big-Data-Repositories und die Anwendung von Techniken wie Datenanalyse und maschinellem Lernen hinzugefügt haben.
SQL Server
RDBMS von Microsoft, entwickelt sich seit mehr als 20 Jahren weiter, indem es seine Enterprise-Funktionalität konsequent erweitert. Seit der Version 2016 bietet SQL Server ein Portfolio von Diensten, die die Unterstützung für eingebetteten R-Code umfassen. SQL Server 2017 erhöht die Wette, indem es seine R-Dienste in Machine Language Services umbenennt und Unterstützung für die Python-Sprache hinzufügt (mehr zu diesen beiden Sprachen weiter unten).
Mit diesen wichtigen Ergänzungen richtet sich SQL Server an Data Scientists, die möglicherweise keine Erfahrung mit Transact SQL, der nativen Abfragesprache von Microsoft SQL Server, haben.
SQL Server ist weit davon entfernt, ein kostenloses Produkt zu sein. Sie können Lizenzen kaufen, um es auf einem Windows-Server zu installieren (der Preis variiert je nach Anzahl der gleichzeitigen Benutzer) oder es als kostenpflichtigen Dienst über die Microsoft Azure-Cloud nutzen. Das Erlernen von Microsoft SQL Server ist einfach.
MySQL
Auf der Seite der Open-Source-Software MySQL hat die Popularitätskrone von RDBMSs. Obwohl Oracle es derzeit besitzt, ist es immer noch kostenlos und Open-Source unter den Bedingungen einer GNU General Public License. Die meisten webbasierten Anwendungen verwenden MySQL als zugrunde liegendes Datenrepository, da es dem SQL-Standard entspricht.
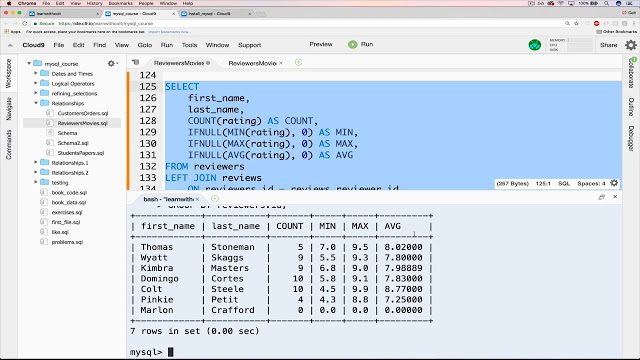
Zu seiner Popularität tragen auch seine einfachen Installationsverfahren, seine große Community von Entwicklern, jede Menge umfassende Dokumentation und Tools von Drittanbietern wie phpMyAdmin bei, die die täglichen Verwaltungsaktivitäten vereinfachen. Obwohl MySQL keine nativen Funktionen für die Datenanalyse hat, ermöglicht seine Offenheit die Integration mit fast jedem Visualisierungs-, Berichts- und Business-Intelligence-Tool Ihrer Wahl.
PostgreSQL
Eine weitere Open-Source-RDBMS-Option ist PostgreSQL. Obwohl nicht so beliebt wie MySQL, zeichnet sich PostgreSQL durch seine Flexibilität und Erweiterbarkeit sowie seine Unterstützung für komplexe Abfragen aus, die über die grundlegenden Anweisungen wie SELECT, WHERE und GROUP BY hinausgehen.
Diese Funktionen lassen es bei Datenwissenschaftlern an Popularität gewinnen. Ein weiteres interessantes Feature ist die Unterstützung für mehrere Umgebungen, die den Einsatz in Cloud- und On-Premise-Umgebungen oder in einer Mischung aus beidem, allgemein bekannt als hybride Cloud-Umgebungen, ermöglicht.
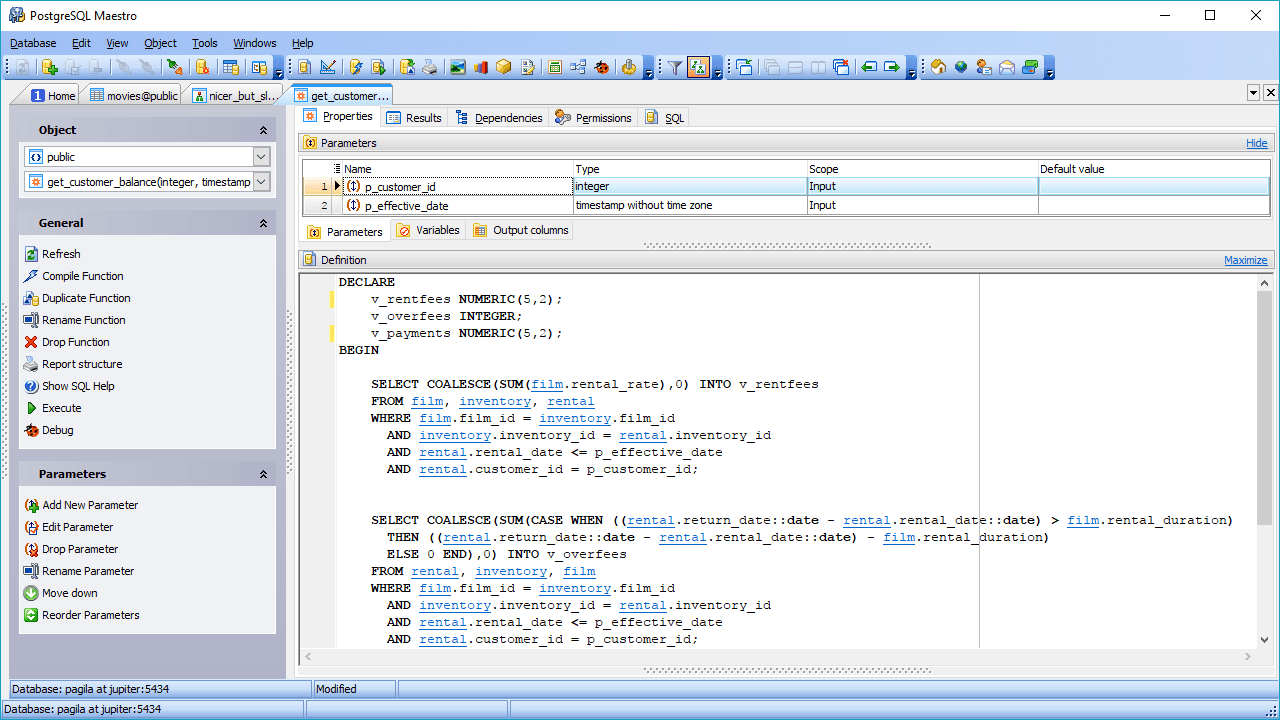
PostgreSQL ist in der Lage, Online Analytical Processing (OLAP) mit Online Transaction Processing (OLTP) zu kombinieren und in einem Modus zu arbeiten, der als Hybrid Transactional/Analytical Processing (HTAP) bezeichnet wird. Dank der Hinzufügung von PostGIS für geografische Daten und JSON-B für Dokumente eignet es sich auch gut für die Arbeit mit Big Data. PostgreSQL unterstützt auch unstrukturierte Daten, wodurch sie in beide Kategorien fallen können: SQL- und NoSQL-Datenbanken.
