

Ein Disaster-Recovery-Plan ist eine der wichtigsten Maßnahmen, die eine Organisation haben muss, bevor sie von einem ungewöhnlichen Ereignis getroffen wird.
In der IT-Branche beginnt es mit der Erstellung eines formellen Dokuments, das Pläne, Maßnahmen und Verfahren zum Umgang mit der Katastrophe und ihren Nachwirkungen enthält.
Eine Katastrophe ist ein Ereignis, das plötzlich ohne Vorankündigung eintritt und unterschiedlicher Art sein kann. Und wenn es landet, stehen Einzelpersonen und Organisationen vor vielen Arten von Schwierigkeiten, einschließlich finanzieller Probleme und Benutzererfahrung.
Wenn es zu einem Angriff kommt, müssen Sie bereit sein, seine Auswirkungen zu minimieren und Ihren Betrieb schneller wiederherzustellen. An dieser Stelle hilft Ihnen die Erstellung eines praktischen Disaster-Recovery-Plans dabei, die Katastrophe zurückzuhalten oder zu verhindern. Sie können auch die Nachwirkungen in Bezug auf Benutzererfahrung, Kosten und Ausfallzeiten reduzieren.
Darüber hinaus müssen Sie Ihre Pläne, Mitarbeiter, Strategien, Ausrüstung und Systeme bereit halten, um alles wieder in Gang zu bringen. Aber dazu müssen Sie Disaster Recovery im Detail verstehen.
In diesem Artikel werde ich dies zusammen mit den wichtigsten Disaster-Recovery-Terminologien im Detail besprechen, damit Sie sich mutig wehren und unter solch widrigen Bedingungen gestärkt daraus hervorgehen können.
Lass uns anfangen!
Inhaltsverzeichnis
Was ist eine Katastrophe?
Eine Katastrophe ist ein unvorhergesehenes Ereignis, das überall passieren kann, auch in der IT-Branche. Es tritt entweder natürlich oder durch Menschen auf und kann den Betrieb eines Unternehmens stören und das Gefüge der Infrastruktur stören.
Infolgedessen sind eine Organisation und ihre Kunden, Lieferanten, Mitarbeiter und Partner betroffen. Es übt Druck auf die Organisation in Bezug auf Finanzen, Branchenruf, Kundenvertrauen und Sicherheitsperimeter aus.
Daher müssen Sie im Voraus bereit sein, ein solches Szenario zu bewältigen. Dazu müssen Sie alle Vorgänge und Daten sofort wiederherstellen. Mit einfachen Worten, Sie müssen Ihre Organisation darauf vorbereiten, alles in kürzester Zeit für Ihre Kunden wiederherzustellen.
Es gibt viele Arten von Katastrophen, wie z. B. Cyberangriffe, Sabotage, Terroranschläge, Ransomware oder physische Bedrohungen, Wirbelstürme, Erdbeben, Brände, Überschwemmungen, Industrieunfälle, Stromausfälle und vieles mehr.
Was meinen Sie mit Notfallwiederherstellung?

Disaster Recovery ist der Prozess der Wiederherstellung des normalen Betriebs nach einer Katastrophe. Es beinhaltet die Wiederaufnahme des Zugriffs auf Hardware, Software, Geräte, Konnektivität, Netzwerke, Strom und Daten. Sie müssen Regeln und Verfahren in einem dokumentierten Prozess festlegen, um Ihr Unternehmen auf eine Katastrophe vorzubereiten.
Wenn jedoch die Einrichtungen Ihrer Organisation zerstört werden, müssen Sie einige der Aktivitäten erweitern, indem Sie an Kommunikation, Transport, Beschaffung, Arbeitsorten und mehr arbeiten.
Warum ist ein Notfallwiederherstellungsplan wichtig?
Die Ausarbeitung eines perfekten Plans zur Wiederherstellung nach einer natürlichen oder von Menschen verursachten Katastrophe ist für jede IT-Branche von entscheidender Bedeutung. Stellen Sie sicher, dass Sie den richtigen Mitarbeiter und die richtigen Tools am richtigen Ort haben, um den Plan reibungslos umzusetzen.
Lassen Sie uns näher darauf eingehen, warum Disaster Recovery so wichtig ist.
Schäden begrenzen
Eine Katastrophe ist nicht vorhersehbar. Niemand weiß, wann es kommt und geht. Sie bereiten sich jedoch im Voraus darauf vor, den an Ihrer Infrastruktur verursachten Schaden zu kontrollieren.
