

Der Linux-Befehl grep ist ein Dienstprogramm zum Abgleichen von Zeichenfolgen und Mustern, das übereinstimmende Zeilen aus mehreren Dateien anzeigt. Es funktioniert auch mit Pipe-Ausgaben von anderen Befehlen. Wir zeigen Ihnen wie.
Inhaltsverzeichnis
Die Geschichte hinter grep
Der grep-Befehl ist unter Linux berühmt und Unix Kreise aus drei Gründen. Erstens ist es enorm nützlich. Zweitens, die Die Fülle an Optionen kann überwältigend sein. Drittens wurde es über Nacht geschrieben, um ein bestimmtes Bedürfnis zu befriedigen. Die ersten beiden sind der Hammer; der dritte ist etwas daneben.
Ken Thompson hatte die Suchfunktionen für reguläre Ausdrücke aus dem ed-Editor extrahiert (ausgesprochen ee-dee) und erstellte – für seinen eigenen Gebrauch – ein kleines Programm zum Durchsuchen von Textdateien. Sein Abteilungsleiter bei Bell Labs, Doug Mcilroy, ging auf Thompson zu und schilderte einem seiner Kollegen das Problem, Lee McMahon, wurde konfrontiert.
McMahon versuchte, die Autoren der Föderalistische Papiere durch Textanalyse. Er brauchte ein Tool, das in Textdateien nach Phrasen und Zeichenfolgen suchen konnte. Thompson verbrachte an diesem Abend ungefähr eine Stunde damit, sein Werkzeug zu einem allgemeinen Dienstprogramm zu machen, das von anderen verwendet werden konnte, und benannte es in grep um. Den Namen entnahm er der ed-Befehlszeichenfolge g/re/p , was übersetzt „globale Suche nach regulären Ausdrücken“ bedeutet.
Du kannst Thompson beim Reden zusehen zu Brian Kernighan über die geburt von grep.
Einfache Suche mit grep
Um in einer Datei nach einer Zeichenfolge zu suchen, übergeben Sie den Suchbegriff und den Dateinamen in der Befehlszeile:

Passende Zeilen werden angezeigt. In diesem Fall handelt es sich um eine einzelne Zeile. Der passende Text wird hervorgehoben. Dies liegt daran, dass grep bei den meisten Distributionen mit folgendem Alias versehen ist:
alias grep='grep --colour=auto'
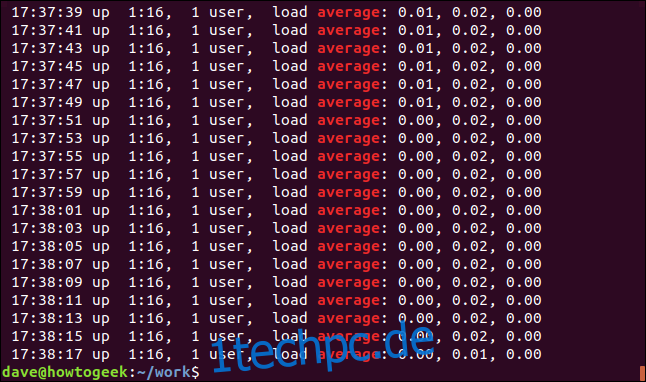
Schauen wir uns die Ergebnisse an, bei denen mehrere Zeilen übereinstimmen. Wir suchen in einer Anwendungsprotokolldatei nach dem Wort „Durchschnitt“. Da wir uns nicht erinnern können, ob das Wort in der Protokolldatei in Kleinbuchstaben geschrieben ist, verwenden wir die Option -i (Groß-/Kleinschreibung ignorieren):
grep -i Average geek-1.log

Jede übereinstimmende Zeile wird angezeigt, wobei der übereinstimmende Text in jeder hervorgehoben ist.
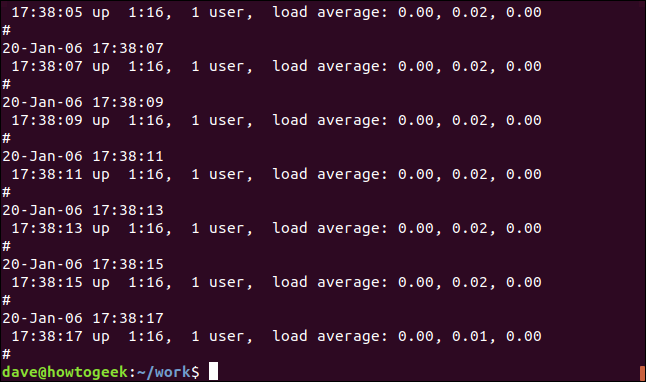
Wir können die nicht übereinstimmenden Zeilen anzeigen, indem wir die Option -v (Übereinstimmung invertieren) verwenden.
grep -v Mem geek-1.log

