

Der Linux-Befehl stat zeigt Ihnen viel mehr Details als ls. Werfen Sie mit diesem informativen und konfigurierbaren Dienstprogramm einen Blick hinter die Kulissen. Wir zeigen Ihnen, wie Sie es verwenden.
Inhaltsverzeichnis
stat führt Sie hinter die Kulissen
Der ls-Befehl ist großartig in dem, was er tut – und er kann viel –, aber unter Linux scheint es immer einen Weg zu geben, tiefer zu gehen und zu sehen, was unter der Oberfläche liegt. Und oft geht es nicht nur darum, den Rand des Teppichs anzuheben. Sie können die Dielen aufreißen und dann ein Loch graben. Sie können Linux wie eine Zwiebel schälen.
ls zeigt Ihnen viele Informationen zu einer Datei an, z. B. welche Berechtigungen für sie festgelegt sind, wie groß sie ist und ob es sich um eine Datei oder einen symbolischen Link handelt. Um diese Informationen anzuzeigen, liest ls sie aus a Dateisystemstruktur namens Inode.
Jede Datei und jedes Verzeichnis hat einen Inode. Die Inode hält Metadaten zur Datei, z. B. welche Dateisystemblöcke es belegt, und die mit der Datei verknüpften Datumsstempel. Der Inode ist wie ein Bibliotheksausweis für die Datei. Aber ls zeigt Ihnen nur einige der Informationen an. Um alles zu sehen, müssen wir den stat-Befehl verwenden.
Wie ls hat der Befehl stat viele Optionen. Dies macht es zu einem großartigen Kandidaten für die Verwendung von Aliasen. Sobald Sie einen bestimmten Satz von Optionen entdeckt haben, die dazu führen, dass stat Ihnen die gewünschte Ausgabe liefert, wickeln Sie sie in eine Alias- oder Shell-Funktion ein. Dies macht die Verwendung viel bequemer, und Sie müssen sich keine geheimnisvollen Befehlszeilenoptionen merken.
Ein schneller Vergleich
Lassen Sie uns ls verwenden, um uns eine lange Liste (Option -l) mit für Menschen lesbaren Dateigrößen (Option -h) zu geben:
ls -lh ana.h