In hochwassergefährdeten Gebieten können Sie beispielsweise Ihre wichtigsten Dokumente und Geräte im obersten Stockwerk ablegen, um Schäden zu vermeiden.
Sichern Sie auf ähnliche Weise Ihre wichtigen Daten, bevor Cyberangriffe Daten verletzen oder stehlen können.
Wiederherstellen von Diensten
Wenn Sie einen soliden Plan für die Wiederherstellung nach der Katastrophe erstellen, ist die Wiederherstellung aller Dienste in ihrer normalen Form schnell und einfach. Das bedeutet, dass Sie in kurzer Zeit fast alle wichtigen Vermögenswerte und Dienste wiederherstellen können.
Unterbrechung minimieren
Sie können nicht wissen, was morgen oder im nächsten Schritt einer Operation passieren wird. Aber mit einem perfekten Wiederherstellungsplan müssen Sie sich nicht viele Gedanken über die Folgen machen. Ihre Infrastruktur kann den Betrieb mit minimaler Unterbrechung fortsetzen.
Training und Vorbereitung

Eine IT-Infrastruktur besteht aus vielen Mitarbeitern, die unter einem Dach arbeiten. Alle müssen über die Wiederherstellung Bescheid wissen, um im Notfall sofort wie erforderlich und erwartet handeln zu können.
Die richtige Vorbereitung senkt auch den Stresspegel aller Personen, die mit Ihrer Organisation in Verbindung stehen. Darüber hinaus können Sie Ihre Mitarbeiter schulen, um die erforderlichen Maßnahmen zu ergreifen, wenn ein unerwartetes Ereignis eintritt.
Disaster-Recovery-Terminologien
Beginnen wir mit den Terminologien, um Disaster Recovery genauer zu verstehen.
RTO
Recovery Time Objective (RTO) ist die Zeitspanne, die eine Organisation entsprechend der Art des Geschäfts festlegt, um eine Katastrophe zu tolerieren, ohne das finanzielle Wachstum zu beeinträchtigen.
Beim Festlegen der RTO muss ein Unternehmen die Ausfallzeiten prüfen, die Ihr Unternehmen in vielerlei Hinsicht beeinträchtigen können. Es wird verwendet, um praktikable Strategien zu untersuchen, um Ihren Geschäftsbetrieb auch nach einer Katastrophe fortzusetzen. Wenn Kunden mit Störungen in der Anwendung konfrontiert werden, fragen sie, wie viel Zeit eine App braucht, um wieder aktiv zu werden. Die Antwort ist RTO für jede Organisation.
Beispiel: Angenommen, Sie sind ein Online-Transaktionsunternehmen wie PayPal oder Pioneer, das unvorhersehbaren Ereignissen gegenübersteht. In diesem Fall ist Ihr RTO schnell genug, um den Vorgang wiederherzustellen.
Mit anderen Worten, ein Unternehmen legt seine RTO auf ein oder zwei Stunden fest, um Konsequenzen in Form von Finanzen oder Daten zu vermeiden.
RPO
Recovery Point Objectives (RPO) ist der Datenverlust, den eine IT-Infrastruktur in Bezug auf Zeit und Menge an Informationen bewältigen kann.
Verwirrend?
Nehmen Sie ein Beispiel für eine Datenbank, die Transaktionen einer Bank aufzeichnet, einschließlich Überweisungen, Terminplanung, Zahlungen und mehr. Wenn ein Notfall eintritt, wird die Datenbank in Echtzeit wiederhergestellt. Die Differenz zwischen der Datenbank zum Zeitpunkt des Desasters und der Datenbankwiederherstellung nach einem Desaster ist in diesem Fall Null.
Für einige Unternehmen ist es akzeptabel, dass es etwa 24 Stunden dauert, um alle Informationen aus dem Backup wiederherzustellen, aber es kann manchmal katastrophal sein. Es ist wichtig, dass Sie Ihre Infrastruktur gemäß den RPO-Anforderungen einrichten. Dazu gehören die Erhöhung der Häufigkeit der Sicherungen, das Hinzufügen einer Standby-Datenbank zu Ihrer Architektur und vieles mehr.
Ausfallsicherung
Stellen Sie sich eine Situation vor, in der Sie eine lange Strecke zurücklegen. Plötzlich haben Sie aus unerwarteten Gründen einen platten Reifen. Sie danken dem in Ihrem Fahrzeug vorhandenen Ersatzreifen und dem Werkzeug zum Wechseln des defekten Reifens.