Es gibt keine Hervorhebung, da dies die nicht übereinstimmenden Zeilen sind.
Wir können grep dazu bringen, komplett zu schweigen. Das Ergebnis wird als Rückgabewert von grep an die Shell übergeben. Ein Ergebnis von Null bedeutet, dass die Zeichenfolge gefunden wurde, und ein Ergebnis von Eins bedeutet, dass sie nicht gefunden wurde. Wir können den Rückgabecode mit dem $? spezielle Parameter:
grep -q average geek-1.log
echo $?
grep -q wdzwdz geek-1.log
echo $?

Rekursive Suchen mit grep
Um verschachtelte Verzeichnisse und Unterverzeichnisse zu durchsuchen, verwenden Sie die Option -r (rekursiv). Beachten Sie, dass Sie in der Befehlszeile keinen Dateinamen angeben, sondern einen Pfad angeben müssen. Hier suchen wir im aktuellen Verzeichnis „.“ und alle Unterverzeichnisse:
grep -r -i memfree .

Die Ausgabe enthält das Verzeichnis und den Dateinamen jeder übereinstimmenden Zeile.

Wir können grep dazu bringen, symbolischen Links zu folgen, indem wir die Option -R (rekursive Dereferenzierung) verwenden. Wir haben in diesem Verzeichnis einen symbolischen Link namens logs-folder. Es zeigt auf /home/dave/logs.
ls -l logs-folder

Wiederholen wir unsere letzte Suche mit der Option -R (rekursive Dereferenzierung):
grep -R -i memfree .

Dem symbolischen Link wird gefolgt und das Verzeichnis, auf das er verweist, wird ebenfalls von grep durchsucht.

Suche nach ganzen Wörtern
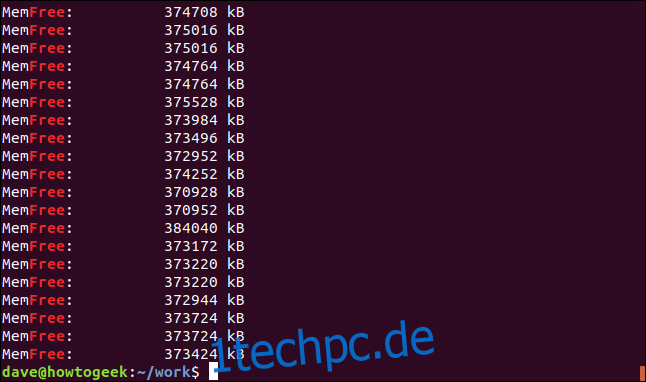
Standardmäßig stimmt grep mit einer Zeile überein, wenn das Suchziel irgendwo in dieser Zeile erscheint, auch in einer anderen Zeichenfolge. Schauen Sie sich dieses Beispiel an. Wir suchen nach dem Wort „frei“.
grep -i free geek-1.log

Das Ergebnis sind Zeilen, die die Zeichenfolge „free“ enthalten, aber keine separaten Wörter. Sie sind Teil der Zeichenfolge „MemFree“.
Um zu erzwingen, dass grep nur mit separaten „Wörtern“ übereinstimmt, verwenden Sie die Option -w (Wort regexp).
grep -w -i free geek-1.log
echo $?