NoSQL-Datenbanken
Diese Art von Datenrepository, die auch als nicht relationale Datenbanken bezeichnet wird, bietet einen schnelleren Zugriff auf nicht tabellarische Datenstrukturen. Einige Beispiele für diese Strukturen sind unter anderem Diagramme, Dokumente, breite Spalten, Schlüsselwerte. NoSQL-Datenspeicher können die Datenkonsistenz zugunsten anderer Vorteile wie Verfügbarkeit, Partitionierung und Zugriffsgeschwindigkeit aufheben.
Da es in NoSQL-Datenspeichern kein SQL gibt, ist die einzige Möglichkeit, diese Art von Datenbank abzufragen, die Verwendung von Low-Level-Sprachen, und es gibt keine solche Sprache, die so weit verbreitet ist wie SQL. Außerdem gibt es keine Standardspezifikationen für NoSQL. Aus diesem Grund fangen ironischerweise einige NoSQL-Datenbanken an, Unterstützung für SQL-Skripte hinzuzufügen.
MongoDB
MongoDB ist ein beliebtes NoSQL-Datenbanksystem, das Daten in Form von JSON-Dokumenten speichert. Der Fokus liegt auf der Skalierbarkeit und der Flexibilität, Daten unstrukturiert zu speichern. Das bedeutet, dass es keine feste Feldliste gibt, die bei allen hinterlegten Elementen beachtet werden muss. Darüber hinaus kann sich die Datenstruktur im Laufe der Zeit ändern, was in einer relationalen Datenbank ein hohes Risiko birgt, laufende Anwendungen zu beeinträchtigen.

Die Technologie in MongoDB ermöglicht Indizierung, Ad-hoc-Abfragen und Aggregation, die eine starke Grundlage für die Datenanalyse bieten. Die verteilte Natur der Datenbank bietet hohe Verfügbarkeit, Skalierung und geografische Verteilung, ohne dass anspruchsvolle Tools erforderlich sind.
Redis
Dies one ist eine weitere Option in der Open-Source-NoSQL-Front. Es ist im Grunde ein Datenstrukturspeicher, der im Speicher arbeitet und neben der Bereitstellung von Datenbankdiensten auch als Cache-Speicher und Nachrichtenbroker fungiert.

Es unterstützt eine Vielzahl unkonventioneller Datenstrukturen, darunter Hashes, Geodaten-Indizes, Listen und sortierte Sätze. Es eignet sich dank seiner hohen Leistung bei datenintensiven Aufgaben wie dem Berechnen von Satzschnittpunkten, dem Sortieren langer Listen oder dem Erstellen komplexer Rankings gut für die Datenwissenschaft. Der Grund für die herausragende Leistung von Redis ist der In-Memory-Betrieb. Es kann so konfiguriert werden, dass die Daten selektiv gespeichert werden.
Big-Data-Frameworks
Angenommen, Sie müssen die Daten analysieren, die Facebook-Nutzer im Laufe eines Monats generieren. Wir sprechen über Fotos, Videos, Nachrichten, alles. Wenn man bedenkt, dass jeden Tag mehr als 500 Terabyte an Daten von den Nutzern des sozialen Netzwerks hinzugefügt werden, ist es schwierig, das Datenvolumen eines ganzen Monats zu messen.
Um diese riesige Datenmenge effektiv zu bearbeiten, benötigen Sie ein geeignetes Framework, das in der Lage ist, Statistiken über eine verteilte Architektur zu berechnen. Es gibt zwei der marktführenden Frameworks: Hadoop und Spark.
Hadoop
Als Big-Data-Framework Hadoop befasst sich mit der Komplexität, die mit dem Abrufen, Verarbeiten und Speichern riesiger Datenmengen verbunden ist. Hadoop arbeitet in einer verteilten Umgebung, die aus Computerclustern besteht, die einfache Algorithmen verarbeiten. Es gibt einen Orchestrierungsalgorithmus namens MapReduce, der große Aufgaben in kleine Teile aufteilt und diese kleinen Aufgaben dann zwischen verfügbaren Clustern verteilt.

Hadoop wird für Datenrepositorys der Enterprise-Klasse empfohlen, die schnellen Zugriff und hohe Verfügbarkeit erfordern, und das alles in einem kostengünstigen Schema. Aber Sie brauchen einen Linux-Admin mit Deep Hadoop-Kenntnisse um das Framework aufrechtzuerhalten und auszuführen.
Funke
Hadoop ist nicht das einzige verfügbare Framework für die Manipulation von Big Data. Ein weiterer großer Name in diesem Bereich ist Funke. Die Spark-Engine wurde entwickelt, um Hadoop in Bezug auf Analysegeschwindigkeit und Benutzerfreundlichkeit zu übertreffen. Anscheinend hat es dieses Ziel erreicht: Einige Vergleiche besagen, dass Spark beim Arbeiten auf einer Festplatte bis zu 10-mal schneller läuft als Hadoop und 100-mal schneller im Arbeitsspeicher arbeitet. Es erfordert auch eine geringere Anzahl von Maschinen, um die gleiche Datenmenge zu verarbeiten.

Neben der Geschwindigkeit ist ein weiterer Vorteil von Spark die Unterstützung der Stream-Verarbeitung. Bei dieser Art der Datenverarbeitung, auch Echtzeitverarbeitung genannt, handelt es sich um eine kontinuierliche Ein- und Ausgabe von Daten.
Visualisierungstools
Ein häufiger Witz unter Datenwissenschaftlern besagt, dass, wenn Sie die Daten lange genug quälen, sie preisgeben, was Sie wissen müssen. „Folter“ bedeutet in diesem Fall, die Daten durch Transformation und Filterung zu manipulieren, um sie besser visualisieren zu können. Und hier kommen Datenvisualisierungstools ins Spiel. Diese Tools nehmen vorverarbeitete Daten aus mehreren Quellen und zeigen ihre offenbarten Wahrheiten in grafischer, verständlicher Form.
Es gibt Hunderte von Tools, die in diese Kategorie fallen. Ob es Ihnen gefällt oder nicht, am weitesten verbreitet ist Microsoft Excel und seine Diagrammtools. Excel-Diagramme sind für jeden zugänglich, der Excel verwendet, aber sie haben eine eingeschränkte Funktionalität. Gleiches gilt für andere Tabellenkalkulationsanwendungen wie Google Sheets und Libre Office. Aber wir sprechen hier von spezifischeren Tools, die speziell auf Business Intelligence (BI) und Datenanalyse zugeschnitten sind.