Von links nach rechts liefert ls folgende Informationen:
Das allererste Zeichen ist ein Bindestrich „-“ und dies sagt uns, dass die Datei eine normale Datei ist und kein Socket, Symlink oder ein anderer Objekttyp.
Der Besitzer, die Gruppe und andere Berechtigungen werden im Oktalformat aufgelistet.
Die Anzahl der Hardlinks, die auf diese Datei verweisen. In diesem Fall und in den meisten Fällen wird es einer sein.
Der Dateibesitzer ist Dave.
Der Gruppenbesitzer ist Dave.
Die Dateigröße beträgt 802 Byte.
Die Datei wurde zuletzt am Freitag, den 13. Dezember 2015 geändert.
Der Dateiname ist ana.c.
Schauen wir uns mit stat an:
stat ana.h
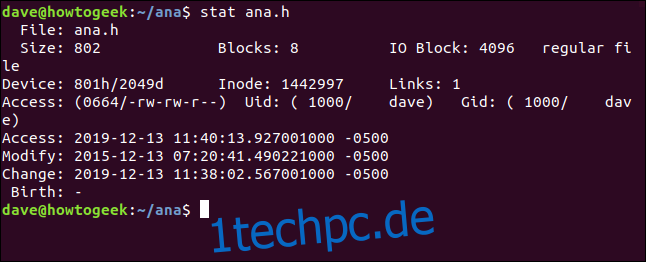
Die Informationen, die wir von stat erhalten, sind:
Datei: Der Name der Datei. Normalerweise ist es derselbe Name, den wir in der Befehlszeile an stat übergeben haben, aber er kann anders sein, wenn wir einen symbolischen Link betrachten.
Größe: Die Größe der Datei in Byte.
Blöcke: Die Anzahl der Dateisystemblöcke, die die Datei benötigt, um auf der Festplatte gespeichert zu werden.
IO-Block: Die Größe eines Dateisystemblocks.
Dateityp: Der Objekttyp, den die Metadaten beschreiben. Die gebräuchlichsten Typen sind Dateien und Verzeichnisse, sie können aber auch Links, Sockets oder Named Pipes sein.
Gerät: Die Gerätenummer in hexadezimal und dezimal. Dies ist die ID der Festplatte, auf der die Datei gespeichert ist.
Inode: Die Inode-Nummer. Das heißt, die ID-Nummer dieses Inode. Zusammen identifizieren die Inode-Nummer und die Gerätenummer eine Datei eindeutig.
Links: Diese Zahl gibt an, wie viele Hardlinks auf diese Datei verweisen. Jeder Hardlink hat seinen eigenen Inode. Eine andere Möglichkeit, über diese Zahl nachzudenken, ist, wie viele Inodes auf diese eine Datei zeigen. Jedes Mal, wenn ein Hardlink erstellt oder gelöscht wird, wird diese Zahl nach oben oder unten angepasst. Wenn er Null erreicht, wurde die Datei selbst gelöscht und der Inode entfernt. Wenn Sie stat für ein Verzeichnis verwenden, stellt diese Zahl die Anzahl der Dateien im Verzeichnis dar, einschließlich des „.“ Eintrag für das aktuelle Telefonbuch und den Eintrag „..“ für das übergeordnete Telefonbuch.
Zugriff: Die Dateiberechtigungen werden in ihren oktalen und traditionellen rwx-Formaten (Lesen, Schreiben, Ausführen) angezeigt.
Uid: Benutzer-ID und Kontoname des Eigentümers.
Gid: Gruppen-ID und Kontoname des Eigentümers.
Zugriff: Der Zugriffszeitstempel. Nicht so einfach, wie es scheinen mag. Moderne Linux-Distributionen verwenden ein Schema namens Relatime, das versucht, Optimieren Sie die Schreibvorgänge auf der Festplatte, die zum Aktualisieren der Zugriffszeit erforderlich sind. Einfach ausgedrückt wird die Zugriffszeit aktualisiert, wenn sie älter als die geänderte Zeit ist.
Ändern: Der Änderungszeitstempel. Dies ist der Zeitpunkt, zu dem der Inhalt der Datei zuletzt geändert wurde. (Zufälligerweise wurde der Inhalt dieser Datei auf den Tag genau vor vier Jahren zuletzt geändert.)
Ändern: Der Änderungszeitstempel. Dies ist der Zeitpunkt, zu dem die Attribute oder der Inhalt der Datei zuletzt geändert wurden. Wenn Sie eine Datei ändern, indem Sie neue Dateiberechtigungen festlegen, wird der Änderungszeitstempel aktualisiert (weil sich die Dateiattribute geändert haben), aber der geänderte Zeitstempel wird nicht aktualisiert (weil der Dateiinhalt nicht geändert wurde).
Geburt: Reserviert, um das ursprüngliche Erstellungsdatum der Datei anzuzeigen, dies ist jedoch in Linux nicht implementiert.
Verstehen der Zeitstempel
Die Zeitstempel sind zeitzonensensitiv. Die -0500 am Ende jeder Zeile zeigt an, dass diese Datei auf einem Computer in a . erstellt wurde abgestimmte Weltzeit (UTC) Zeitzone, die der Zeitzone des aktuellen Computers fünf Stunden voraus ist. Dieser Computer liegt also fünf Stunden hinter dem Computer zurück, der diese Datei erstellt hat. Tatsächlich wurde die Datei auf einem Computer in der britischen Zeitzone erstellt, und wir betrachten sie hier auf einem Computer in der Zeitzone US Eastern Standard.
Die Änderungs- und Änderungszeitstempel können Verwirrung stiften, da ihre Namen für den Uneingeweihten so klingen, als ob sie dasselbe bedeuten würden.
Lassen Sie uns chmod verwenden, um die Dateiberechtigungen für eine Datei namens ana.c zu ändern. Wir werden es für jeden beschreibbar machen. Dies wirkt sich nicht auf den Inhalt der Datei aus, jedoch auf die Attribute der Datei.
chmod +w ana.c
Und dann verwenden wir stat, um die Zeitstempel anzuzeigen:
stat ana.c

Der Änderungszeitstempel wurde aktualisiert, der geänderte jedoch nicht.
Der geänderte Zeitstempel wird nur aktualisiert, wenn der Inhalt der Datei geändert wird. Der Änderungszeitstempel wird sowohl für Inhaltsänderungen als auch für Attributänderungen aktualisiert.
Statistik mit mehreren Dateien verwenden
Um einen Statistikbericht zu mehreren Dateien gleichzeitig zu erhalten, übergeben Sie die Dateinamen in der Befehlszeile an stat:
stat ana.h ana.o