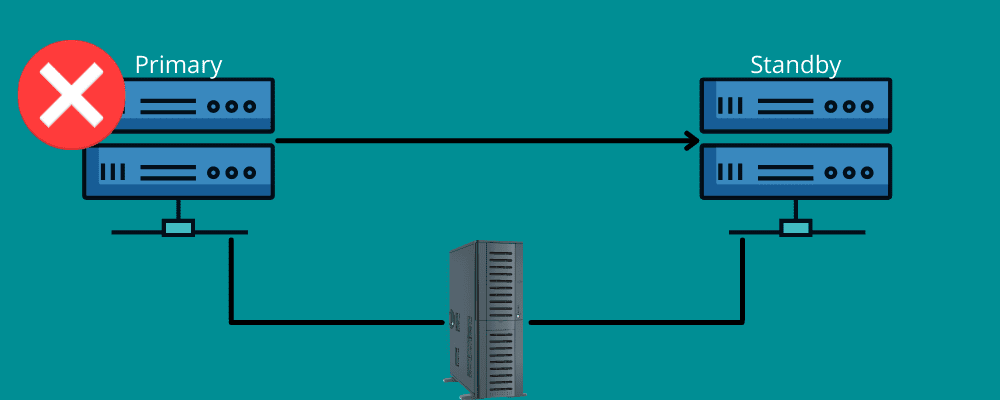
Failover funktioniert auf die gleiche Weise.
Das bedeutet, dass Sie während der Katastrophe eine Backup-Verbindung benötigen. Kurz gesagt bedeutet Failover, dass Sie über Netzwerke und Systeme verfügen, die Sie zum Zeitpunkt einer Katastrophe verwenden können, um Ihre Informationen auf das Wiederherstellungssystem zu übertragen.
Failover stellt sicher, dass alle Ihre Dienste reibungslos laufen, selbst wenn es zu Infrastruktur- oder Hardwareausfällen kommt. Auf diese Weise können Sie verhindern, dass Ihr Unternehmen Daten und Einnahmen verliert, und Serviceunterbrechungen für Ihre Endbenutzer vermeiden.
Sie können es entweder manuell einstellen oder es automatisch funktionieren lassen, um die Daten auf den Standby-Server zu verschieben.
Rückfall
IT-Failback ist ein einfacher Vorgang, bei dem die ursprüngliche Produktion nach der Bewältigung einer Katastrophe an ihren ursprünglichen Ort (System) zurückkehrt. Während des Angriffs folgen Unternehmen einem Failover-Vorgang, bei dem alle Workloads auf ein VM-Replikat oder Backup-System übertragen werden.
Sie können den nächsten Schritt der Rückkehr jedoch nicht einfach überspringen. Wenn Sie alles wiederherstellen und wieder in Aktion treten, müssen Sie alle Workloads auf ihre ursprünglichen VMs oder Systeme übertragen. Dieser Gesamtprozess der Rückgabe der Workloads an den ursprünglichen Arbeitsplatz oder das ursprüngliche System wird als Failback bezeichnet. Es bedeutet, dass Sie nach dem Angriff „zurückkommen“.
Failback wird auch für die geplante Wartung eines Unternehmens verwendet. Es stimmt, dass Failback immer nach Failover erfolgt. Mit anderen Worten, Failover ist der erste Schritt und Failback ist der zweite Schritt bei der Wiederherstellung wichtiger Daten. Es kann zwischen Cloud zu Cloud, On-Premises zu On-Premises, On-Premises zu Cloud oder einer beliebigen Kombination daraus eingerichtet werden.
DR
Disaster Recovery (DR) ist der Prozess, bei dem Sie vorgefertigte Pläne haben, um Ihre Assets innerhalb des Zeitrahmens wiederherzustellen.
DR gibt einem Unternehmen die Möglichkeit, schnell zu reagieren und jeden einzelnen Dienst nach einem unerwarteten Ereignis wiederherzustellen. Es enthält auch eine formelle Dokumentation, die Anweisungen zum Ergreifen von Sofortmaßnahmen bei unvorhergesehenen Vorfällen enthält.
BCP
Business Continuity Plan (BCP) ist einer der akzeptabelsten Disaster-Recovery-Pläne, der es der IT-Infrastruktur ermöglicht, Strategien zu entwickeln, um IT-Unterbrechungen von Servern, mobilen Geräten, PCs und Netzwerken zu bewältigen.