Diesmal gibt es keine Ergebnisse, da der Suchbegriff „frei“ nicht als separates Wort in der Datei vorkommt.
Mehrere Suchbegriffe verwenden
Die Option -E (extended regexp) ermöglicht Ihnen, nach mehreren Wörtern zu suchen. (Die Option -E ersetzt das veraltete egrep-Version von grep.)
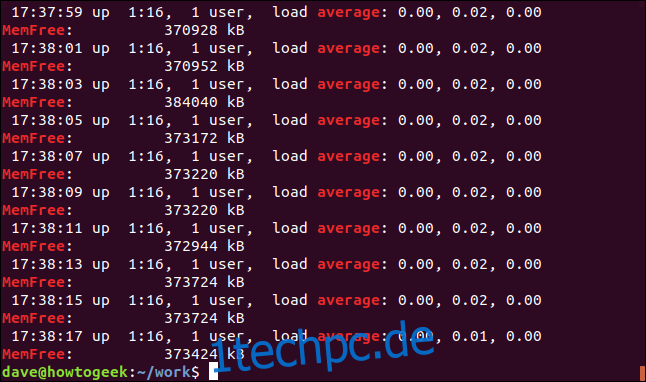
Dieser Befehl sucht nach zwei Suchbegriffen, „average“ und „memfree“.
grep -E -w -i "average|memfree" geek-1.log

Zu jedem der Suchbegriffe werden alle passenden Zeilen angezeigt.
Sie können auch nach mehreren Begriffen suchen, die nicht unbedingt ganze Wörter sind, aber es können auch ganze Wörter sein.
Mit der Option -e (Muster) können Sie mehrere Suchbegriffe in der Befehlszeile verwenden. Wir verwenden die Klammerfunktion für reguläre Ausdrücke, um ein Suchmuster zu erstellen. Es sagt grep, dass es mit einem der in den Klammern enthaltenen Zeichen übereinstimmen soll.[].“ Das bedeutet, dass grep bei der Suche entweder mit „kB“ oder „KB“ übereinstimmt.

Beide Strings werden abgeglichen, und tatsächlich enthalten einige Zeilen beide Strings.

Passende Linien genau
Das -x (line regexp) findet nur Zeilen, bei denen die gesamte Zeile mit dem Suchbegriff übereinstimmt. Suchen wir nach einem Datums- und Zeitstempel, von dem wir wissen, dass er nur einmal in der Protokolldatei vorkommt:
grep -x "20-Jan--06 15:24:35" geek-1.log

Die passende Zeile wird gefunden und angezeigt.
Das Gegenteil davon ist, dass nur die Zeilen angezeigt werden, die nicht übereinstimmen. Dies kann nützlich sein, wenn Sie sich Konfigurationsdateien ansehen. Kommentare sind großartig, aber manchmal ist es schwierig, die tatsächlichen Einstellungen unter allen zu erkennen. Hier ist die Datei /etc/sudoers:

Wir können die Kommentarzeilen wie folgt effektiv herausfiltern:
sudo grep -v "https://www.wdzwdz.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
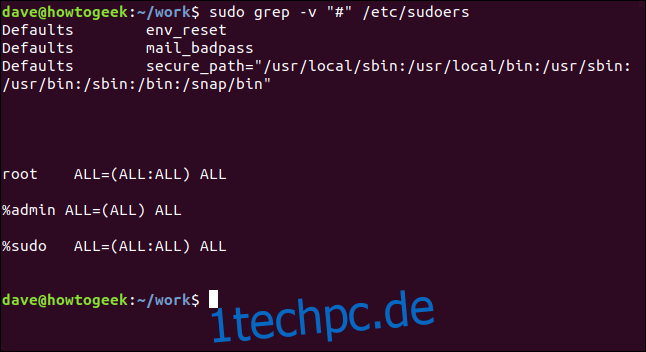
Das ist viel einfacher zu analysieren.
Nur übereinstimmenden Text anzeigen
Es kann vorkommen, dass Sie nicht die gesamte übereinstimmende Zeile, sondern nur den übereinstimmenden Text sehen möchten. Die Option -o (nur übereinstimmende) macht genau das.
grep -o MemFree geek-1.log

Die Anzeige wird so reduziert, dass nur der Text angezeigt wird, der zum Suchbegriff passt, anstatt der gesamten passenden Zeile.

Zählen mit grep
Bei grep geht es nicht nur um Text, sondern kann auch numerische Informationen liefern. Wir können grep auf unterschiedliche Weise für uns zählen lassen. Wenn wir wissen möchten, wie oft ein Suchbegriff in einer Datei vorkommt, können wir die Option -c (count) verwenden.
grep -c average geek-1.log

grep meldet, dass der Suchbegriff 240 Mal in dieser Datei vorkommt.
Sie können grep veranlassen, die Zeilennummer für jede übereinstimmende Zeile anzuzeigen, indem Sie die Option -n (Zeilennummer) verwenden.
grep -n Jan geek-1.log

Die Zeilennummer für jede übereinstimmende Zeile wird am Anfang der Zeile angezeigt.