PowerBI
Vor nicht allzu langer Zeit veröffentlichte Microsoft seine PowerBI Visualisierungsanwendung. Es kann Daten aus verschiedenen Quellen wie Textdateien, Datenbanken, Tabellenkalkulationen und vielen Online-Datendiensten, einschließlich Facebook und Twitter, verwenden und daraus Dashboards mit Diagrammen, Tabellen, Karten und vielen anderen Visualisierungsobjekten erstellen. Die Dashboard-Objekte sind interaktiv, d. h. Sie können auf eine Datenreihe in einem Diagramm klicken, um sie auszuwählen und als Filter für die anderen Objekte auf dem Board zu verwenden.
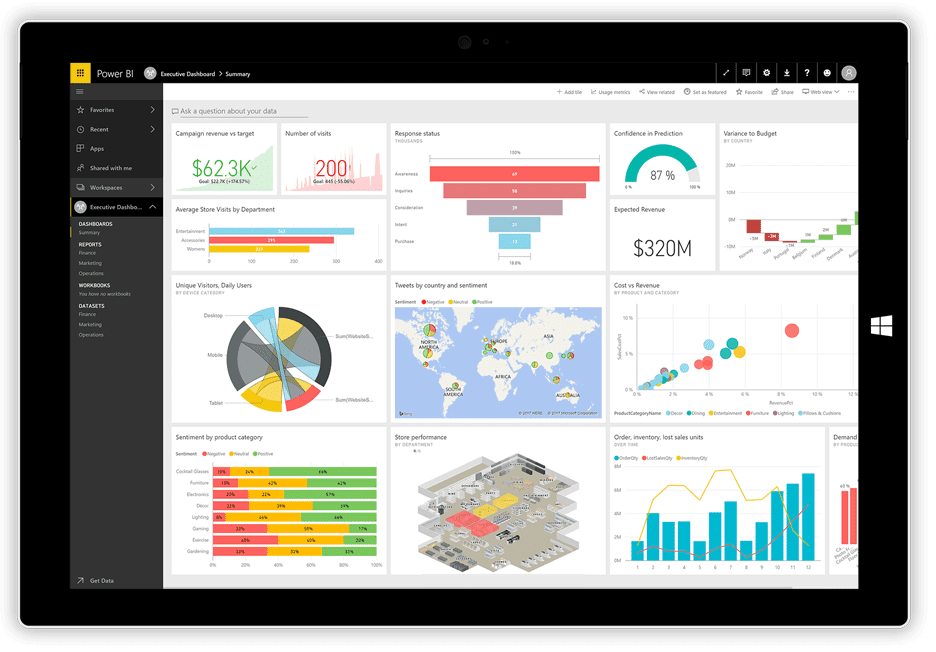
Power BI ist eine Kombination aus einer Windows-Desktopanwendung (Teil der Office 365-Suite), einer Webanwendung und einem Onlinedienst, um die Dashboards im Web zu veröffentlichen und sie mit Ihren Benutzern zu teilen. Mit dem Dienst können Sie Berechtigungen erstellen und verwalten, um nur bestimmten Personen Zugriff auf die Boards zu gewähren.
Tableau
Tableau ist eine weitere Möglichkeit, interaktive Dashboards aus einer Kombination mehrerer Datenquellen zu erstellen. Es bietet auch eine Desktop-Version, eine Web-Version und einen Online-Dienst, um die von Ihnen erstellten Dashboards zu teilen. Es funktioniert auf natürliche Weise „mit der Art und Weise, wie Sie denken“ (wie es behauptet) und ist für technisch nicht versierte Personen einfach zu verwenden, was durch viele Tutorials und Online-Videos verbessert wird.
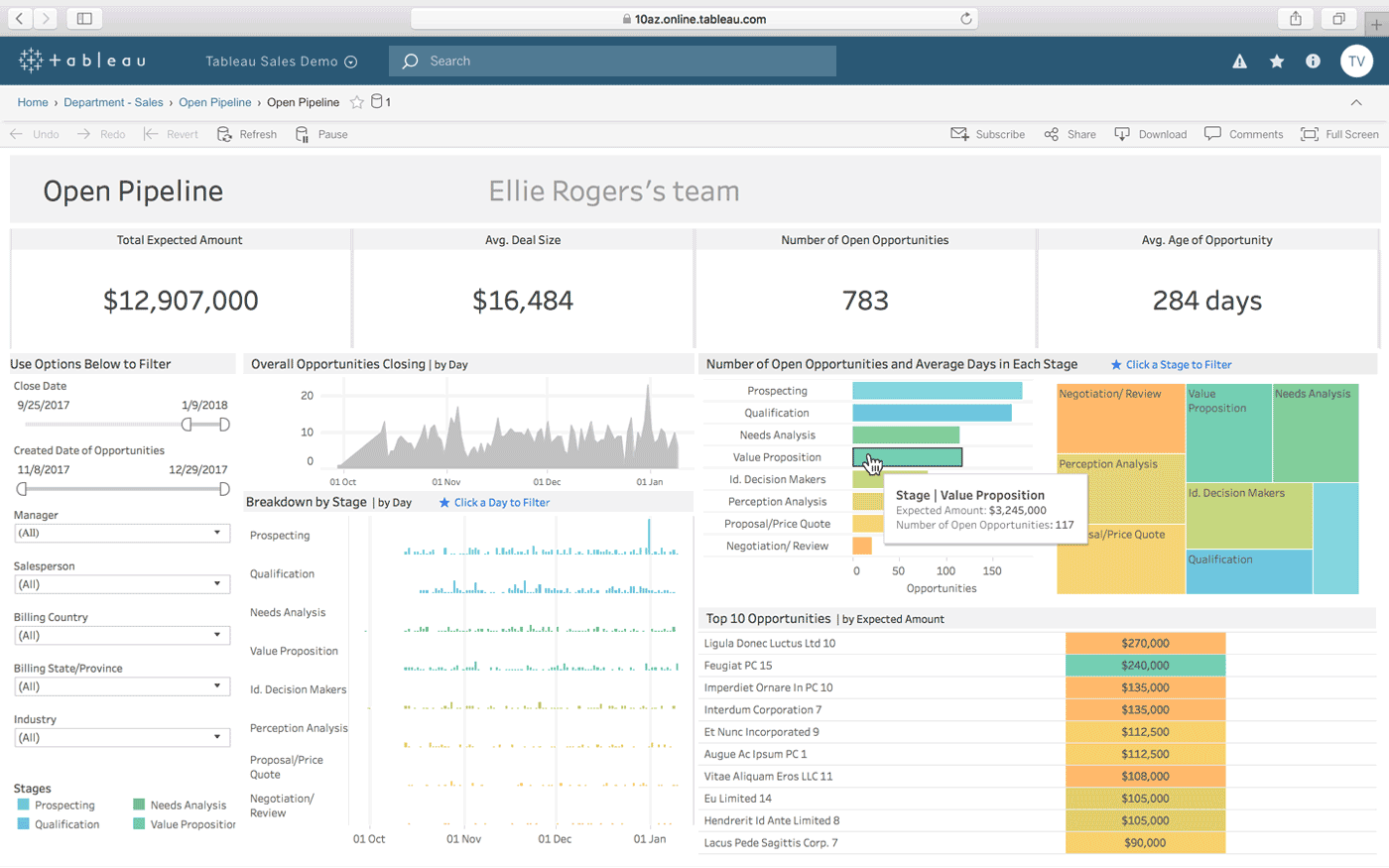
Einige der herausragendsten Merkmale von Tableau sind seine unbegrenzten Datenkonnektoren, seine Live- und In-Memory-Daten und seine für Mobilgeräte optimierten Designs.