BCP unterscheidet sich geringfügig von Disaster Recovery, da es einem Unternehmen dabei hilft, Pläne zur Wiederherstellung von Unternehmenssoftware und Produktivität zu erstellen, um wichtige Geschäftsanforderungen zu erfüllen.
Hier erstellt ein Unternehmen ein Wiederherstellungssystem, um potenzielle Bedrohungen wie Cyberangriffe oder Naturkatastrophen zu überwinden. Es soll Vermögenswerte sichern und sicherstellen, dass alle Dienste nach dem Streik schnell wieder einsatzbereit sind.
BCM

Business Continuity Management (BCM) ist ein Risikomanagementprozess, der speziell darauf ausgelegt ist, als Schutzschild gegen Bedrohungen von Geschäftsprozessen zu fungieren. BCM ist der nächste Schritt von BCP, bei dem die Wiederherstellungspläne validiert werden, um sicherzustellen, dass jeder im Unternehmen sofort auf den Plan reagiert und alle wesentlichen Daten wiederherstellt.
BCM fungiert als Management-Framework, um Infrastrukturrisiken zu identifizieren, wenn es externen und/oder internen Bedrohungen ausgesetzt ist. Es stellt auch sicher, dass das Framework mithilfe regelmäßiger Tests effizient funktioniert, um die Vorhersagbarkeit zu verbessern, Risiken zu reduzieren und den Plan für zukünftige Angriffe auszurichten.
BIA
Business Impact Analysis (BIA) ist der Prozess der Analyse der Überlebensrate eines Unternehmens durch die Identifizierung wichtiger Systeme, Abläufe und Prozesse. Es beschreibt die Auswirkungen einer Katastrophe auf Ihr Unternehmen aufgrund der Unterbrechung Ihres Betriebs.
BIA sagt die Folgen voraus, bevor ein Angriff tatsächlich stattfindet, um wichtige Informationen zu sammeln, die bei der Entwicklung leistungsstarker Wiederherstellungsstrategien helfen können. Es identifiziert auch die Kosten, die durch die Ausfälle verursacht werden, wie z. B. Wiederbeschaffungskosten für Geräte, Verlust von Cashflow, Gewinn, Gehältern und mehr.
Bei der Erstellung eines BIA-Berichts müssen Sie die entscheidenden Prozesse Ihres Unternehmens, die Auswirkungen von Störungen auf verschiedene Bereiche, die akzeptable Dauer, tolerierbare Bereiche, die finanziellen Kosten und mehr berücksichtigen.
Baum anrufen
Ein Anrufbaum ist ein Prozess, bei dem eine Liste von Mitarbeitern erstellt wird, die während eines Notfalls angerufen werden können. Es ist ein Verfahren, das einer baumartigen Struktur folgt.
Beispielsweise wird während einer Katastrophe eine Person eine kleine Gruppe von Mitgliedern mit einer dringenden Nachricht kontaktieren, diese Mitarbeiter rufen jede Gruppe separat an. Auf diese Weise werden alle Mitarbeiter während der Bedrohung informiert und beginnen ihre zugewiesene Arbeit, um alle Funktionen und Prozesse rechtzeitig wiederherzustellen. Das Erstellen einer Liste ist einfach, aber die Implementierung in Echtzeit führt zu Verwirrung.
Sie müssen regelmäßige Anrufaktivitäten durchführen, um jeden Mitarbeiter des Notfallpersonals darauf vorzubereiten, wachsam zu bleiben. Regelmäßige Tests können auch dabei helfen, geänderte oder fehlende Zahlen zu identifizieren, die die Leistung stark beeinträchtigen können.
Ein Anrufbaum enthält Informationen, die während eines Notfalls verwendet werden, um Anweisungen zu liefern. Dies kann auch manuell erfolgen, aber die Menschen nutzen die Automatisierung, um den Prozess zu beschleunigen und die Mitglieder in der heutigen digitalen Welt zu benachrichtigen.
Kommandozentrale/Kontrollzentrum
Es handelt sich um eine virtuelle oder physische Einrichtung, die speziell darauf vorbereitet ist, während einer Krise die Befehle oder die Kontrolle über die Wiederherstellungspläne zu übernehmen. Es kommuniziert mit dem Team, um die Systeme und Funktionen während der Katastrophe zu verwalten.
