
Wenn Sie neu in der Big-Data-Analyse sind, könnten die zahlreichen Apache-Tools auf Ihrem Radar sein; Die schiere Menge verschiedener Tools kann jedoch verwirrend und manchmal überwältigend sein.
Dieser Beitrag wird diese Verwirrung auflösen und erklären, was Apache Hive und Impala sind und was sie voneinander unterscheidet!
Inhaltsverzeichnis
Apache Hive
Apache Hive ist eine SQL-Datenzugriffsschnittstelle für die Apache Hadoop-Plattform. Mit Hive können Sie Daten mithilfe der SQL-Syntax abfragen, aggregieren und analysieren.
Für Daten im HDFS-Dateisystem wird ein Lesezugriffsschema verwendet, sodass Sie Daten wie mit einer gewöhnlichen Tabelle oder einem relationalen DBMS behandeln können. HiveQL-Abfragen werden für MapReduce-Jobs in Java-Code übersetzt.
Hive-Abfragen werden in der Abfragesprache HiveQL geschrieben, die auf der SQL-Sprache basiert, aber den SQL-92-Standard nicht vollständig unterstützt.
Diese Sprache ermöglicht es Programmierern jedoch, ihre Abfragen zu verwenden, wenn es unbequem oder ineffizient ist, HiveQL-Funktionen zu verwenden. HiveQL kann mit benutzerdefinierten Skalarfunktionen (UDFs), Aggregationen (UDAF-Codes) und Tabellenfunktionen (UDTFs) erweitert werden.
Wie funktioniert Apache Hive?
Apache Hive übersetzt Programme, die in der HiveQL-Sprache (ähnlich SQL) geschrieben sind, in eine oder mehrere MapReduce-, Apache Tez- oder Apache Spark-Aufgaben. Dies sind drei Ausführungs-Engines, die auf Hadoop gestartet werden können. Anschließend organisiert Apache Hive die Daten in einem Array für die Hadoop Distributed File System (HDFS)-Datei, um die Jobs auf einem Cluster auszuführen und eine Antwort zu erzeugen.
Apache Hive-Tabellen ähneln relationalen Datenbanken, und Dateneinheiten sind von der wichtigsten Einheit bis zur granularsten Einheit organisiert. Datenbanken sind Arrays, die aus Partitionen bestehen, die wiederum in „Buckets“ unterteilt werden können.
Die Daten sind über HiveQL zugänglich. Innerhalb jeder Datenbank sind die Daten nummeriert und jede Tabelle entspricht einem HDFS-Verzeichnis.
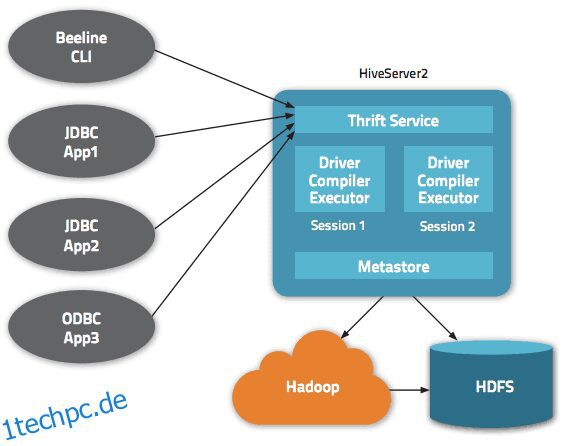
Innerhalb der Apache Hive-Architektur sind mehrere Schnittstellen verfügbar, z. B. Webschnittstelle, CLI oder externe Clients.
Tatsächlich ermöglicht der „Apache Hive Thrift“-Server entfernten Clients, Befehle und Anfragen mit verschiedenen Programmiersprachen an Apache Hive zu senden. Das zentrale Verzeichnis von Apache Hive ist ein „Metastore“, der alle Informationen enthält.
Der Motor, der Hive zum Laufen bringt, wird „der Treiber“ genannt. Es bündelt einen Compiler und einen Optimierer, um den optimalen Ausführungsplan zu bestimmen.
Für Sicherheit sorgt schließlich Hadoop. Es stützt sich daher auf Kerberos für die gegenseitige Authentifizierung zwischen Client und Server. Die Berechtigung für neu erstellte Dateien in Apache Hive wird von HDFS vorgegeben und ermöglicht Benutzer-, Gruppen- oder anderweitige Autorisierung.
Funktionen von Hive
- Unterstützt die Rechen-Engine von Hadoop und Spark
- Verwendet HDFS und fungiert als Data Warehouse.