QlikView
QlikView bietet eine übersichtliche und unkomplizierte Benutzeroberfläche, die Analysten hilft, neue Erkenntnisse aus vorhandenen Daten durch visuelle Elemente zu gewinnen, die für jeden leicht verständlich sind.
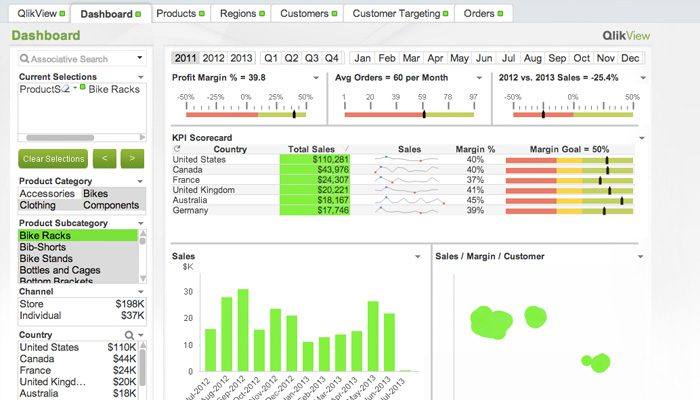
Dieses Tool ist als eine der flexibelsten Business-Intelligence-Plattformen bekannt. Es bietet eine Funktion namens Assoziative Suche, die Ihnen hilft, sich auf die wichtigsten Daten zu konzentrieren und Ihnen die Zeit erspart, die Sie benötigen würden, um sie selbst zu finden.
Mit QlikView können Sie in Echtzeit mit Partnern zusammenarbeiten und vergleichende Analysen durchführen. Alle relevanten Daten können in einer App kombiniert werden, mit Sicherheitsfunktionen, die den Zugriff auf die Daten einschränken.
Schabwerkzeuge
In den Zeiten, als das Internet gerade erst aufkam, begannen die Webcrawler zusammen mit den Netzwerken zu reisen und Informationen auf ihre Weise zu sammeln. Als sich die Technologie weiterentwickelte, änderte sich der Begriff Web-Crawling für Web Scraping, bedeutet aber immer noch dasselbe: Informationen automatisch von Websites zu extrahieren. Um Web Scraping durchzuführen, verwenden Sie automatisierte Prozesse oder Bots, die von einer Webseite zur anderen springen, Daten daraus extrahieren und sie in verschiedene Formate exportieren oder sie zur weiteren Analyse in Datenbanken einfügen.
Im Folgenden fassen wir die Eigenschaften von drei der beliebtesten Web Scraper zusammen, die heute erhältlich sind.
Oktoparse
Oktoparse Web Scraper bietet einige interessante Eigenschaften, einschließlich integrierter Tools, um Informationen von Websites zu erhalten, die es Scraping-Bots nicht leicht machen, ihre Arbeit zu erledigen. Es handelt sich um eine Desktop-Anwendung, die keine Programmierung erfordert, mit einer benutzerfreundlichen Benutzeroberfläche, die die Visualisierung des Extraktionsprozesses durch einen grafischen Workflow-Designer ermöglicht.
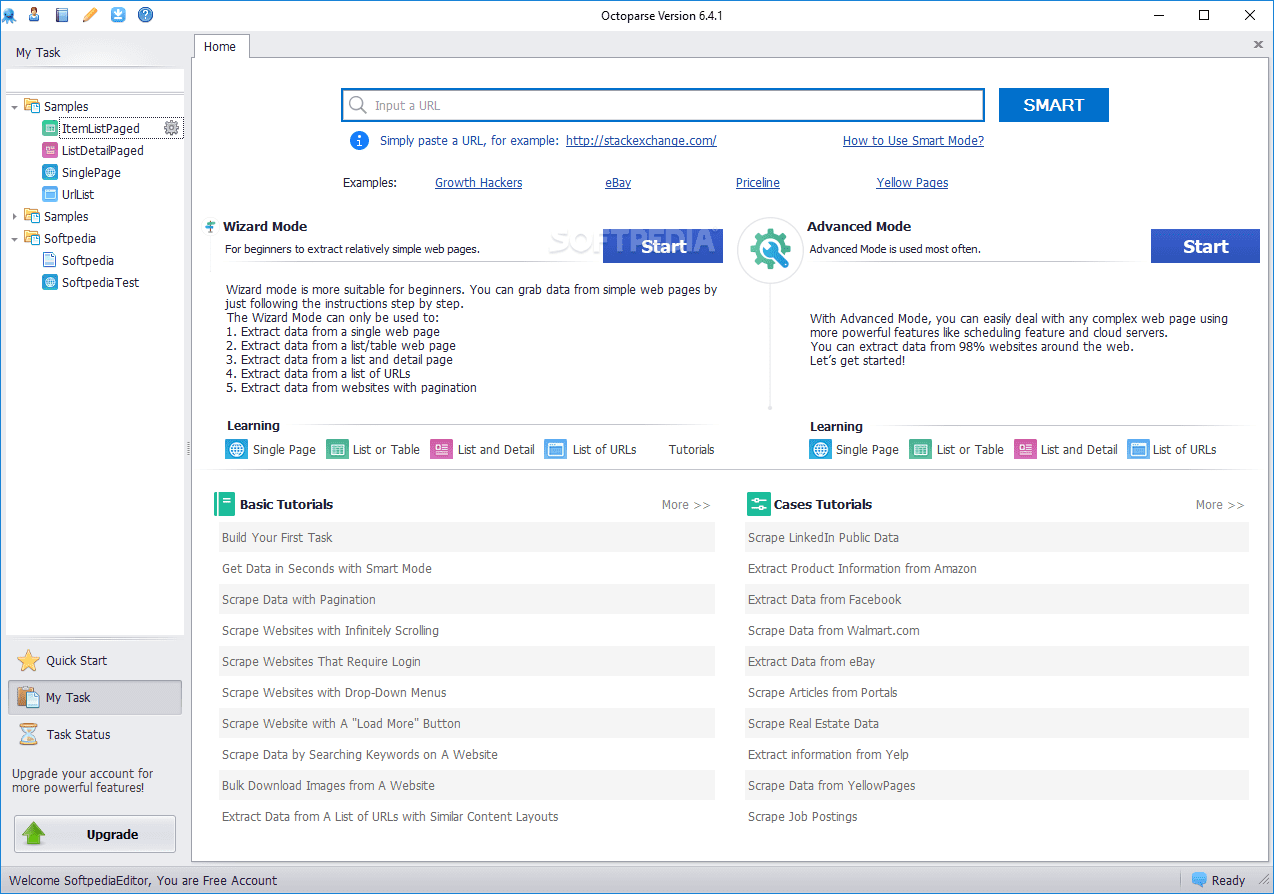
Zusammen mit der eigenständigen Anwendung bietet Octoparse einen Cloud-basierten Dienst zur Beschleunigung des Datenextraktionsprozesses. Benutzer können einen 4- bis 10-fachen Geschwindigkeitsgewinn erleben, wenn sie den Cloud-Dienst anstelle der Desktop-Anwendung verwenden. Wenn Sie sich an die Desktop-Version halten, können Sie Octoparse kostenlos verwenden. Wenn Sie jedoch lieber den Cloud-Dienst nutzen möchten, müssen Sie einen der kostenpflichtigen Tarife auswählen.