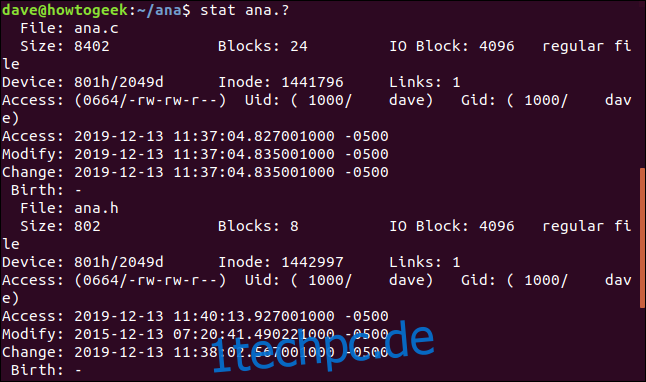
Um stat für eine Reihe von Dateien zu verwenden, verwenden Sie den Mustervergleich. Das Fragezeichen „?“ steht für ein beliebiges einzelnes Zeichen, und das Sternchen „*“ steht für eine beliebige Zeichenfolge. Mit diesem Befehl können wir stat anweisen, über jede Datei namens „ana“ mit einer einzelnen Buchstabenerweiterung zu berichten:
stat ana.?
Verwenden von stat zum Erstellen von Berichten über Dateisysteme
stat kann über den Status von Dateisystemen sowie den Status von Dateien berichten. Die Option -f (Dateisystem) weist stat an, über das Dateisystem zu berichten, auf dem sich die Datei befindet. Beachten Sie, dass wir anstelle eines Dateinamens auch ein Verzeichnis wie „/“ an stat übergeben können.
stat -f ana.c

Die Informationen, die uns die Statistik gibt, sind:
Datei: Der Name der Datei.
ID: Die Dateisystem-ID in hexadezimaler Schreibweise.
Namelen: Die maximal zulässige Länge für Dateinamen.
Typ: Der Typ des Dateisystems.
Blockgröße: Die Datenmenge, um Leseanforderungen für optimale Datenübertragungsraten anzufordern.
Grundlegende Blockgröße: Die Größe jedes Dateisystemblocks.
Blöcke:
Total: Die Gesamtzahl aller Blöcke im Dateisystem.
Free: Die Anzahl der freien Blöcke im Dateisystem.
Verfügbar: Die Anzahl der kostenlosen Blöcke, die regulären (Nicht-Root-)Benutzern zur Verfügung stehen.
Inoden:
Total: Die Gesamtzahl der Inodes im Dateisystem.
Free: Die Anzahl der freien Inodes im Dateisystem.
Dereferenzieren symbolischer Links
Wenn Sie stat für eine Datei verwenden, die eigentlich ein symbolischer Link ist, wird der Link gemeldet. Wenn Sie möchten, dass stat über die Datei berichtet, auf die der Link verweist, verwenden Sie die Option -L (Dereferenzierung). Die Datei code.c ist ein symbolischer Link zu ana.c . Sehen wir es uns ohne die Option -L an:
stat code.c

Der Dateiname zeigt code.c, der auf ( -> ) ana.c zeigt. Die Dateigröße beträgt nur 11 Byte. Es gibt null Blöcke, die dem Speichern dieses Links gewidmet sind. Der Dateityp wird als symbolischer Link aufgeführt.
Offensichtlich betrachten wir hier nicht die eigentliche Datei. Machen wir das noch einmal und fügen die Option -L hinzu:
stat -L code.c

Dies zeigt nun die Dateidetails für die Datei an, auf die durch den symbolischen Link verwiesen wird. Beachten Sie jedoch, dass der Dateiname weiterhin als code.c angegeben wird. Dies ist der Name des Links, nicht die Zieldatei. Dies geschieht, weil dies der Name ist, den wir in der Befehlszeile an stat übergeben haben.
Der knappe Bericht
Die Option -t (kurz gefasst) bewirkt, dass stat eine komprimierte Zusammenfassung liefert:
stat -t ana.c