- Verwendet MapReduce und unterstützt ETL
- Aufgrund von HDFS hat es eine ähnliche Fehlertoleranz wie Hadoop
Apache Hive: Vorteile
Apache Hive ist eine ideale Lösung für Abfragen und Datenanalysen. Es ermöglicht qualitative Erkenntnisse, verschafft einen Wettbewerbsvorteil und erleichtert die Reaktionsfähigkeit auf die Marktnachfrage.
Unter den Hauptvorteilen von Apache Hive können wir die Benutzerfreundlichkeit erwähnen, die mit seiner „SQL-freundlichen“ Sprache verbunden ist. Außerdem beschleunigt es das anfängliche Einfügen von Daten, da die Daten nicht von einer Diskette im internen Datenbankformat gelesen oder nummeriert werden müssen.
Da die Daten in HDFS gespeichert sind, ist es möglich, große Datensätze mit bis zu Hunderten von Petabytes an Daten auf Apache Hive zu speichern. Diese Lösung ist viel skalierbarer als eine herkömmliche Datenbank. In dem Wissen, dass es sich um einen Cloud-Dienst handelt, ermöglicht Apache Hive Benutzern, virtuelle Server basierend auf Schwankungen der Arbeitslast (dh Aufgaben) schnell zu starten.
Sicherheit ist auch ein Aspekt, bei dem Hive besser abschneidet, mit seiner Fähigkeit, wiederherstellungskritische Workloads im Falle eines Problems zu replizieren. Schließlich ist die Arbeitskapazität beispiellos, da sie bis zu 100.000 Anfragen pro Stunde ausführen kann.
Apache Impala
Apache Impala ist eine massiv parallele SQL-Abfrage-Engine für die interaktive Ausführung von SQL-Abfragen auf in Apache Hadoop gespeicherte Daten, geschrieben in C++ und vertrieben unter der Apache 2.0-Lizenz.
Impala wird auch als MPP-Engine (Massively Parallel Processing), als verteiltes DBMS und sogar als SQL-on-Hadoop-Stack-Datenbank bezeichnet.

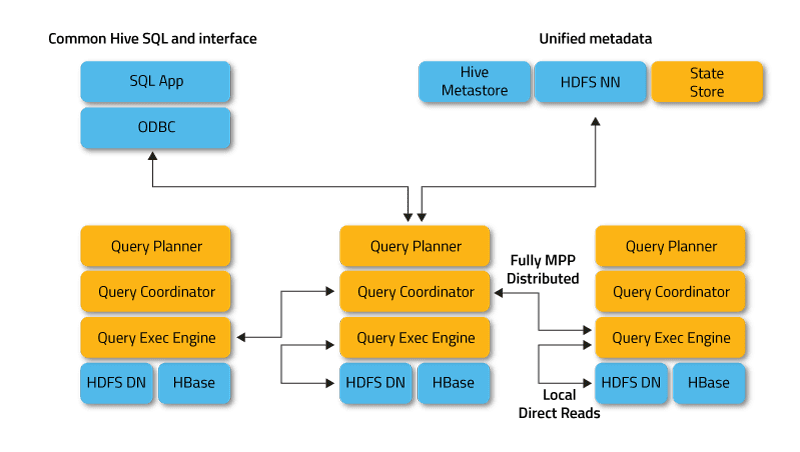
Impala arbeitet im verteilten Modus, in dem Prozessinstanzen auf verschiedenen Clusterknoten ausgeführt werden und Clientanforderungen empfangen, planen und koordinieren. In diesem Fall ist eine parallele Ausführung von Fragmenten der SQL-Abfrage möglich.
Clients sind Benutzer und Anwendungen, die SQL-Abfragen zu Daten senden, die in Apache Hadoop (HBase und HDFS) oder Amazon S3 gespeichert sind. Die Interaktion mit Impala erfolgt über die Webschnittstelle HUE (Hadoop User Experience), ODBC, JDBC und die Befehlszeilen-Shell Impala Shell.
Impala ist infrastrukturell von einem anderen beliebten SQL-on-Hadoop-Tool, Apache Hive, abhängig, das seinen Metadatenspeicher verwendet. Insbesondere informiert der Hive Metastore Impala über die Verfügbarkeit und Struktur der Datenbanken.
Beim Erstellen, Ändern und Löschen von Schemaobjekten oder beim Laden von Daten in Tabellen über SQL-Anweisungen werden die entsprechenden Metadatenänderungen mithilfe eines spezialisierten Verzeichnisdienstes automatisch an alle Impala-Knoten weitergegeben.