Content-Grabber
Wenn Sie nach einem funktionsreichen Scraping-Tool suchen, sollten Sie ein Auge darauf werfen Content-Grabber. Im Gegensatz zu Octoparse sind für die Verwendung von Content Grabber fortgeschrittene Programmierkenntnisse erforderlich. Im Gegenzug erhalten Sie Skriptbearbeitung, Debugging-Schnittstellen und andere erweiterte Funktionen. Mit Content Grabber können Sie .Net-Sprachen verwenden, um reguläre Ausdrücke zu schreiben. Auf diese Weise müssen Sie die Ausdrücke nicht mit einem integrierten Tool generieren.
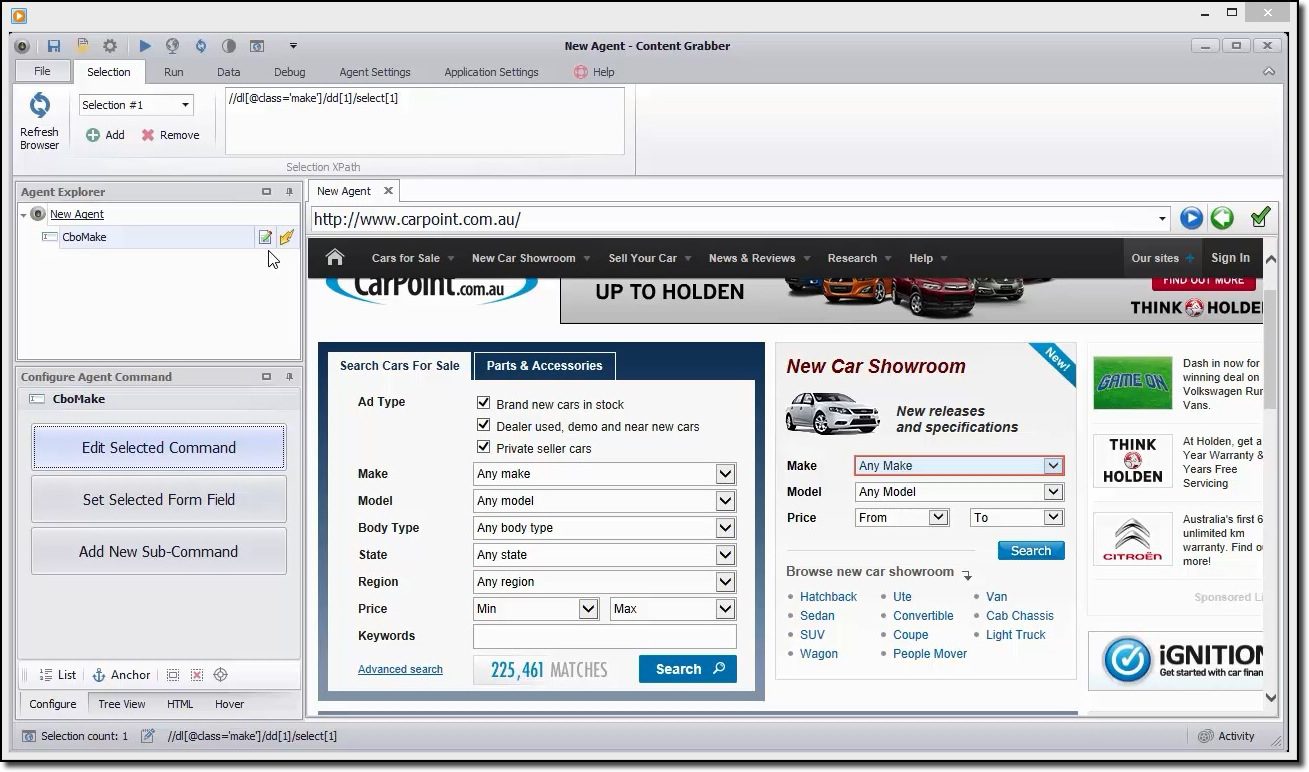
Das Tool bietet eine API (Application Programming Interface), mit der Sie Ihren Desktop- und Webanwendungen Scraping-Funktionen hinzufügen können. Um diese API verwenden zu können, müssen Entwickler Zugriff auf den Windows-Dienst Content Grabber erhalten.
ParseHub
Dieser Schaber kann eine umfangreiche Liste verschiedener Inhaltstypen verarbeiten, darunter Foren, verschachtelte Kommentare, Kalender und Karten. Es kann auch mit Seiten umgehen, die Authentifizierung, Javascript, Ajax und mehr enthalten. ParseHub kann als Web-App oder Desktop-Anwendung verwendet werden, die unter Windows, macOS X und Linux ausgeführt werden kann.