Um die Anzahl der angezeigten Ergebnisse zu reduzieren, verwenden Sie die Option -m (max. Anzahl). Wir beschränken die Ausgabe auf fünf übereinstimmende Zeilen:
grep -m5 -n Jan geek-1.log

Kontext hinzufügen
Es ist oft nützlich, einige zusätzliche Zeilen – möglicherweise nicht übereinstimmende Zeilen – für jede übereinstimmende Zeile anzeigen zu können. es kann helfen, zu unterscheiden, welche der übereinstimmenden Zeilen diejenigen sind, an denen Sie interessiert sind.
Um einige Zeilen nach der passenden Zeile anzuzeigen, verwenden Sie die Option -A (nach Kontext). In diesem Beispiel fragen wir nach drei Zeilen:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
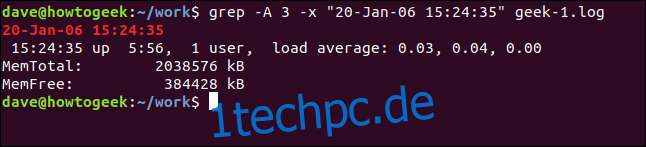
Um einige Zeilen vor der passenden Zeile anzuzeigen, verwenden Sie die Option -B (Kontext vor).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
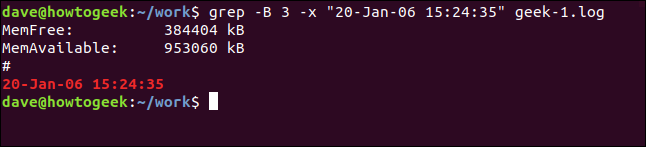
Und um Zeilen vor und nach der übereinstimmenden Zeile einzuschließen, verwenden Sie die Option -C (Kontext).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
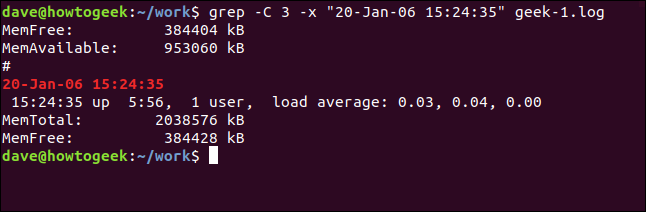
Anzeigen übereinstimmender Dateien
Um die Namen der Dateien anzuzeigen, die den Suchbegriff enthalten, verwenden Sie die Option -l (Dateien mit Übereinstimmung). Um herauszufinden, welche C-Quellcodedateien Verweise auf die Headerdatei sl.h enthalten, verwenden Sie diesen Befehl:
grep -l "sl.h" *.c

Die Dateinamen werden aufgelistet, nicht die passenden Zeilen.

Und natürlich können wir nach Dateien suchen, die den Suchbegriff nicht enthalten. Die Option -L (Dateien ohne Übereinstimmung) macht genau das.
grep -L "sl.h" *.c

Anfang und Ende von Zeilen
Wir können grep zwingen, nur Übereinstimmungen anzuzeigen, die entweder am Anfang oder am Ende einer Zeile stehen. Der reguläre Ausdrucksoperator „^“ entspricht dem Anfang einer Zeile. Praktisch alle Zeilen in der Protokolldatei enthalten Leerzeichen, aber wir suchen nach Zeilen, die ein Leerzeichen als erstes Zeichen haben:
grep "^ " geek-1.log

Die Zeilen, die als erstes Zeichen ein Leerzeichen haben – am Zeilenanfang – werden angezeigt.
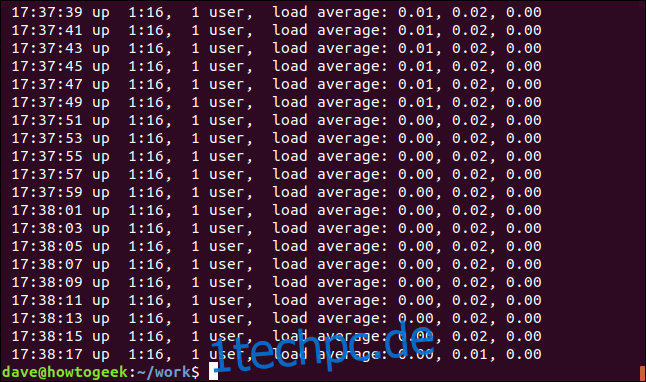
Um das Zeilenende abzugleichen, verwenden Sie den regulären Ausdrucksoperator „$“. Wir suchen nach Zeilen, die mit „00“ enden.
grep "00$" geek-1.log