Es werden keine Hinweise gegeben. Um dies zu verstehen – bis Sie sich die Feldsequenz merken können – müssen Sie diese Ausgabe mit einer vollständigen Statistikausgabe referenzieren.
Benutzerdefinierte Ausgabeformate
Eine bessere Möglichkeit, einen anderen Datensatz von stat zu erhalten, besteht darin, ein benutzerdefiniertes Format zu verwenden. Es gibt eine lange Liste von Token, die als Formatsequenzen bezeichnet werden. Jedes davon repräsentiert ein Datenelement. Wählen Sie diejenigen aus, die Sie in die Ausgabe aufnehmen möchten, und erstellen Sie eine Formatzeichenfolge. Wenn wir stat aufrufen und ihm den Formatstring übergeben, enthält die Ausgabe nur die angeforderten Datenelemente.
Es gibt verschiedene Sätze von Formatsequenzen für Dateien und Dateisysteme. Die Liste für Dateien lautet:
%a: Die Zugriffsrechte in Oktal.
%A: Die Zugriffsrechte in menschenlesbarer Form (rwx).
%b: Die Anzahl der zugewiesenen Blöcke.
%B: Die Größe jedes Blocks in Byte.
%d: Die Gerätenummer in Dezimalform.
%D: Die Gerätenummer in Hex.
%f: Der Raw-Modus in Hex.
%F Der Dateityp.
%g: Die Gruppen-ID des Besitzers.
%G: Der Gruppenname des Besitzers.
%h: Die Anzahl der Hardlinks.
%i: Die Inode-Nummer.
%m: Der Mount-Punkt.
%n: Der Dateiname.
%N: Der Dateiname in Anführungszeichen, mit dereferenziertem Dateinamen, wenn es sich um einen symbolischen Link handelt.
%o: Hinweis zur optimalen E/A-Übertragungsgröße.
%s: Die Gesamtgröße in Byte.
%t: Der Hauptgerätetyp in Hex, für spezielle Gerätedateien mit Zeichen/Block.
%T: Der untergeordnete Gerätetyp in Hex, für spezielle Gerätedateien für Zeichen-/Blockgeräte.
%u: Die Benutzer-ID des Besitzers.
%U: Der Benutzername des Besitzers.
%w: Die Geburtszeit der Datei, für Menschen lesbar oder ein Bindestrich „-“, falls unbekannt.
%W: Der Zeitpunkt der Dateigeburt, Sekunden seit der Epoche; 0 wenn unbekannt.
%x: Der Zeitpunkt des letzten Zugriffs, für Menschen lesbar.
%X: Die Zeit des letzten Zugriffs, Sekunden seit der Epoche.
%y: Der Zeitpunkt der letzten Datenänderung, für Menschen lesbar.
%Y: Die Zeit der letzten Datenänderung, Sekunden seit der Epoche.
%z: Der Zeitpunkt der letzten Statusänderung, für Menschen lesbar.
%Z: Der Zeitpunkt der letzten Statusänderung, Sekunden seit der Epoche.
Die „Epoche“ ist die Unix-Epoche, das am 01.01.1970 00:00:00 +0000 (UTC) stattfand.
Für Dateisysteme sind die Formatfolgen:
%a: Die Anzahl der kostenlosen Blöcke, die normalen (Nicht-Root-)Benutzern zur Verfügung stehen.
%b: Die Gesamtzahl der Datenblöcke im Dateisystem.
%c: Die Gesamtzahl der Inodes im Dateisystem.
%d: Die Anzahl der freien Inodes im Dateisystem.
%f: Die Anzahl der freien Blöcke im Dateisystem.
%i: Die Dateisystem-ID in hexadezimaler Form.
%l: Die maximale Länge von Dateinamen.
%n: Der Dateiname.
%s: Die Blockgröße (die optimale Schreibgröße).
%S: Die Größe der Dateisystemblöcke (für die Blockanzahl).
%t: Der Dateisystemtyp in hexadezimaler Form.
%T: Dateisystemtyp in menschenlesbarer Form.
Es gibt zwei Optionen, die Zeichenfolgen von Formatsequenzen akzeptieren. Dies sind –format und –printf. Der Unterschied zwischen ihnen ist –printf interpretiert Escape-Sequenzen im C-Stil wie newline n und tab t , und fügt seiner Ausgabe nicht automatisch ein Newline-Zeichen hinzu.
Lassen Sie uns eine Formatzeichenfolge erstellen und an stat übergeben. Die zu verwendenden Formatsequenzen sind %n für den Dateinamen, %s für die Größe der Datei und %F für den Dateityp. Wir werden die Escape-Sequenz n am Ende des Strings hinzufügen, um sicherzustellen, dass jede Datei in einer neuen Zeile behandelt wird. Unser Formatstring sieht so aus:
"File %n is %s bytes, and is a %Fn"
Wir übergeben dies mit der Option –printf an stat. Wir werden stat bitten, über eine Datei namens code.c und eine Reihe von Dateien, die mit ana.? übereinstimmen, zu berichten. Dies ist der vollständige Befehl. Beachten Sie das Gleichheitszeichen „=“ zwischen –printf und dem Formatstring:
stat --printf="File %n is %s bytes, and is a %Fn" code.c ana/ana.?
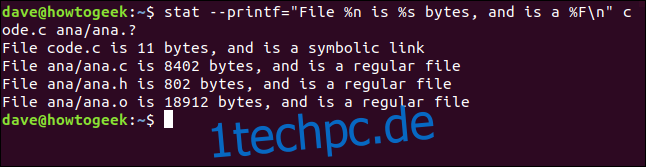
Der Bericht für jede Datei wird in einer neuen Zeile aufgeführt, was wir angefordert haben. Der Dateiname, die Dateigröße und der Dateityp werden uns zur Verfügung gestellt.
Benutzerdefinierte Formate ermöglichen Ihnen den Zugriff auf noch mehr Datenelemente, als in der standardmäßigen Statistikausgabe enthalten sind.
Feinkornkontrolle
Wie Sie sehen, gibt es enorme Möglichkeiten, die für Sie interessanten Datenelemente zu extrahieren. Sie können wahrscheinlich auch sehen, warum wir die Verwendung von Aliasnamen für die längeren und komplexeren Beschwörungen empfohlen haben.