Traditionell hängt die Infrastruktur von der Kommandozentrale ab, die Krisen ohne einen angemessenen Ansatz bewältigt. Heutzutage haben Organisationen ihre Schaltzentrale perfekt gestaltet, wodurch die unmittelbare Reaktion zur Kernkompetenz wird.
Sobald eine Katastrophe erkannt wird, steuert die Kommandozentrale schnell auf die Wiederherstellungsphase zu. Außerdem dient es als Meldestelle bei Serviceleistungen, Presse, Lieferungen und mehr. Es bringt auch Menschen aus mehreren Disziplinen in solchen Szenarien zusammen.
Reaktion auf Vorfälle

Incident Response ist eine Art Reaktion auf einen Angriff. Dies geschieht mit Hilfe der richtigen Verfahren und des richtigen Personals, um die Netzwerk- und Datensicherheit zum richtigen Zeitpunkt effektiv zu gewährleisten.
Wenn ein Unternehmen vor dem unerwarteten Ereignis einen Vorfallplan hat, kann es seine Daten in Echtzeit vor Bedrohungen schützen. Die Incident-Response-Spezialisten bleiben immer wachsam gegenüber den Problemen und handeln während eines Vorfalls natürlich. Sie ergreifen bestimmte Maßnahmen, um Sicherheitsverletzungen zu vermeiden, und stellen sicher, dass sie während der Notfallwiederherstellung keinen einzigen Schritt überspringen.
Zu Beginn müssen Sie die kritischen Daten bestimmen und in der Cloud oder an einem entfernten Ort speichern, um die Sicherheit zu gewährleisten. Reagieren Sie auf aktuelle Infrastrukturanforderungen und sich entwickelnde Cyber-Bedrohungen, indem Sie die Reaktionspläne für Vorfälle regelmäßig aktualisieren.
Sicherung
Backup-Lösungen helfen einer IT-Infrastruktur dabei, Kopien von Daten zu erhalten und zum richtigen Zeitpunkt sicher zu speichern. Wenn Sie mit einer Datenbankbeschädigung, versehentlichem Löschen aller Daten oder einem anderen Problem konfrontiert werden, müssen Sie mit dem Backup bereit sein, um die Daten sofort wiederherzustellen und mit den Diensten weiterzumachen.

Dabei werden die Dateien repliziert und an einem sicheren Ort gespeichert, um nach einem ungewöhnlichen Ereignis problemlos auf alle Daten zugreifen zu können. Es ist hilfreich, wenn Sie Ihre Daten an mehreren Orten sichern, um sicherzustellen, dass Sie sie auch dann wiederherstellen können, wenn eine Website ausfällt.
Widerstandsfähigkeit
Die Fähigkeit von Gemeinschaften, Staaten, Organisationen und Einzelpersonen, einer Katastrophe zu widerstehen oder zu widerstehen, ohne die Dienste und Systeme zu gefährden, wird als Katastrophenresilienz bezeichnet.
Eine Organisation muss bereit sein, eine große Menge an Stress aufgrund der Gefahren zurückzuhalten. Stellen Sie sicher, dass Sie in der Lage sind, Ihre Verluste durch eine bessere Planung zu minimieren, anstatt darauf zu warten, dass jemand kommt und Sie rettet. Dies hilft Ihnen, Katastrophen zu bewältigen und Ihre IT-Infrastruktur effizient wiederherzustellen.
Dabei geht es vor allem darum, die wesentlichen Funktionen und Strukturen zum richtigen Zeitpunkt zu erhalten und wiederherzustellen. Um eine katastrophenresistente Organisation zu werden, müssen Sie sich im Voraus vorbereiten und in der Lage sein, Risiken zu antizipieren, sich an Veränderungen anzupassen, zu teilen und zu lernen, verschiedene Sektoren zu integrieren und Risikoniveaus zu verwalten.
SLA

Service Level Agreement (SLA) ist ein Notfallplan, in dem Sie den Endbenutzern mitteilen, wie viel Zeit Sie für die Wiederherstellung von Diensten während eines Notfalls benötigen.
SLA garantiert Kunden, dass ihre Daten sicher sind und nicht kompromittiert oder an Dritte weitergegeben werden. Es ist die zentrale Anlaufstelle für die Probleme der Endbenutzer.
Jede IT-Infrastruktur gibt ihren Kunden Sicherheit über SLA. Stellen Sie also sicher, dass Sie vorher mit Ihren Endbenutzern kommunizieren.