Das Display zeigt die Zeilen an, deren letzte Zeichen „00“ sind.
Verwenden von Pipes mit grep
Natürlich können Sie input an grep weiterleiten, die Ausgabe von grep an ein anderes Programm weiterleiten und grep in die Mitte einer Pipe-Kette einbetten.
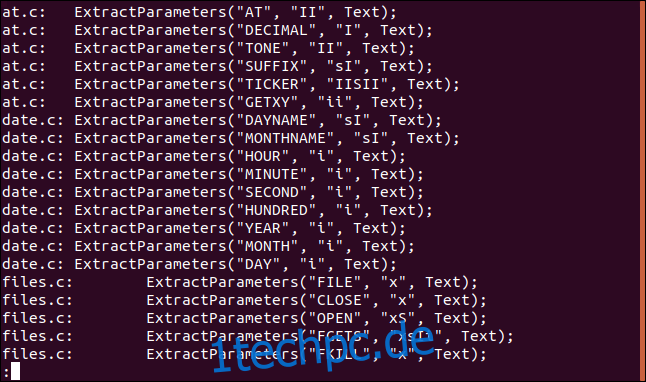
Nehmen wir an, wir möchten alle Vorkommen der Zeichenfolge „ExtractParameters“ in unseren C-Quellcodedateien sehen. Wir wissen, dass es ziemlich viele sein werden, also leiten wir die Ausgabe in weniger weiter:
grep "ExtractParameters" *.c | less

Die Ausgabe wird in weniger dargestellt.
Auf diese Weise können Sie durch die Dateiliste blättern und die Suchfunktion von less verwenden.
Wenn wir die Ausgabe von grep in wc umleiten und die Option -l (lines) verwenden, können wir kann die anzahl der zeilen zählen in den Quellcodedateien, die „ExtractParameters“ enthalten. (Wir könnten dies mit der Option grep -c (count) erreichen, aber dies ist eine nette Möglichkeit, das Pipe-out von grep zu demonstrieren.)
grep "ExtractParameters" *.c | wc -l

Mit dem nächsten Befehl leiten wir die Ausgabe von ls an grep und die Ausgabe von grep an sort weiter. Wir listen die Dateien im aktuellen Verzeichnis auf und wählen diejenigen mit der Zeichenfolge „Aug“ aus. und nach Dateigröße sortieren:
ls -l | grep "Aug" | sort +4n
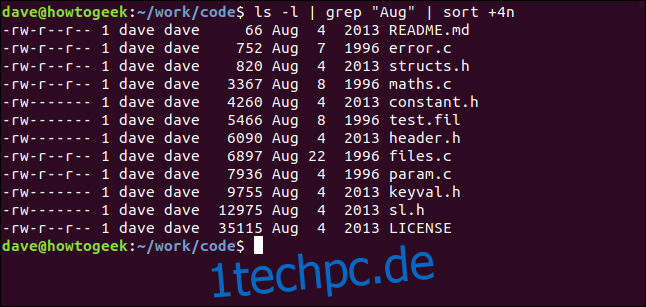
Lassen Sie uns das aufschlüsseln:
ls -l: Führt eine lange Formatauflistung der Dateien mit ls aus.
grep „Aug“: Wählen Sie die Zeilen aus der ls-Liste aus, die „Aug“ enthalten. Beachten Sie, dass dies auch Dateien finden würde, deren Namen „Aug“ enthalten.
sort +4n: Sortiert die Ausgabe von grep nach der vierten Spalte (Dateigröße).
Wir erhalten eine sortierte Auflistung aller im August (unabhängig vom Jahr) geänderten Dateien, in aufsteigender Reihenfolge der Dateigröße.
grep: Weniger ein Befehl, mehr ein Verbündeter
grep ist ein großartiges Werkzeug, das Sie zur Verfügung haben. Es stammt aus dem Jahr 1974 und funktioniert immer noch, weil wir brauchen, was es tut, und nichts macht es besser.
Die Kopplung von grep mit einigen regulären Ausdrücken-fu bringt es wirklich auf die nächste Stufe.