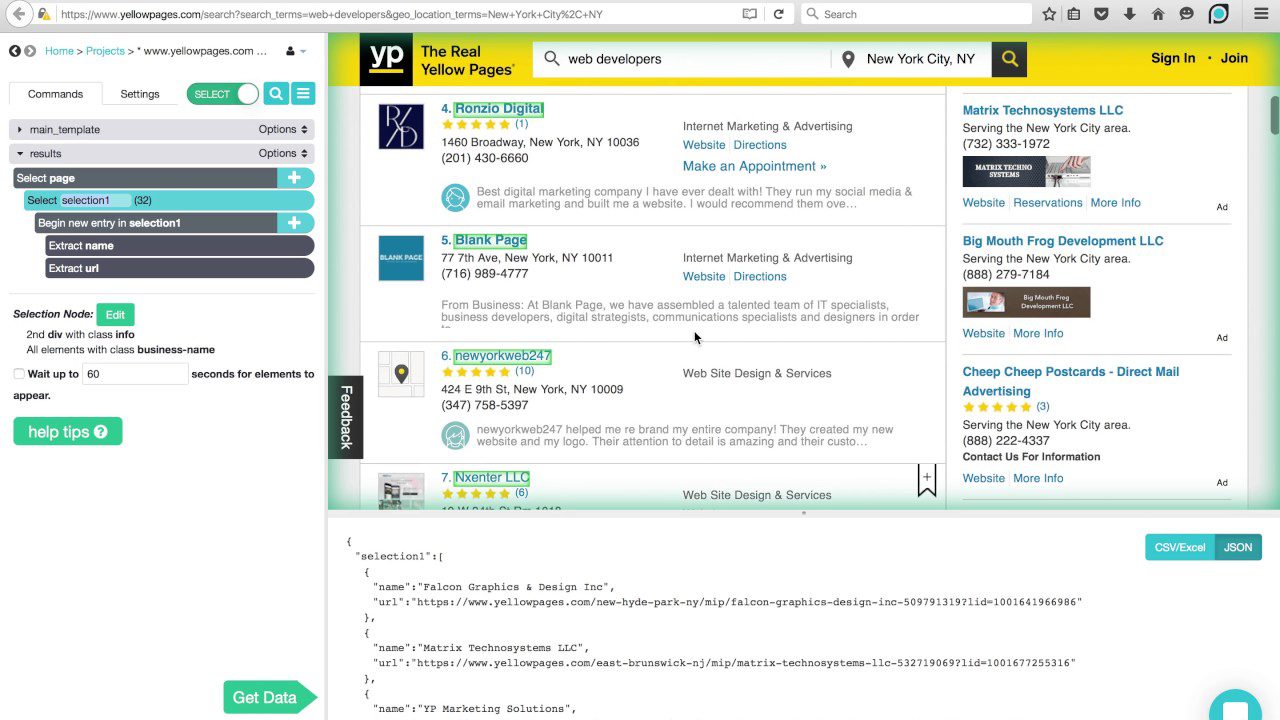
Wie bei Content Grabber wird empfohlen, über Programmierkenntnisse zu verfügen, um ParseHub optimal nutzen zu können. Es hat eine kostenlose Version, die auf 5 Projekte und 200 Seiten pro Lauf begrenzt ist.
Programmiersprachen
So wie die zuvor erwähnte SQL-Sprache speziell für die Arbeit mit relationalen Datenbanken entwickelt wurde, gibt es andere Sprachen, die mit einem klaren Fokus auf Data Science erstellt wurden. Diese Sprachen ermöglichen es den Entwicklern, Programme zu schreiben, die sich mit massiver Datenanalyse befassen, wie z. B. Statistiken und maschinelles Lernen.
SQL wird auch als eine wichtige Fähigkeit angesehen, die Entwickler haben sollten, um Data Science zu betreiben, aber das liegt daran, dass die meisten Organisationen immer noch viele Daten in relationalen Datenbanken haben. „Echte“ Data-Science-Sprachen sind R und Python.
Python

Python ist eine hochrangige, interpretierte, universelle Programmiersprache, die sich gut für die schnelle Anwendungsentwicklung eignet. Es hat eine einfache und leicht zu erlernende Syntax, die eine steile Lernkurve und eine Verringerung der Kosten für die Programmwartung ermöglicht. Es gibt viele Gründe, warum es die bevorzugte Sprache für Data Science ist. Um nur einige zu nennen: Skripting-Potenzial, Ausführlichkeit, Portabilität und Leistung.
Diese Sprache ist ein guter Ausgangspunkt für Data Scientists, die vorhaben, viel zu experimentieren, bevor sie sich in die echte und harte Datenverarbeitungsarbeit stürzen, und die vollständige Anwendungen entwickeln möchten.
R
Das R-Sprache wird hauptsächlich für statistische Datenverarbeitung und grafische Darstellung verwendet. Obwohl es nicht dazu gedacht ist, vollwertige Anwendungen zu entwickeln, wie es bei Python der Fall wäre, ist R in den letzten Jahren aufgrund seines Potenzials für Data Mining und Data Analytics sehr populär geworden.

Dank einer ständig wachsenden Bibliothek frei verfügbarer Pakete, die seine Funktionalität erweitern, ist R in der Lage, alle Arten von datenintensiven Arbeiten durchzuführen, einschließlich linearer/nichtlinearer Modellierung, Klassifizierung, statistischer Tests usw.
Es ist keine leicht zu erlernende Sprache, aber sobald Sie sich mit ihrer Philosophie vertraut gemacht haben, werden Sie statistische Berechnungen wie ein Profi durchführen.
IDEs
Wenn Sie ernsthaft erwägen, sich der Datenwissenschaft zu widmen, müssen Sie sorgfältig eine integrierte Entwicklungsumgebung (IDE) auswählen, die Ihren Anforderungen entspricht, da Sie und Ihre IDE viel Zeit für die Zusammenarbeit aufwenden werden.
Eine ideale IDE sollte alle Tools zusammenstellen, die Sie in Ihrer täglichen Arbeit als Programmierer benötigen: einen Texteditor mit Syntaxhervorhebung und Autovervollständigung, einen leistungsstarken Debugger, einen Objektbrowser und einen einfachen Zugriff auf externe Tools. Außerdem muss es mit der von Ihnen bevorzugten Sprache kompatibel sein, daher ist es eine gute Idee, Ihre IDE auszuwählen, nachdem Sie wissen, welche Sprache Sie verwenden werden.
Spyder
Dies Die generische IDE ist hauptsächlich für Wissenschaftler und Analysten gedacht, die auch programmieren müssen. Um es ihnen bequem zu machen, beschränkt es sich nicht auf die IDE-Funktionalität – es bietet auch Tools für die Datenexploration/Visualisierung und interaktive Ausführung, wie man sie auf einem wissenschaftlichen Paket finden könnte. Der Editor in Spyder unterstützt mehrere Sprachen und fügt einen Klassenbrowser, Fensteraufteilung, Jump-to-Definition, automatische Codevervollständigung und sogar ein Codeanalysetool hinzu.