SPOF
Ein Single Point of Failure (SPOF) ist ein Gerät, eine Person, eine Ressource oder eine Anwendung, mit der viele andere Systeme oder Anwendungen verbunden sind.
Wenn ein solches Gerät oder eine Ressource ausfällt, fallen alle wesentlichen Teile, die mit dem System verbunden sind, damit aus. Dadurch wird der gesamte Prozess und Geschäftsbetrieb beeinträchtigt.
Daher müssen Sie über eine Strategie verfügen, um mit einem solchen Problem umzugehen und Ihr Unternehmen am Laufen zu halten. Das allererste, was Sie tun können, ist, das einzelne Gerät oder System zu identifizieren, das größere Auswirkungen haben kann. Führen Sie als Nächstes eine Business-Impact-Analyse durch und erhalten Sie eine Risikobewertungspunktzahl, um sich der Szenen bewusst zu sein, die passieren werden. Graben Sie sich ein und finden Sie sie vor dem Ereignis.
Sobald Sie alle SPOF aufgelistet haben, klassifizieren Sie sie nach dem Wiederherstellungsprozess. Ordnen Sie jeden SPOF drei verschiedenen Kategorien zu:
- Einfache und direkte Wiederherstellung mit weniger Zeit und Budget.
- Die Wiederherstellung wäre schwierig, aber es könnte ein zuverlässiger Prozess zur Wiederherstellung entwickelt werden.
- Es kann nichts getan werden, um sich zu erholen, wenn es einmal ausfällt.
Je nach Kategorie können Sie entsprechend agieren.
Systemwiederherstellung
Während eines Hardwarefehlers müssen Sie einen Wiederherstellungsprozess ausführen, um das jeweilige System oder den Server in seiner ursprünglichen Form wiederherzustellen. Und um das gesamte System wiederherzustellen, müssen Sie mit Wiederherstellungsanforderungen, Backups, Firmware-Kompatibilität und Hardware-Kompatibilität gerüstet sein.
Die Systemwiederherstellung ist ein Prozess, der die Maschine auf ihre vorherigen Einstellungen oder den gleichen Zustand wie im Neuzustand zurücksetzt. Dadurch werden alle Virusinfektionen aufgrund installierter Software oder Anwendungen in Ihrem System gelöscht.
Dieser Prozess umfasst die Wiederherstellungsplanung einer IT-Infrastruktur, die bestimmte Verfahren festlegt und befolgt, um die Datenverfügbarkeit gegen von Menschen verursachte oder natürliche Störungen sicherzustellen.
Systemwiederherstellung
Die Systemwiederherstellung ist ein Wiederherstellungstool, mit dem Sie bestimmte Dateien und Informationen zum richtigen Zeitpunkt in ihren vorherigen Zustand zurückversetzen können.
Mit der Systemwiederherstellung können Sie Registrierungsschlüssel, installierte Programme, Treiber, Systemdateien und mehr auf die vorherige Version zurücksetzen. Dies ist bei vielen Katastrophen ein Lebensretter.
Versuchsplan
Es bezieht sich auf ein Dokument, in dem Informationen zu einer Teststrategie, Schätzungen, Ressourcen, Fristen, Zielen und Zeitplänen gespeichert sind. Es fungiert als Blaupause, die Tests durchführt, um die Sicherheit von Hardware und Software zu gewährleisten.
Dazu gehören verschiedene Tests gemäß den Verfahren und Schritten, die zur Bewältigung der Nachwirkungen von Katastrophen geplant sind. Führen Sie die regelmäßigen Tests durch, um sich und Ihre Organisation darauf vorzubereiten, keinen einzigen Schritt im Handlungsablauf zu überspringen. Auf diese Weise kann eine IT-Infrastruktur die Mängel erkennen und für den Kampf bereit sein.
Fazit
Niemand weiß, wann eine Katastrophe passieren wird. Daher sind angemessene Sicherheitsmaßnahmen für jedes Unternehmen unerlässlich.
Disaster Recovery-Terminologien helfen Ihnen zu verstehen, wie Sie auf Angriffe und Katastrophen reagieren können. Es hilft Ihnen auch, sich im Voraus vorzubereiten, damit Sie Ihre Infrastruktur bei einem unerwarteten Ereignis schützen können. Sie werden in der Lage sein, eine effektive Disaster-Recovery-Strategie in Echtzeit zu entwickeln, um Millionen von Dollar einzusparen und das Vertrauen der Kunden zu verlieren.