Die Schlüsselkomponenten von Impala sind die folgenden ausführbaren Dateien:
- Impalad oder Impala-Daemon ist ein Systemdienst, der Abfragen für HDFS-, HBase- und Amazon S3-Daten plant und ausführt. Auf jedem Cluster-Knoten wird ein Impalad-Prozess ausgeführt.
- Statestore ist ein Benennungsdienst, der den Standort und den Status aller Impalad-Instanzen im Cluster verfolgt. Auf jedem Knoten und dem Hauptserver (Name Node) läuft eine Instanz dieses Systemdienstes.
- Catalog ist ein Metadatenkoordinierungsdienst, der Änderungen von Impala DDL- und DML-Anweisungen an alle betroffenen Impala-Knoten weitergibt, sodass neue Tabellen oder neu geladene Daten sofort für jeden Knoten im Cluster sichtbar sind. Es wird empfohlen, dass eine Instanz von Catalog auf demselben Cluster-Host wie der Statestored-Daemon ausgeführt wird.
Wie funktioniert Apache Impala?
Impala verwendet wie Apache Hive anstelle von SQL eine ähnliche deklarative Abfragesprache, die Hive Query Language (HiveQL), die eine Teilmenge von SQL92 ist.
Die eigentliche Ausführung der Anfrage in Impala sieht wie folgt aus:
Die Clientanwendung sendet eine SQL-Abfrage, indem sie sich über standardisierte ODBC- oder JDBC-Treiberschnittstellen mit einem Impalad verbindet. Der verbundene Impalad wird zum Koordinator der aktuellen Anfrage.
Die SQL-Abfrage wird analysiert, um die Aufgaben für die Impalad-Instanzen im Cluster zu bestimmen; Anschließend wird der optimale Abfrageausführungsplan erstellt.
Impalad greift direkt auf HDFS und HBase zu, indem lokale Instanzen von Systemdiensten verwendet werden, um Daten bereitzustellen. Im Gegensatz zu Apache Hive spart eine solche direkte Interaktion erheblich Zeit bei der Abfrageausführung, da Zwischenergebnisse nicht gespeichert werden.
Als Antwort gibt jeder Daemon Daten an das koordinierende Impalad zurück und sendet die Ergebnisse an den Client zurück.
Eigenschaften von Impalas
- Unterstützung für Echtzeit-In-Memory-Verarbeitung
- SQL-freundlich
- Unterstützt Speichersysteme wie HDFS, Apache HBase und Amazon S3
- Unterstützt die Integration mit BI-Tools wie Pentaho und Tableau
- Verwendet die HiveQL-Syntax
Apache Impala: Vorteile
Impala vermeidet möglichen Start-Overhead, da alle System-Daemon-Prozesse direkt beim Booten gestartet werden. Es spart erheblich Zeit bei der Abfrageausführung. Eine zusätzliche Steigerung der Geschwindigkeit von Impala liegt darin begründet, dass dieses SQL-Tool für Hadoop im Gegensatz zu Hive keine Zwischenergebnisse speichert und direkt auf HDFS oder HBase zugreift.
Außerdem generiert Impala Programmcode zur Laufzeit und nicht wie Hive zur Kompilierung. Ein Nebeneffekt der Hochgeschwindigkeitsleistung von Impala ist jedoch die verringerte Zuverlässigkeit.
Insbesondere wenn der Datenknoten während der Ausführung einer SQL-Abfrage ausfällt, wird die Impala-Instanz neu gestartet, und Hive hält weiterhin eine Verbindung zur Datenquelle aufrecht, wodurch Fehlertoleranz bereitgestellt wird.
Weitere Vorteile von Impala sind die integrierte Unterstützung für ein sicheres Netzwerkauthentifizierungsprotokoll Kerberos, Priorisierung und die Möglichkeit, die Warteschlange von Anfragen zu verwalten, sowie die Unterstützung gängiger Big-Data-Formate wie LZO, Avro, RCFile, Parquet und Sequence.
Hive Vs Impala: Ähnlichkeiten
Hive und Impala werden unter der Lizenz der Apache Software Foundation kostenlos verteilt und beziehen sich auf SQL-Tools für die Arbeit mit Daten, die in einem Hadoop-Cluster gespeichert sind. Darüber hinaus verwenden sie auch das verteilte HDFS-Dateisystem.
Impala und Hive implementieren unterschiedliche Aufgaben mit einem gemeinsamen Fokus auf der SQL-Verarbeitung von Big Data, die in einem Apache Hadoop-Cluster gespeichert sind. Impala bietet eine SQL-ähnliche Schnittstelle, mit der Sie Hive-Tabellen lesen und schreiben können, wodurch ein einfacher Datenaustausch ermöglicht wird.