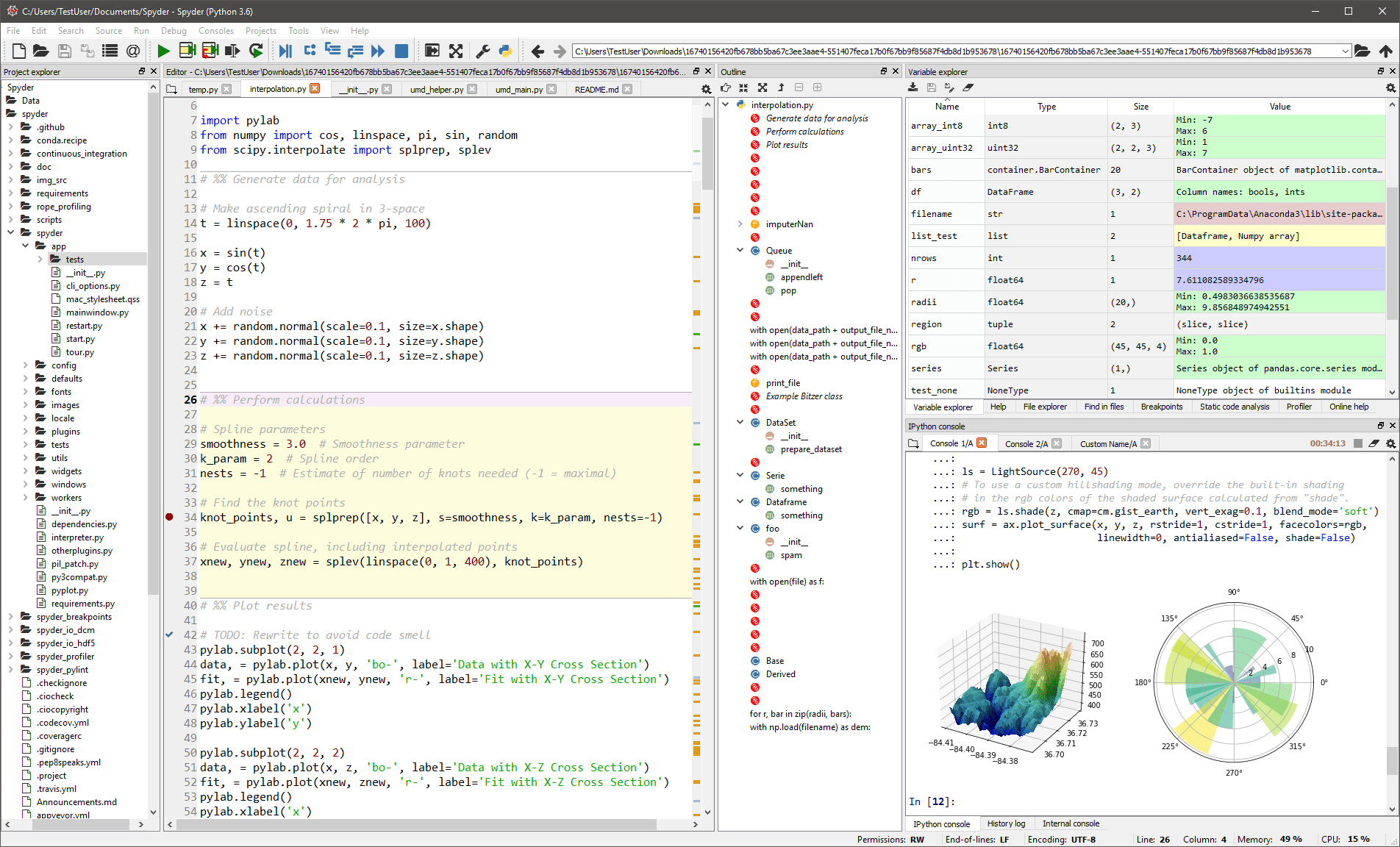
Der Debugger hilft Ihnen, jede Codezeile interaktiv zu verfolgen, und ein Profiler hilft Ihnen, Ineffizienzen zu finden und zu beseitigen.
PyCharm
Wenn Sie in Python programmieren, ist dies wahrscheinlich die IDE Ihrer Wahl PyCharm. Es verfügt über einen intelligenten Code-Editor mit intelligenter Suche, Code-Vervollständigung sowie Fehlererkennung und -behebung. Mit nur einem Klick können Sie vom Code-Editor zu jedem kontextbezogenen Fenster springen, einschließlich Test, Super-Methode, Implementierung, Deklaration und mehr. PyCharm unterstützt Anaconda und viele wissenschaftliche Pakete wie NumPy und Matplotlib, um nur zwei davon zu nennen.
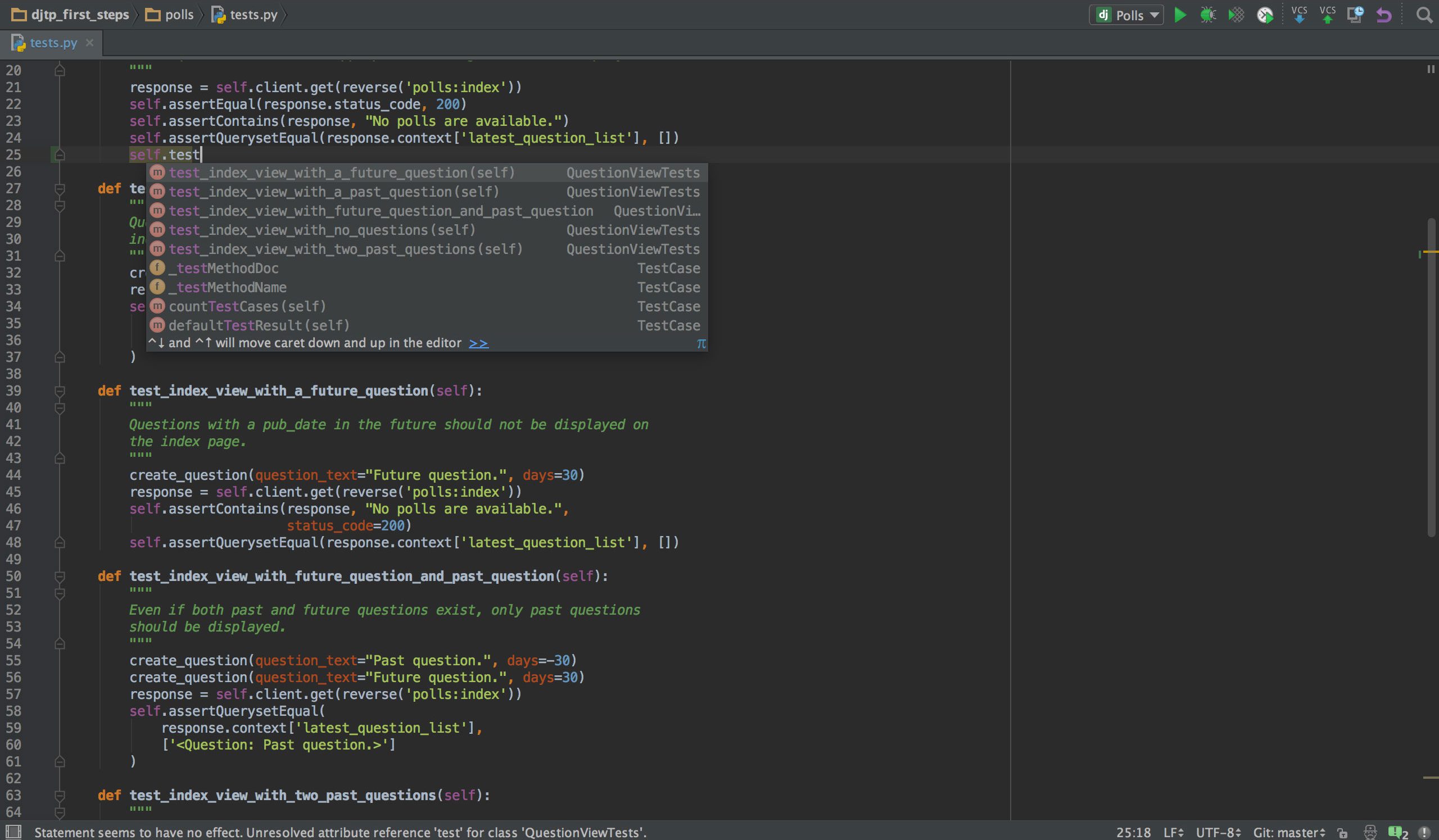
Es bietet Integration mit den wichtigsten Versionskontrollsystemen sowie mit einem Testrunner, einem Profiler und einem Debugger. Um das Geschäft abzuschließen, integriert es sich auch in Docker und Vagrant, um eine plattformübergreifende Entwicklung und Containerisierung zu ermöglichen.
RStudio
Für diejenigen Data Scientists, die das R-Team bevorzugen, sollte die IDE der Wahl sein RStudio, wegen seiner vielen Funktionen. Sie können es auf einem Desktop mit Windows, macOS oder Linux installieren oder es über einen Webbrowser ausführen, wenn Sie es nicht lokal installieren möchten. Beide Versionen bieten Extras wie Syntaxhervorhebung, intelligente Einrückung und Codevervollständigung. Es gibt einen integrierten Datenbetrachter, der praktisch ist, wenn Sie tabellarische Daten durchsuchen müssen.
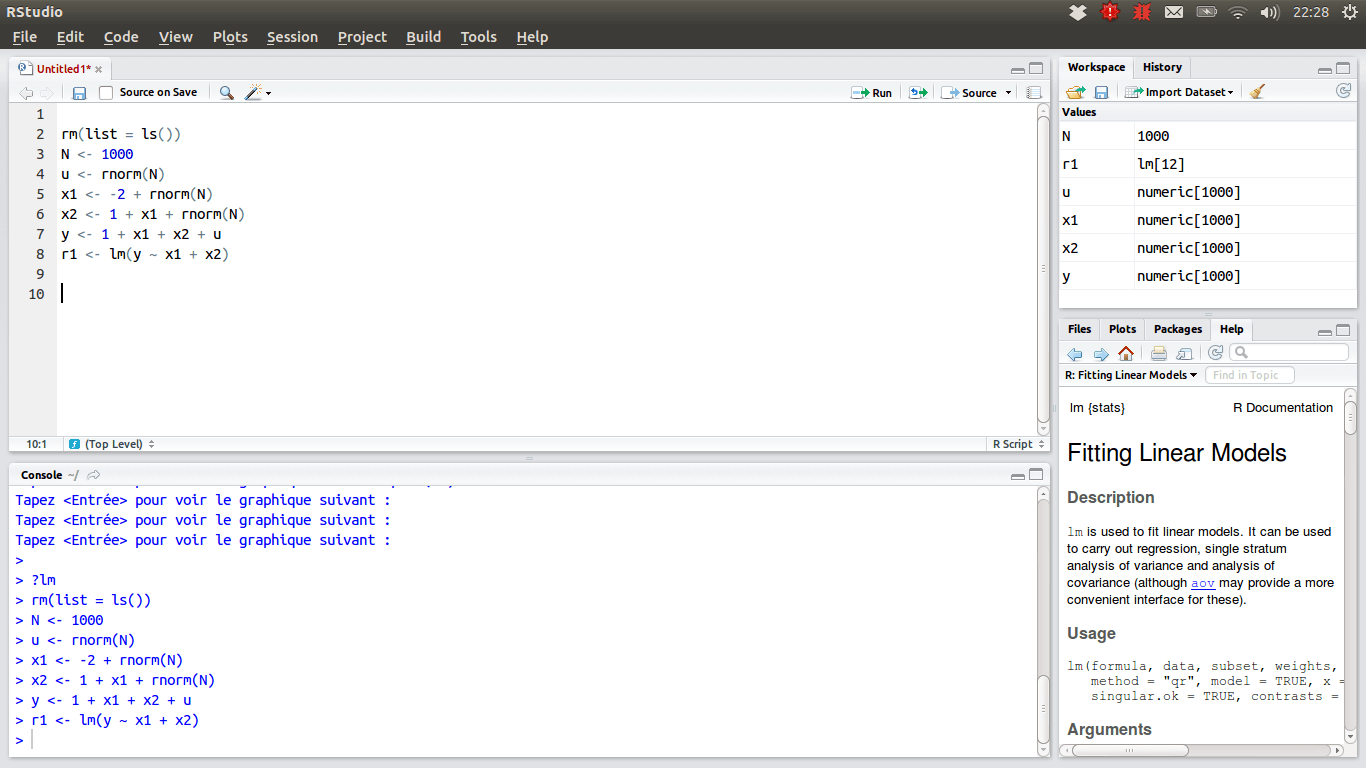
Der Debugging-Modus ermöglicht es, zu sehen, wie die Daten dynamisch aktualisiert werden, wenn ein Programm oder Skript Schritt für Schritt ausgeführt wird. Zur Versionskontrolle integriert RStudio die Unterstützung für SVN und Git. Ein nettes Plus ist die Möglichkeit, interaktive Grafiken mit Shiny zu erstellen und Bibliotheken zu geben.
Ihr persönlicher Werkzeugkasten
An dieser Stelle sollten Sie einen vollständigen Überblick über die Tools haben, die Sie kennen sollten, um sich in der Datenwissenschaft hervorzuheben. Außerdem hoffen wir, dass wir Ihnen genügend Informationen gegeben haben, um zu entscheiden, welche die bequemste Option innerhalb jeder Werkzeugkategorie ist. Jetzt liegt es an Ihnen. Data Science ist ein florierendes Gebiet Karriere machen. Aber wenn Sie das wollen, müssen Sie mit den Veränderungen von Trends und Technologien Schritt halten, da sie fast täglich stattfinden.