Gleichzeitig macht Impala SQL-Operationen auf Hadoop recht schnell und effizient, was die Verwendung dieses DBMS in Big-Data-Analyseforschungsprojekten ermöglicht. Wann immer möglich, arbeitet Impala mit einer bestehenden Apache Hive-Infrastruktur, die bereits zur Ausführung lang laufender SQL-Batch-Abfragen verwendet wird.
Außerdem speichert Impala seine Tabellendefinitionen in einem Metastore, einer traditionellen MySQL- oder PostgreSQL-Datenbank, dh am selben Ort, an dem Hive ähnliche Daten speichert. Es ermöglicht Impala den Zugriff auf Hive-Tabellen, solange alle Spalten die von Impala unterstützten Datentypen, Dateiformate und Komprimierungscodecs verwenden.
Hive Vs Impala: Unterschiede

Programmiersprache
Hive ist in Java geschrieben, während Impala in C++ geschrieben ist. Allerdings verwendet Impala auch einige Java-basierte Hive-UDFs.
Anwendungsfälle
Data Engineers verwenden Hive beispielsweise in ETL-Prozessen (Extract, Transform, Load) für lang andauernde Batch-Jobs auf großen Datensätzen, beispielsweise in Reiseaggregatoren und Flughafeninformationssystemen. Impala wiederum ist hauptsächlich für Analysten und Datenwissenschaftler gedacht und wird hauptsächlich in Aufgaben wie Business Intelligence eingesetzt.
Leistung
Impala führt SQL-Abfragen in Echtzeit aus, während sich Hive durch eine geringe Datenverarbeitungsgeschwindigkeit auszeichnet. Mit einfachen SQL-Abfragen kann Impala 6-69 mal schneller laufen als Hive. Hive verarbeitet komplexe Abfragen jedoch besser.
Latenz/Durchsatz
Der Durchsatz von Hive ist deutlich höher als der von Impala. Die LLAP-Funktion (Live Long and Process), die das Zwischenspeichern von Abfragen im Speicher ermöglicht, verleiht Hive eine gute Leistung auf niedriger Ebene.
LLAP umfasst langfristige Systemdienste (Daemons), die es Ihnen ermöglichen, direkt mit HDFS-Datenknoten zu interagieren und die eng integrierte DAG-Abfragestruktur (Directed Acyclic Graph) zu ersetzen – ein Graphmodell, das aktiv beim Big Data Computing verwendet wird.
Fehlertoleranz
Hive ist ein fehlertolerantes System, das alle Zwischenergebnisse bewahrt. Dies wirkt sich auch positiv auf die Skalierbarkeit aus, führt jedoch zu einer Verringerung der Datenverarbeitungsgeschwindigkeit. Impala wiederum kann nicht als fehlertolerante Plattform bezeichnet werden, da es stärker speichergebunden ist.
Codeumwandlung
Hive generiert Abfrageausdrücke zur Kompilierzeit, während Impala sie zur Laufzeit generiert. Hive ist beim ersten Start der Anwendung durch ein „Kaltstart“-Problem gekennzeichnet; Abfragen werden langsam konvertiert, da eine Verbindung zur Datenquelle hergestellt werden muss.
Impala hat diese Art von Startaufwand nicht. Die notwendigen Systemdienste (Daemons) zur Verarbeitung von SQL-Anfragen werden beim Booten gestartet, was die Arbeit beschleunigt.
Speicherunterstützung
Impala unterstützt LZO-, Avro- und Parquet-Formate, während Hive mit Plain Text und ORC arbeitet. Beide unterstützen jedoch die Formate RCFIle und Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Use CasesData EngineeringAnalysis and analyticsPerformanceHohe für einfache AbfragenVergleichsweise geringe LatenzHöhere Latenz durch CachingWeniger latente FehlertoleranzToleranter durch MapReduceWeniger tolerant durch MPPConversionLangsam durch KaltstartSchnellere KonvertierungSpeicherunterstützungPlain Text und ORCLZO, Avro, Parquet
Letzte Worte
Hive und Impala konkurrieren nicht, sondern ergänzen sich effektiv. Obwohl es erhebliche Unterschiede zwischen den beiden gibt, gibt es auch viele Gemeinsamkeiten, und die Wahl eines gegenüber dem anderen hängt von den Daten und besonderen Anforderungen des Projekts ab.
Sie können auch Kopf-an-Kopf-Vergleiche zwischen Hadoop und Spark untersuchen.
.